 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReduced-order Control and Geometric Structure of Learned Lagrangian Latent Dynamics
Feb 09, 2026Model-based controllers can offer strong guarantees on stability and convergence by relying on physically accurate dynamic models. However, these are rarely available for high-dimensional mechanical systems such as deformable objects or soft robots. While neural architectures can learn to approximate complex dynamics, they are either limited to low-dimensional systems or provide only limited formal control guarantees due to a lack of embedded physical structure. This paper introduces a latent control framework based on learned structure-preserving reduced-order dynamics for high-dimensional Lagrangian systems. We derive a reduced tracking law for fully actuated systems and adopt a Riemannian perspective on projection-based model-order reduction to study the resulting latent and projected closed-loop dynamics. By quantifying the sources of modeling error, we derive interpretable conditions for stability and convergence. We extend the proposed controller and analysis to underactuated systems by introducing learned actuation patterns. Experimental results on simulated and real-world systems validate our theoretical investigation and the accuracy of our controllers.
PALM: Enhanced Generalizability for Local Visuomotor Policies via Perception Alignment
Jan 27, 2026Generalizing beyond the training domain in image-based behavior cloning remains challenging. Existing methods address individual axes of generalization, workspace shifts, viewpoint changes, and cross-embodiment transfer, yet they are typically developed in isolation and often rely on complex pipelines. We introduce PALM (Perception Alignment for Local Manipulation), which leverages the invariance of local action distributions between out-of-distribution (OOD) and demonstrated domains to address these OOD shifts concurrently, without additional input modalities, model changes, or data collection. PALM modularizes the manipulation policy into coarse global components and a local policy for fine-grained actions. We reduce the discrepancy between in-domain and OOD inputs at the local policy level by enforcing local visual focus and consistent proprioceptive representation, allowing the policy to retrieve invariant local actions under OOD conditions. Experiments show that PALM limits OOD performance drops to 8% in simulation and 24% in the real world, compared to 45% and 77% for baselines.
Real-Time Iteration Scheme for Diffusion Policy
Aug 07, 2025Diffusion Policies have demonstrated impressive performance in robotic manipulation tasks. However, their long inference time, resulting from an extensive iterative denoising process, and the need to execute an action chunk before the next prediction to maintain consistent actions limit their applicability to latency-critical tasks or simple tasks with a short cycle time. While recent methods explored distillation or alternative policy structures to accelerate inference, these often demand additional training, which can be resource-intensive for large robotic models. In this paper, we introduce a novel approach inspired by the Real-Time Iteration (RTI) Scheme, a method from optimal control that accelerates optimization by leveraging solutions from previous time steps as initial guesses for subsequent iterations. We explore the application of this scheme in diffusion inference and propose a scaling-based method to effectively handle discrete actions, such as grasping, in robotic manipulation. The proposed scheme significantly reduces runtime computational costs without the need for distillation or policy redesign. This enables a seamless integration into many pre-trained diffusion-based models, in particular, to resource-demanding large models. We also provide theoretical conditions for the contractivity which could be useful for estimating the initial denoising step. Quantitative results from extensive simulation experiments show a substantial reduction in inference time, with comparable overall performance compared with Diffusion Policy using full-step denoising. Our project page with additional resources is available at: https://rti-dp.github.io/.
Multimodal "Puppeteer": An Exploration of Robot Teleoperation Via Virtual Counterpart with LLM-Driven Voice and Gesture Interaction in Augmented Reality
Jun 16, 2025The integration of robotics and augmented reality (AR) holds transformative potential for advancing human-robot interaction (HRI), offering enhancements in usability, intuitiveness, accessibility, and collaborative task performance. This paper introduces and evaluates a novel multimodal AR-based robot puppeteer framework that enables intuitive teleoperation via virtual counterpart through large language model (LLM)-driven voice commands and hand gesture interactions. Utilizing the Meta Quest 3, users interact with a virtual counterpart robot in real-time, effectively "puppeteering" its physical counterpart within an AR environment. We conducted a within-subject user study with 42 participants performing robotic cube pick-and-place with pattern matching tasks under two conditions: gesture-only interaction and combined voice-and-gesture interaction. Both objective performance metrics and subjective user experience (UX) measures were assessed, including an extended comparative analysis between roboticists and non-roboticists. The results provide key insights into how multimodal input influences contextual task efficiency, usability, and user satisfaction in AR-based HRI. Our findings offer practical design implications for designing effective AR-enhanced HRI systems.
DLO-Splatting: Tracking Deformable Linear Objects Using 3D Gaussian Splatting
May 13, 2025This work presents DLO-Splatting, an algorithm for estimating the 3D shape of Deformable Linear Objects (DLOs) from multi-view RGB images and gripper state information through prediction-update filtering. The DLO-Splatting algorithm uses a position-based dynamics model with shape smoothness and rigidity dampening corrections to predict the object shape. Optimization with a 3D Gaussian Splatting-based rendering loss iteratively renders and refines the prediction to align it with the visual observations in the update step. Initial experiments demonstrate promising results in a knot tying scenario, which is challenging for existing vision-only methods.
FLoRA: Sample-Efficient Preference-based RL via Low-Rank Style Adaptation of Reward Functions
Apr 14, 2025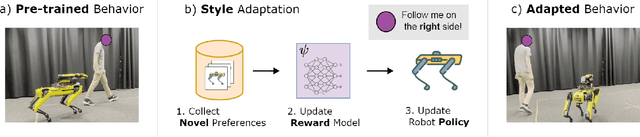
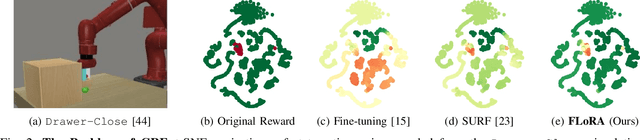
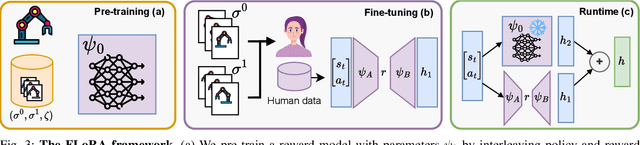
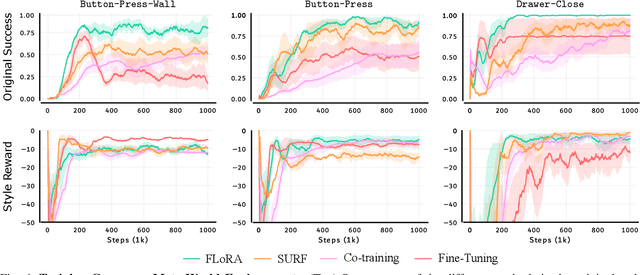
Preference-based reinforcement learning (PbRL) is a suitable approach for style adaptation of pre-trained robotic behavior: adapting the robot's policy to follow human user preferences while still being able to perform the original task. However, collecting preferences for the adaptation process in robotics is often challenging and time-consuming. In this work we explore the adaptation of pre-trained robots in the low-preference-data regime. We show that, in this regime, recent adaptation approaches suffer from catastrophic reward forgetting (CRF), where the updated reward model overfits to the new preferences, leading the agent to become unable to perform the original task. To mitigate CRF, we propose to enhance the original reward model with a small number of parameters (low-rank matrices) responsible for modeling the preference adaptation. Our evaluation shows that our method can efficiently and effectively adjust robotic behavior to human preferences across simulation benchmark tasks and multiple real-world robotic tasks.
Grasping a Handful: Sequential Multi-Object Dexterous Grasp Generation
Mar 31, 2025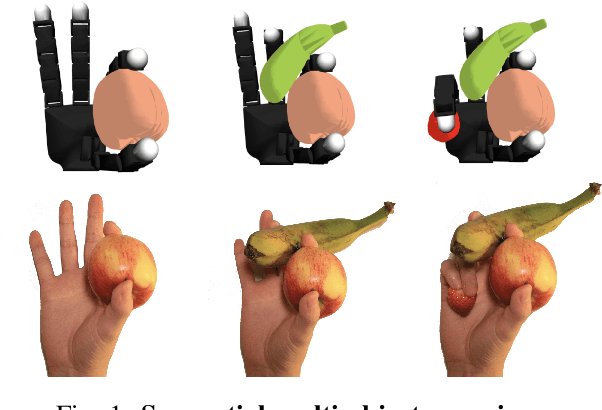

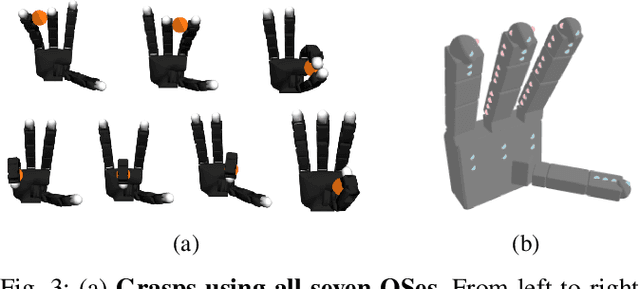
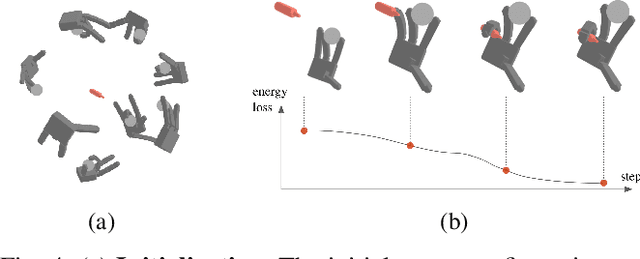
We introduce the sequential multi-object robotic grasp sampling algorithm SeqGrasp that can robustly synthesize stable grasps on diverse objects using the robotic hand's partial Degrees of Freedom (DoF). We use SeqGrasp to construct the large-scale Allegro Hand sequential grasping dataset SeqDataset and use it for training the diffusion-based sequential grasp generator SeqDiffuser. We experimentally evaluate SeqGrasp and SeqDiffuser against the state-of-the-art non-sequential multi-object grasp generation method MultiGrasp in simulation and on a real robot. The experimental results demonstrate that SeqGrasp and SeqDiffuser reach an 8.71%-43.33% higher grasp success rate than MultiGrasp. Furthermore, SeqDiffuser is approximately 1000 times faster at generating grasps than SeqGrasp and MultiGrasp.
Pushing Everything Everywhere All At Once: Probabilistic Prehensile Pushing
Mar 18, 2025We address prehensile pushing, the problem of manipulating a grasped object by pushing against the environment. Our solution is an efficient nonlinear trajectory optimization problem relaxed from an exact mixed integer non-linear trajectory optimization formulation. The critical insight is recasting the external pushers (environment) as a discrete probability distribution instead of binary variables and minimizing the entropy of the distribution. The probabilistic reformulation allows all pushers to be used simultaneously, but at the optimum, the probability mass concentrates onto one due to the entropy minimization. We numerically compare our method against a state-of-the-art sampling-based baseline on a prehensile pushing task. The results demonstrate that our method finds trajectories 8 times faster and at a 20 times lower cost than the baseline. Finally, we demonstrate that a simulated and real Franka Panda robot can successfully manipulate different objects following the trajectories proposed by our method. Supplementary materials are available at https://probabilistic-prehensile-pushing.github.io/.
Learning Dexterous In-Hand Manipulation with Multifingered Hands via Visuomotor Diffusion
Mar 04, 2025We present a framework for learning dexterous in-hand manipulation with multifingered hands using visuomotor diffusion policies. Our system enables complex in-hand manipulation tasks, such as unscrewing a bottle lid with one hand, by leveraging a fast and responsive teleoperation setup for the four-fingered Allegro Hand. We collect high-quality expert demonstrations using an augmented reality (AR) interface that tracks hand movements and applies inverse kinematics and motion retargeting for precise control. The AR headset provides real-time visualization, while gesture controls streamline teleoperation. To enhance policy learning, we introduce a novel demonstration outlier removal approach based on HDBSCAN clustering and the Global-Local Outlier Score from Hierarchies (GLOSH) algorithm, effectively filtering out low-quality demonstrations that could degrade performance. We evaluate our approach extensively in real-world settings and provide all experimental videos on the project website: https://dex-manip.github.io/
FLAME: A Federated Learning Benchmark for Robotic Manipulation
Mar 03, 2025Recent progress in robotic manipulation has been fueled by large-scale datasets collected across diverse environments. Training robotic manipulation policies on these datasets is traditionally performed in a centralized manner, raising concerns regarding scalability, adaptability, and data privacy. While federated learning enables decentralized, privacy-preserving training, its application to robotic manipulation remains largely unexplored. We introduce FLAME (Federated Learning Across Manipulation Environments), the first benchmark designed for federated learning in robotic manipulation. FLAME consists of: (i) a set of large-scale datasets of over 160,000 expert demonstrations of multiple manipulation tasks, collected across a wide range of simulated environments; (ii) a training and evaluation framework for robotic policy learning in a federated setting. We evaluate standard federated learning algorithms in FLAME, showing their potential for distributed policy learning and highlighting key challenges. Our benchmark establishes a foundation for scalable, adaptive, and privacy-aware robotic learning.