 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection and Recognition: A Pairwise Interaction Framework for Mobile Service Robots
Feb 25, 2026Autonomous mobile service robots, like lawnmowers or cleaning robots, operating in human-populated environments need to reason about local human-human interactions to support safe and socially aware navigation while fulfilling their tasks. For such robots, interaction understanding is not primarily a fine-grained recognition problem, but a perception problem under limited sensing quality and computational resources. Many existing approaches focus on holistic group activity recognition, which often requires complex and large models which may not be necessary for mobile service robots. Others use pairwise interaction methods which commonly rely on skeletal representations but their use in outdoor environments remains challenging. In this work, we argue that pairwise human interaction constitute a minimal yet sufficient perceptual unit for robot-centric social understanding. We study the problem of identifying interacting person pairs and classifying coarse-grained interaction behaviors sufficient for downstream group-level reasoning and service robot decision-making. To this end, we adopt a two-stage framework in which candidate interacting pairs are first identified based on lightweight geometric and motion cues, and interaction types are subsequently classified using a relation network. We evaluate the proposed approach on the JRDB dataset, where it achieves sufficient accuracy with reduced computational cost and model size compared to appearance-based methods. Additional experiments on the Collective Activity Dataset and zero shot test on a lawnmower-collected dataset further illustrate the generality of the proposed framework. These results suggest that pairwise geometric and motion cues provide a practical basis for interaction perception on mobile service robot providing a promising method for integration into mobile robot navigation stacks in future work. Code will be released soon
FLoRA: Sample-Efficient Preference-based RL via Low-Rank Style Adaptation of Reward Functions
Apr 14, 2025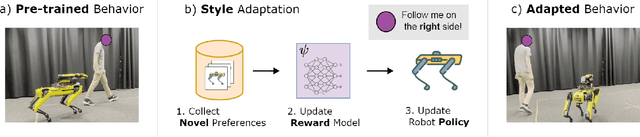
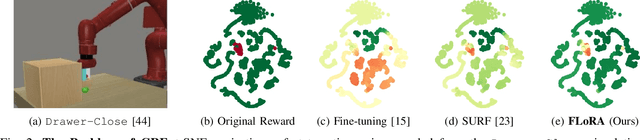
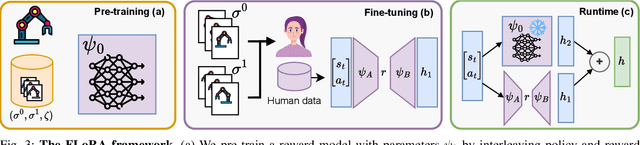
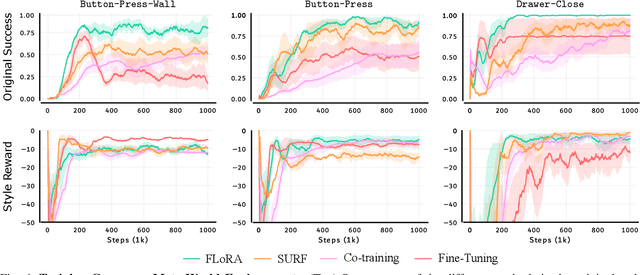
Preference-based reinforcement learning (PbRL) is a suitable approach for style adaptation of pre-trained robotic behavior: adapting the robot's policy to follow human user preferences while still being able to perform the original task. However, collecting preferences for the adaptation process in robotics is often challenging and time-consuming. In this work we explore the adaptation of pre-trained robots in the low-preference-data regime. We show that, in this regime, recent adaptation approaches suffer from catastrophic reward forgetting (CRF), where the updated reward model overfits to the new preferences, leading the agent to become unable to perform the original task. To mitigate CRF, we propose to enhance the original reward model with a small number of parameters (low-rank matrices) responsible for modeling the preference adaptation. Our evaluation shows that our method can efficiently and effectively adjust robotic behavior to human preferences across simulation benchmark tasks and multiple real-world robotic tasks.
Expectations, Explanations, and Embodiment: Attempts at Robot Failure Recovery
Apr 09, 2025
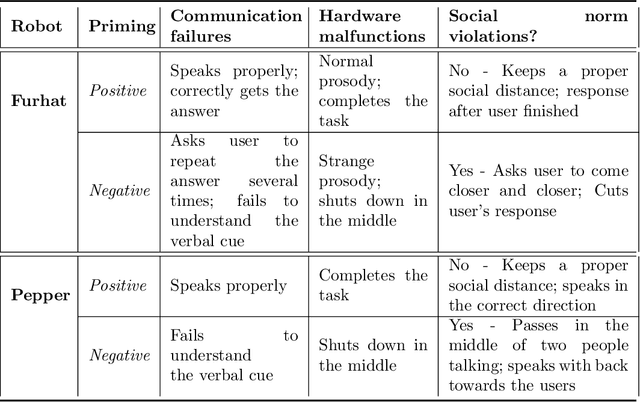
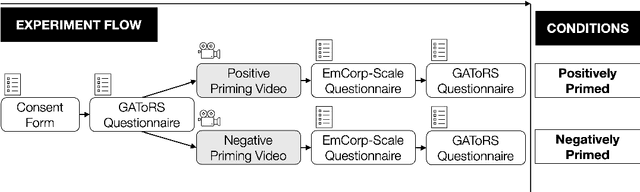
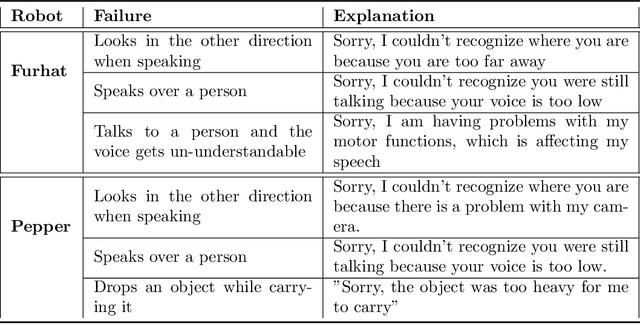
Expectations critically shape how people form judgments about robots, influencing whether they view failures as minor technical glitches or deal-breaking flaws. This work explores how high and low expectations, induced through brief video priming, affect user perceptions of robot failures and the utility of explanations in HRI. We conducted two online studies ($N=600$ total participants); each replicated two robots with different embodiments, Furhat and Pepper. In our first study, grounded in expectation theory, participants were divided into two groups, one primed with positive and the other with negative expectations regarding the robot's performance, establishing distinct expectation frameworks. This validation study aimed to verify whether the videos could reliably establish low and high-expectation profiles. In the second study, participants were primed using the validated videos and then viewed a new scenario in which the robot failed at a task. Half viewed a version where the robot explained its failure, while the other half received no explanation. We found that explanations significantly improved user perceptions of Furhat, especially when participants were primed to have lower expectations. Explanations boosted satisfaction and enhanced the robot's perceived expressiveness, indicating that effectively communicating the cause of errors can help repair user trust. By contrast, Pepper's explanations produced minimal impact on user attitudes, suggesting that a robot's embodiment and style of interaction could determine whether explanations can successfully offset negative impressions. Together, these findings underscore the need to consider users' expectations when tailoring explanation strategies in HRI. When expectations are initially low, a cogent explanation can make the difference between dismissing a failure and appreciating the robot's transparency and effort to communicate.
Ice-Breakers, Turn-Takers and Fun-Makers: Exploring Robots for Groups with Teenagers
Apr 09, 2025



Successful, enjoyable group interactions are important in public and personal contexts, especially for teenagers whose peer groups are important for self-identity and self-esteem. Social robots seemingly have the potential to positively shape group interactions, but it seems difficult to effect such impact by designing robot behaviors solely based on related (human interaction) literature. In this article, we take a user-centered approach to explore how teenagers envisage a social robot "group assistant". We engaged 16 teenagers in focus groups, interviews, and robot testing to capture their views and reflections about robots for groups. Over the course of a two-week summer school, participants co-designed the action space for such a robot and experienced working with/wizarding it for 10+ hours. This experience further altered and deepened their insights into using robots as group assistants. We report results regarding teenagers' views on the applicability and use of a robot group assistant, how these expectations evolved throughout the study, and their repeat interactions with the robot. Our results indicate that each group moves on a spectrum of need for the robot, reflected in use of the robot more (or less) for ice-breaking, turn-taking, and fun-making as the situation demanded.
BT-ACTION: A Test-Driven Approach for Modular Understanding of User Instruction Leveraging Behaviour Trees and LLMs
Apr 03, 2025Natural language instructions are often abstract and complex, requiring robots to execute multiple subtasks even for seemingly simple queries. For example, when a user asks a robot to prepare avocado toast, the task involves several sequential steps. Moreover, such instructions can be ambiguous or infeasible for the robot or may exceed the robot's existing knowledge. While Large Language Models (LLMs) offer strong language reasoning capabilities to handle these challenges, effectively integrating them into robotic systems remains a key challenge. To address this, we propose BT-ACTION, a test-driven approach that combines the modular structure of Behavior Trees (BT) with LLMs to generate coherent sequences of robot actions for following complex user instructions, specifically in the context of preparing recipes in a kitchen-assistance setting. We evaluated BT-ACTION in a comprehensive user study with 45 participants, comparing its performance to direct LLM prompting. Results demonstrate that the modular design of BT-ACTION helped the robot make fewer mistakes and increased user trust, and participants showed a significant preference for the robot leveraging BT-ACTION. The code is publicly available at https://github.com/1Eggbert7/BT_LLM.
Let's move on: Topic Change in Robot-Facilitated Group Discussions
Apr 02, 2025Robot-moderated group discussions have the potential to facilitate engaging and productive interactions among human participants. Previous work on topic management in conversational agents has predominantly focused on human engagement and topic personalization, with the agent having an active role in the discussion. Also, studies have shown the usefulness of including robots in groups, yet further exploration is still needed for robots to learn when to change the topic while facilitating discussions. Accordingly, our work investigates the suitability of machine-learning models and audiovisual non-verbal features in predicting appropriate topic changes. We utilized interactions between a robot moderator and human participants, which we annotated and used for extracting acoustic and body language-related features. We provide a detailed analysis of the performance of machine learning approaches using sequential and non-sequential data with different sets of features. The results indicate promising performance in classifying inappropriate topic changes, outperforming rule-based approaches. Additionally, acoustic features exhibited comparable performance and robustness compared to the complete set of multimodal features. Our annotated data is publicly available at https://github.com/ghadj/topic-change-robot-discussions-data-2024.
* 33rd IEEE International Conference on Robot and Human Interactive Communication (ROMAN)
Long-Term Planning Around Humans in Domestic Environments with 3D Scene Graphs
Mar 12, 2025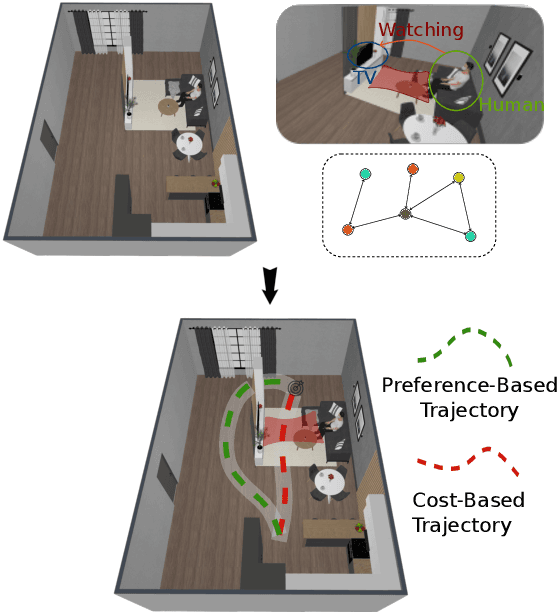
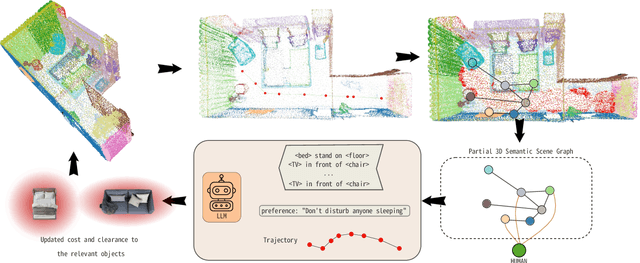
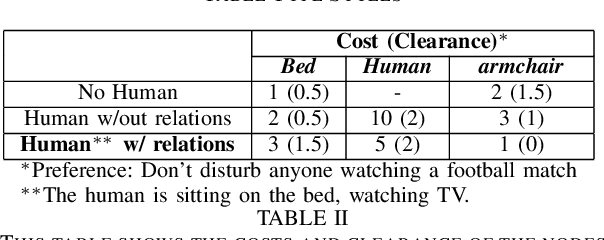
Long-term planning for robots operating in domestic environments poses unique challenges due to the interactions between humans, objects, and spaces. Recent advancements in trajectory planning have leveraged vision-language models (VLMs) to extract contextual information for robots operating in real-world environments. While these methods achieve satisfying performance, they do not explicitly model human activities. Such activities influence surrounding objects and reshape spatial constraints. This paper presents a novel approach to trajectory planning that integrates human preferences, activities, and spatial context through an enriched 3D scene graph (3DSG) representation. By incorporating activity-based relationships, our method captures the spatial impact of human actions, leading to more context-sensitive trajectory adaptation. Preliminary results demonstrate that our approach effectively assigns costs to spaces influenced by human activities, ensuring that the robot trajectory remains contextually appropriate and sensitive to the ongoing environment. This balance between task efficiency and social appropriateness enhances context-aware human-robot interactions in domestic settings. Future work includes implementing a full planning pipeline and conducting user studies to evaluate trajectory acceptability.
Humans Co-exist, So Must Embodied Artificial Agents
Feb 10, 2025



Modern embodied artificial agents excel in static, predefined tasks but fall short in dynamic and long-term interactions with humans. On the other hand, humans can adapt and evolve continuously, exploiting the situated knowledge embedded in their environment and other agents, thus contributing to meaningful interactions. We introduce the concept of co-existence for embodied artificial agents and argues that it is a prerequisite for meaningful, long-term interaction with humans. We take inspiration from biology and design theory to understand how human and non-human organisms foster entities that co-exist within their specific niches. Finally, we propose key research directions for the machine learning community to foster co-existing embodied agents, focusing on the principles, hardware and learning methods responsible for shaping them.
What Can You Say to a Robot? Capability Communication Leads to More Natural Conversations
Feb 03, 2025
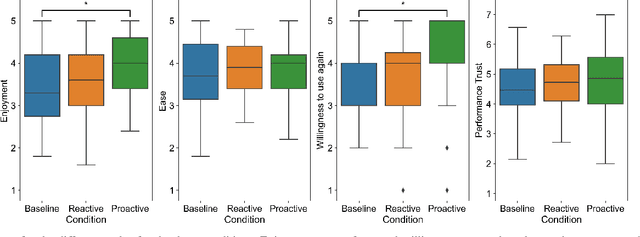
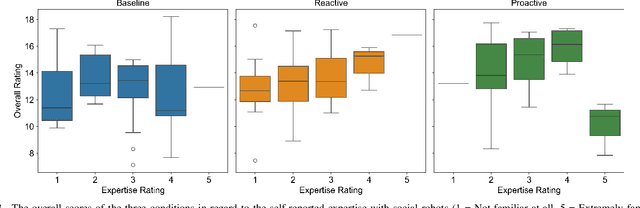
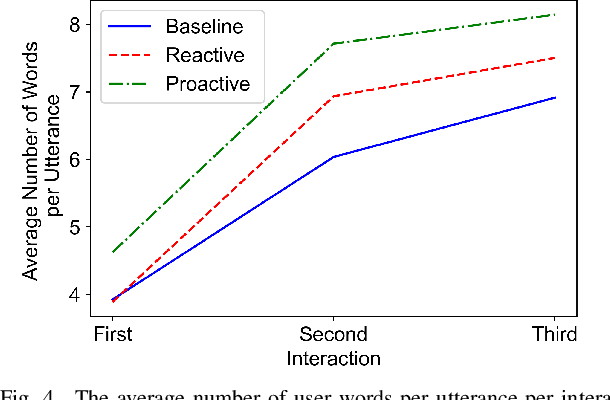
When encountering a robot in the wild, it is not inherently clear to human users what the robot's capabilities are. When encountering misunderstandings or problems in spoken interaction, robots often just apologize and move on, without additional effort to make sure the user understands what happened. We set out to compare the effect of two speech based capability communication strategies (proactive, reactive) to a robot without such a strategy, in regard to the user's rating of and their behavior during the interaction. For this, we conducted an in-person user study with 120 participants who had three speech-based interactions with a social robot in a restaurant setting. Our results suggest that users preferred the robot communicating its capabilities proactively and adjusted their behavior in those interactions, using a more conversational interaction style while also enjoying the interaction more.
How do Humans take an Object from a Robot: Behavior changes observed in a User Study
Jan 03, 2025


To facilitate human-robot interaction and gain human trust, a robot should recognize and adapt to changes in human behavior. This work documents different human behaviors observed while taking objects from an interactive robot in an experimental study, categorized across two dimensions: pull force applied and handedness. We also present the changes observed in human behavior upon repeated interaction with the robot to take various objects.