 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCENT: Aligning Mass Spectra with Molecular Structure for Olfactory Perception
May 26, 2026Predicting human olfactory perception from molecular structure has seen remarkable progress, yet these approaches require explicit chemical structure at inference, which is not available in practical sensing settings. We address this gap by exploring direct electron ionization mass spectrometry (EI-MS), a sensing technique that acquires chemically informative fragmentation fingerprints in seconds, as an alternative input modality for olfactory prediction. We contribute Spectrum-to-Chemical Embedding alignmeNT (SCENT), a multi-modal contrastive learning framework that aligns EI-MS representations with pretrained chemical structure embeddings, while requiring only mass spectra at inference. On the multi-label odor descriptor prediction task, SCENT significantly outperforms MS-only baselines and achieves performance comparable to structure-based models, despite requiring no explicit molecular structure at test time. The learned representations also better approximate continuous human perceptual ratings and generalize to real-world lab-measured spectra, suggesting that cross-modal alignment is an effective strategy for grounding analytical spectra in chemical semantics.
Geometry of Uncertainty: Learning Metric Spaces for Multimodal State Estimation in RL
Feb 12, 2026Estimating the state of an environment from high-dimensional, multimodal, and noisy observations is a fundamental challenge in reinforcement learning (RL). Traditional approaches rely on probabilistic models to account for the uncertainty, but often require explicit noise assumptions, in turn limiting generalization. In this work, we contribute a novel method to learn a structured latent representation, in which distances between states directly correlate with the minimum number of actions required to transition between them. The proposed metric space formulation provides a geometric interpretation of uncertainty without the need for explicit probabilistic modeling. To achieve this, we introduce a multimodal latent transition model and a sensor fusion mechanism based on inverse distance weighting, allowing for the adaptive integration of multiple sensor modalities without prior knowledge of noise distributions. We empirically validate the approach on a range of multimodal RL tasks, demonstrating improved robustness to sensor noise and superior state estimation compared to baseline methods. Our experiments show enhanced performance of an RL agent via the learned representation, eliminating the need of explicit noise augmentation. The presented results suggest that leveraging transition-aware metric spaces provides a principled and scalable solution for robust state estimation in sequential decision-making.
FLoRA: Sample-Efficient Preference-based RL via Low-Rank Style Adaptation of Reward Functions
Apr 14, 2025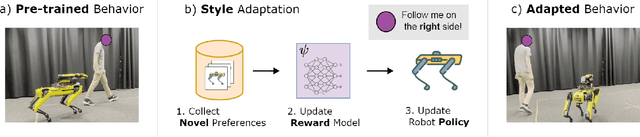
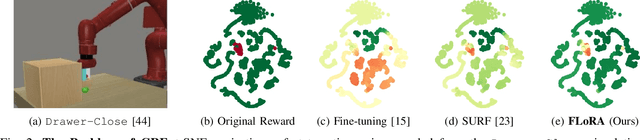
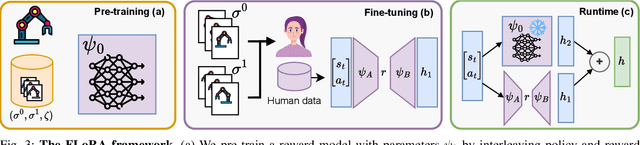
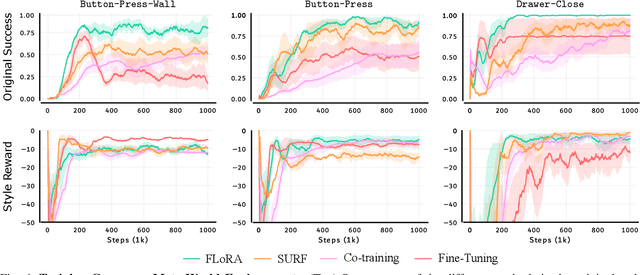
Preference-based reinforcement learning (PbRL) is a suitable approach for style adaptation of pre-trained robotic behavior: adapting the robot's policy to follow human user preferences while still being able to perform the original task. However, collecting preferences for the adaptation process in robotics is often challenging and time-consuming. In this work we explore the adaptation of pre-trained robots in the low-preference-data regime. We show that, in this regime, recent adaptation approaches suffer from catastrophic reward forgetting (CRF), where the updated reward model overfits to the new preferences, leading the agent to become unable to perform the original task. To mitigate CRF, we propose to enhance the original reward model with a small number of parameters (low-rank matrices) responsible for modeling the preference adaptation. Our evaluation shows that our method can efficiently and effectively adjust robotic behavior to human preferences across simulation benchmark tasks and multiple real-world robotic tasks.
FLAME: A Federated Learning Benchmark for Robotic Manipulation
Mar 03, 2025Recent progress in robotic manipulation has been fueled by large-scale datasets collected across diverse environments. Training robotic manipulation policies on these datasets is traditionally performed in a centralized manner, raising concerns regarding scalability, adaptability, and data privacy. While federated learning enables decentralized, privacy-preserving training, its application to robotic manipulation remains largely unexplored. We introduce FLAME (Federated Learning Across Manipulation Environments), the first benchmark designed for federated learning in robotic manipulation. FLAME consists of: (i) a set of large-scale datasets of over 160,000 expert demonstrations of multiple manipulation tasks, collected across a wide range of simulated environments; (ii) a training and evaluation framework for robotic policy learning in a federated setting. We evaluate standard federated learning algorithms in FLAME, showing their potential for distributed policy learning and highlighting key challenges. Our benchmark establishes a foundation for scalable, adaptive, and privacy-aware robotic learning.
Humans Co-exist, So Must Embodied Artificial Agents
Feb 10, 2025



Modern embodied artificial agents excel in static, predefined tasks but fall short in dynamic and long-term interactions with humans. On the other hand, humans can adapt and evolve continuously, exploiting the situated knowledge embedded in their environment and other agents, thus contributing to meaningful interactions. We introduce the concept of co-existence for embodied artificial agents and argues that it is a prerequisite for meaningful, long-term interaction with humans. We take inspiration from biology and design theory to understand how human and non-human organisms foster entities that co-exist within their specific niches. Finally, we propose key research directions for the machine learning community to foster co-existing embodied agents, focusing on the principles, hardware and learning methods responsible for shaping them.
Human-Aligned Image Models Improve Visual Decoding from the Brain
Feb 05, 2025Decoding visual images from brain activity has significant potential for advancing brain-computer interaction and enhancing the understanding of human perception. Recent approaches align the representation spaces of images and brain activity to enable visual decoding. In this paper, we introduce the use of human-aligned image encoders to map brain signals to images. We hypothesize that these models more effectively capture perceptual attributes associated with the rapid visual stimuli presentations commonly used in visual brain data recording experiments. Our empirical results support this hypothesis, demonstrating that this simple modification improves image retrieval accuracy by up to 21% compared to state-of-the-art methods. Comprehensive experiments confirm consistent performance improvements across diverse EEG architectures, image encoders, alignment methods, participants, and brain imaging modalities.
Can Transformers Smell Like Humans?
Nov 05, 2024
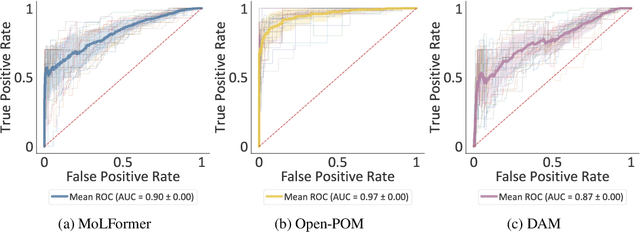
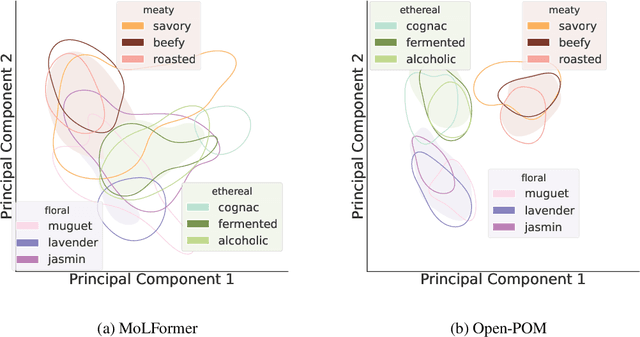
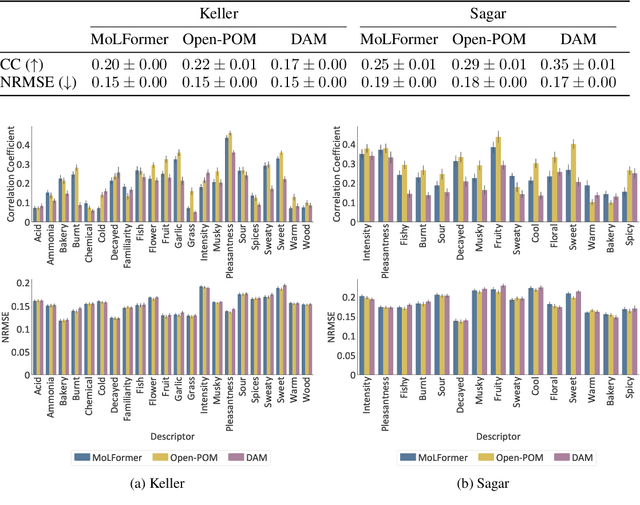
The human brain encodes stimuli from the environment into representations that form a sensory perception of the world. Despite recent advances in understanding visual and auditory perception, olfactory perception remains an under-explored topic in the machine learning community due to the lack of large-scale datasets annotated with labels of human olfactory perception. In this work, we ask the question of whether pre-trained transformer models of chemical structures encode representations that are aligned with human olfactory perception, i.e., can transformers smell like humans? We demonstrate that representations encoded from transformers pre-trained on general chemical structures are highly aligned with human olfactory perception. We use multiple datasets and different types of perceptual representations to show that the representations encoded by transformer models are able to predict: (i) labels associated with odorants provided by experts; (ii) continuous ratings provided by human participants with respect to pre-defined descriptors; and (iii) similarity ratings between odorants provided by human participants. Finally, we evaluate the extent to which this alignment is associated with physicochemical features of odorants known to be relevant for olfactory decoding.
Reducing Variance in Meta-Learning via Laplace Approximation for Regression Tasks
Oct 02, 2024



Given a finite set of sample points, meta-learning algorithms aim to learn an optimal adaptation strategy for new, unseen tasks. Often, this data can be ambiguous as it might belong to different tasks concurrently. This is particularly the case in meta-regression tasks. In such cases, the estimated adaptation strategy is subject to high variance due to the limited amount of support data for each task, which often leads to sub-optimal generalization performance. In this work, we address the problem of variance reduction in gradient-based meta-learning and formalize the class of problems prone to this, a condition we refer to as \emph{task overlap}. Specifically, we propose a novel approach that reduces the variance of the gradient estimate by weighing each support point individually by the variance of its posterior over the parameters. To estimate the posterior, we utilize the Laplace approximation, which allows us to express the variance in terms of the curvature of the loss landscape of our meta-learner. Experimental results demonstrate the effectiveness of the proposed method and highlight the importance of variance reduction in meta-learning.
A Super-human Vision-based Reinforcement Learning Agent for Autonomous Racing in Gran Turismo
Jun 18, 2024



Racing autonomous cars faster than the best human drivers has been a longstanding grand challenge for the fields of Artificial Intelligence and robotics. Recently, an end-to-end deep reinforcement learning agent met this challenge in a high-fidelity racing simulator, Gran Turismo. However, this agent relied on global features that require instrumentation external to the car. This paper introduces, to the best of our knowledge, the first super-human car racing agent whose sensor input is purely local to the car, namely pixels from an ego-centric camera view and quantities that can be sensed from on-board the car, such as the car's velocity. By leveraging global features only at training time, the learned agent is able to outperform the best human drivers in time trial (one car on the track at a time) races using only local input features. The resulting agent is evaluated in Gran Turismo 7 on multiple tracks and cars. Detailed ablation experiments demonstrate the agent's strong reliance on visual inputs, making it the first vision-based super-human car racing agent.
Will You Participate? Exploring the Potential of Robotics Competitions on Human-centric Topics
Mar 27, 2024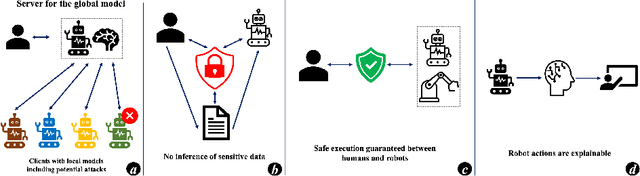


This paper presents findings from an exploratory needfinding study investigating the research current status and potential participation of the competitions on the robotics community towards four human-centric topics: safety, privacy, explainability, and federated learning. We conducted a survey with 34 participants across three distinguished European robotics consortia, nearly 60% of whom possessed over five years of research experience in robotics. Our qualitative and quantitative analysis revealed that current mainstream robotic researchers prioritize safety and explainability, expressing a greater willingness to invest in further research in these areas. Conversely, our results indicate that privacy and federated learning garner less attention and are perceived to have lower potential. Additionally, the study suggests a lack of enthusiasm within the robotics community for participating in competitions related to these topics. Based on these findings, we recommend targeting other communities, such as the machine learning community, for future competitions related to these four human-centric topics.