 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLoRA: Sample-Efficient Preference-based RL via Low-Rank Style Adaptation of Reward Functions
Apr 14, 2025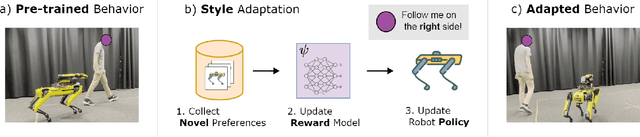
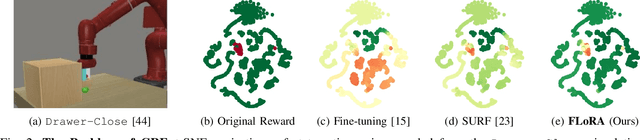
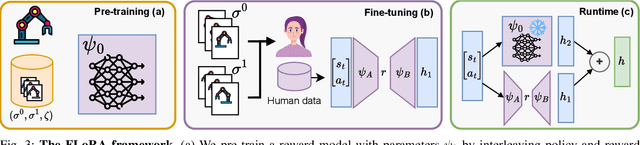
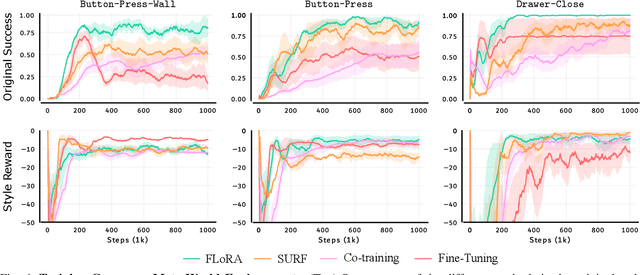
Preference-based reinforcement learning (PbRL) is a suitable approach for style adaptation of pre-trained robotic behavior: adapting the robot's policy to follow human user preferences while still being able to perform the original task. However, collecting preferences for the adaptation process in robotics is often challenging and time-consuming. In this work we explore the adaptation of pre-trained robots in the low-preference-data regime. We show that, in this regime, recent adaptation approaches suffer from catastrophic reward forgetting (CRF), where the updated reward model overfits to the new preferences, leading the agent to become unable to perform the original task. To mitigate CRF, we propose to enhance the original reward model with a small number of parameters (low-rank matrices) responsible for modeling the preference adaptation. Our evaluation shows that our method can efficiently and effectively adjust robotic behavior to human preferences across simulation benchmark tasks and multiple real-world robotic tasks.
PREDILECT: Preferences Delineated with Zero-Shot Language-based Reasoning in Reinforcement Learning
Feb 23, 2024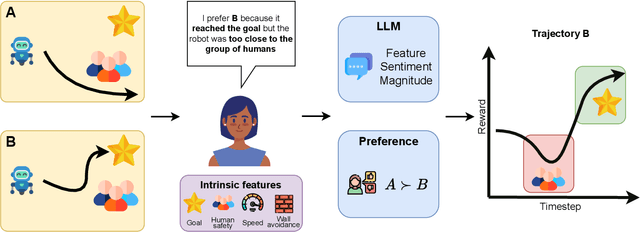



Preference-based reinforcement learning (RL) has emerged as a new field in robot learning, where humans play a pivotal role in shaping robot behavior by expressing preferences on different sequences of state-action pairs. However, formulating realistic policies for robots demands responses from humans to an extensive array of queries. In this work, we approach the sample-efficiency challenge by expanding the information collected per query to contain both preferences and optional text prompting. To accomplish this, we leverage the zero-shot capabilities of a large language model (LLM) to reason from the text provided by humans. To accommodate the additional query information, we reformulate the reward learning objectives to contain flexible highlights -- state-action pairs that contain relatively high information and are related to the features processed in a zero-shot fashion from a pretrained LLM. In both a simulated scenario and a user study, we reveal the effectiveness of our work by analyzing the feedback and its implications. Additionally, the collective feedback collected serves to train a robot on socially compliant trajectories in a simulated social navigation landscape. We provide video examples of the trained policies at https://sites.google.com/view/rl-predilect