 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaFold: Adapting Folding Trajectories of Cloths via Feedback-loop Manipulation
Paper and Code
Mar 10, 2024
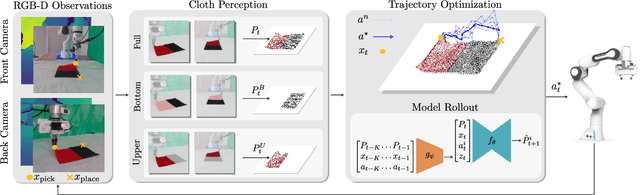

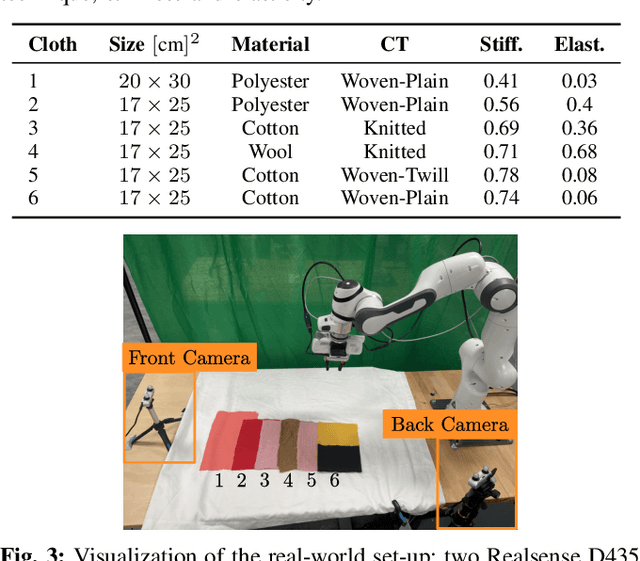
We present AdaFold, a model-based feedback-loop framework for optimizing folding trajectories. AdaFold extracts a particle-based representation of cloth from RGB-D images and feeds back the representation to a model predictive control to re-plan folding trajectory at every time-step. A key component of AdaFold that enables feedback-loop manipulation is the use of semantic descriptors extracted from visual-language models. These descriptors enhance the particle representation of the cloth to distinguish between ambiguous point clouds of differently folded cloths. Our experiments demonstrate AdaFold's ability to adapt folding trajectories to cloths with varying physical properties and generalize from simulated training to real-world execution.