 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe First WARA Robotics Mobile Manipulation Challenge -- Lessons Learned
May 11, 2025The first WARA Robotics Mobile Manipulation Challenge, held in December 2024 at ABB Corporate Research in V\"aster{\aa}s, Sweden, addressed the automation of task-intensive and repetitive manual labor in laboratory environments - specifically the transport and cleaning of glassware. Designed in collaboration with AstraZeneca, the challenge invited academic teams to develop autonomous robotic systems capable of navigating human-populated lab spaces and performing complex manipulation tasks, such as loading items into industrial dishwashers. This paper presents an overview of the challenge setup, its industrial motivation, and the four distinct approaches proposed by the participating teams. We summarize lessons learned from this edition and propose improvements in design to enable a more effective second iteration to take place in 2025. The initiative bridges an important gap in effective academia-industry collaboration within the domain of autonomous mobile manipulation systems by promoting the development and deployment of applied robotic solutions in real-world laboratory contexts.
FLoRA: Sample-Efficient Preference-based RL via Low-Rank Style Adaptation of Reward Functions
Apr 14, 2025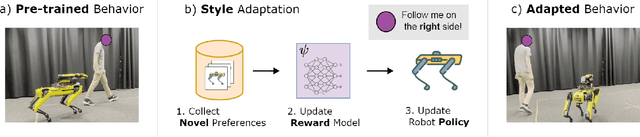
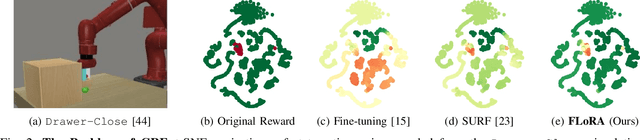
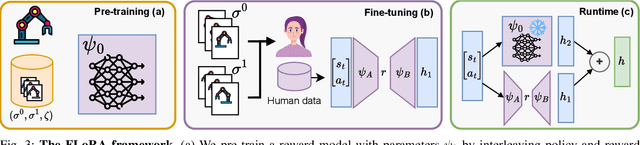
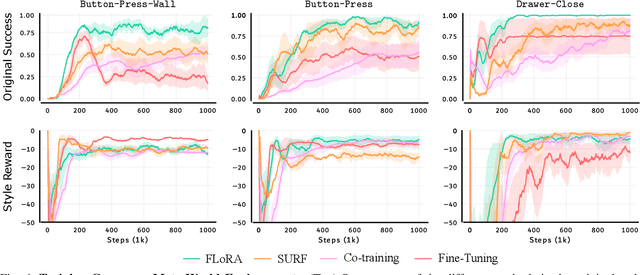
Preference-based reinforcement learning (PbRL) is a suitable approach for style adaptation of pre-trained robotic behavior: adapting the robot's policy to follow human user preferences while still being able to perform the original task. However, collecting preferences for the adaptation process in robotics is often challenging and time-consuming. In this work we explore the adaptation of pre-trained robots in the low-preference-data regime. We show that, in this regime, recent adaptation approaches suffer from catastrophic reward forgetting (CRF), where the updated reward model overfits to the new preferences, leading the agent to become unable to perform the original task. To mitigate CRF, we propose to enhance the original reward model with a small number of parameters (low-rank matrices) responsible for modeling the preference adaptation. Our evaluation shows that our method can efficiently and effectively adjust robotic behavior to human preferences across simulation benchmark tasks and multiple real-world robotic tasks.