 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign and Evaluation of an Assisted Programming Interface for Behavior Trees in Robotics
Feb 10, 2026The possibility to create reactive robot programs faster without the need for extensively trained programmers is becoming increasingly important. So far, it has not been explored how various techniques for creating Behavior Tree (BT) program representations could be combined with complete graphical user interfaces (GUIs) to allow a human user to validate and edit trees suggested by automated methods. In this paper, we introduce BEhavior TRee GUI (BETR-GUI) for creating BTs with the help of an AI assistant that combines methods using large language models, planning, genetic programming, and Bayesian optimization with a drag-and-drop editor. A user study with 60 participants shows that by combining different assistive methods, BETR-GUI enables users to perform better at solving the robot programming tasks. The results also show that humans using the full variant of BETR-GUI perform better than the AI assistant running on its own.
YCB-Handovers Dataset: Analyzing Object Weight Impact on Human Handovers to Adapt Robotic Handover Motion
Dec 23, 2025This paper introduces the YCB-Handovers dataset, capturing motion data of 2771 human-human handovers with varying object weights. The dataset aims to bridge a gap in human-robot collaboration research, providing insights into the impact of object weight in human handovers and readiness cues for intuitive robotic motion planning. The underlying dataset for object recognition and tracking is the YCB (Yale-CMU-Berkeley) dataset, which is an established standard dataset used in algorithms for robotic manipulation, including grasping and carrying objects. The YCB-Handovers dataset incorporates human motion patterns in handovers, making it applicable for data-driven, human-inspired models aimed at weight-sensitive motion planning and adaptive robotic behaviors. This dataset covers an extensive range of weights, allowing for a more robust study of handover behavior and weight variation. Some objects also require careful handovers, highlighting contrasts with standard handovers. We also provide a detailed analysis of the object's weight impact on the human reaching motion in these handovers.
Domain Randomization for Object Detection in Manufacturing Applications using Synthetic Data: A Comprehensive Study
Jun 09, 2025This paper addresses key aspects of domain randomization in generating synthetic data for manufacturing object detection applications. To this end, we present a comprehensive data generation pipeline that reflects different factors: object characteristics, background, illumination, camera settings, and post-processing. We also introduce the Synthetic Industrial Parts Object Detection dataset (SIP15-OD) consisting of 15 objects from three industrial use cases under varying environments as a test bed for the study, while also employing an industrial dataset publicly available for robotic applications. In our experiments, we present more abundant results and insights into the feasibility as well as challenges of sim-to-real object detection. In particular, we identified material properties, rendering methods, post-processing, and distractors as important factors. Our method, leveraging these, achieves top performance on the public dataset with Yolov8 models trained exclusively on synthetic data; mAP@50 scores of 96.4% for the robotics dataset, and 94.1%, 99.5%, and 95.3% across three of the SIP15-OD use cases, respectively. The results showcase the effectiveness of the proposed domain randomization, potentially covering the distribution close to real data for the applications.
DLO-Splatting: Tracking Deformable Linear Objects Using 3D Gaussian Splatting
May 13, 2025This work presents DLO-Splatting, an algorithm for estimating the 3D shape of Deformable Linear Objects (DLOs) from multi-view RGB images and gripper state information through prediction-update filtering. The DLO-Splatting algorithm uses a position-based dynamics model with shape smoothness and rigidity dampening corrections to predict the object shape. Optimization with a 3D Gaussian Splatting-based rendering loss iteratively renders and refines the prediction to align it with the visual observations in the update step. Initial experiments demonstrate promising results in a knot tying scenario, which is challenging for existing vision-only methods.
Adapting Robot's Explanation for Failures Based on Observed Human Behavior in Human-Robot Collaboration
Apr 13, 2025

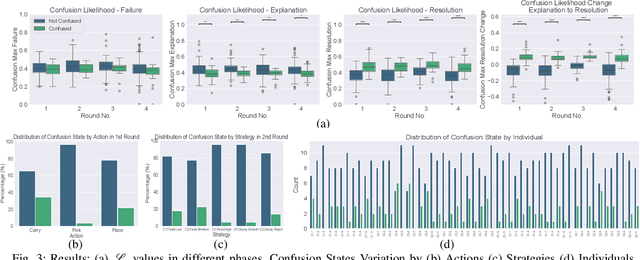
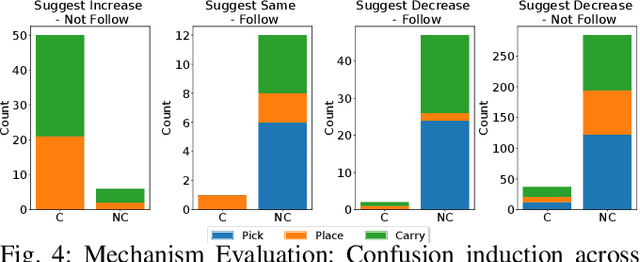
This work aims to interpret human behavior to anticipate potential user confusion when a robot provides explanations for failure, allowing the robot to adapt its explanations for more natural and efficient collaboration. Using a dataset that included facial emotion detection, eye gaze estimation, and gestures from 55 participants in a user study, we analyzed how human behavior changed in response to different types of failures and varying explanation levels. Our goal is to assess whether human collaborators are ready to accept less detailed explanations without inducing confusion. We formulate a data-driven predictor to predict human confusion during robot failure explanations. We also propose and evaluate a mechanism, based on the predictor, to adapt the explanation level according to observed human behavior. The promising results from this evaluation indicate the potential of this research in adapting a robot's explanations for failures to enhance the collaborative experience.
Impact of Object Weight in Handovers: Inspiring Robotic Grip Release and Motion from Human Handovers
Feb 25, 2025This work explores the effect of object weight on human motion and grip release during handovers to enhance the naturalness, safety, and efficiency of robot-human interactions. We introduce adaptive robotic strategies based on the analysis of human handover behavior with varying object weights. The key contributions of this work includes the development of an adaptive grip-release strategy for robots, a detailed analysis of how object weight influences human motion to guide robotic motion adaptations, and the creation of handover-datasets incorporating various object weights, including the YCB handover dataset. By aligning robotic grip release and motion with human behavior, this work aims to improve robot-human handovers for different weighted objects. We also evaluate these human-inspired adaptive robotic strategies in robot-to-human handovers to assess their effectiveness and performance and demonstrate that they outperform the baseline approaches in terms of naturalness, efficiency, and user perception.
REFLEX Dataset: A Multimodal Dataset of Human Reactions to Robot Failures and Explanations
Feb 20, 2025This work presents REFLEX: Robotic Explanations to FaiLures and Human EXpressions, a comprehensive multimodal dataset capturing human reactions to robot failures and subsequent explanations in collaborative settings. It aims to facilitate research into human-robot interaction dynamics, addressing the need to study reactions to both initial failures and explanations, as well as the evolution of these reactions in long-term interactions. By providing rich, annotated data on human responses to different types of failures, explanation levels, and explanation varying strategies, the dataset contributes to the development of more robust, adaptive, and satisfying robotic systems capable of maintaining positive relationships with human collaborators, even during challenges like repeated failures.
Early Detection of Human Handover Intentions in Human-Robot Collaboration: Comparing EEG, Gaze, and Hand Motion
Feb 17, 2025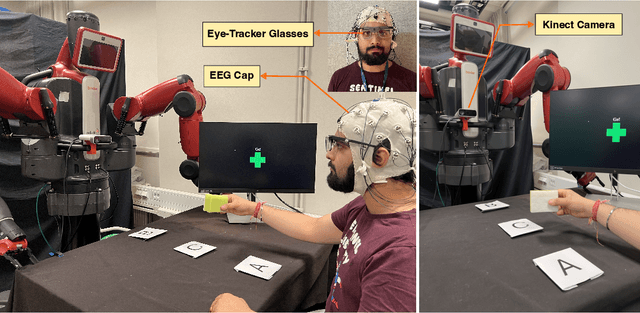
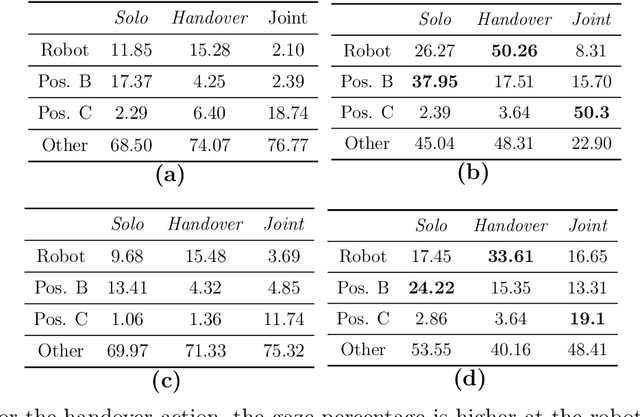
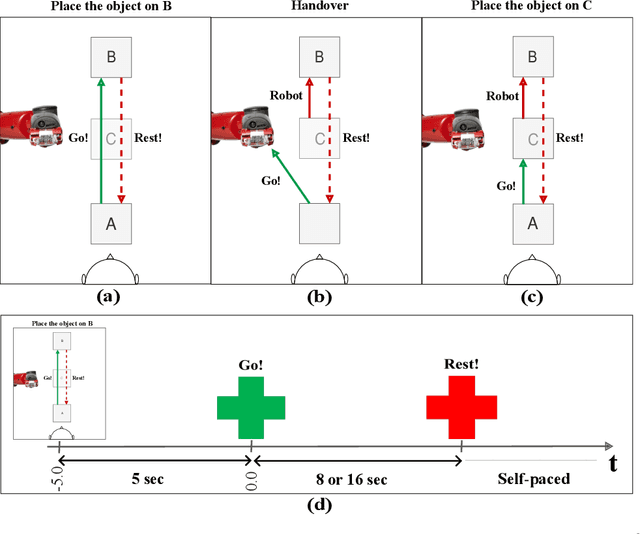
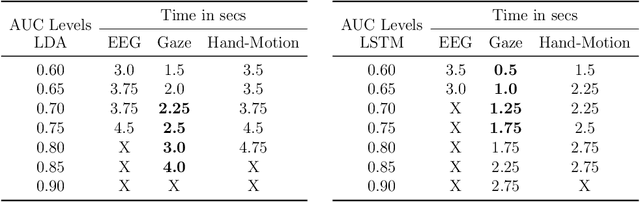
Human-robot collaboration (HRC) relies on accurate and timely recognition of human intentions to ensure seamless interactions. Among common HRC tasks, human-to-robot object handovers have been studied extensively for planning the robot's actions during object reception, assuming the human intention for object handover. However, distinguishing handover intentions from other actions has received limited attention. Most research on handovers has focused on visually detecting motion trajectories, which often results in delays or false detections when trajectories overlap. This paper investigates whether human intentions for object handovers are reflected in non-movement-based physiological signals. We conduct a multimodal analysis comparing three data modalities: electroencephalogram (EEG), gaze, and hand-motion signals. Our study aims to distinguish between handover-intended human motions and non-handover motions in an HRC setting, evaluating each modality's performance in predicting and classifying these actions before and after human movement initiation. We develop and evaluate human intention detectors based on these modalities, comparing their accuracy and timing in identifying handover intentions. To the best of our knowledge, this is the first study to systematically develop and test intention detectors across multiple modalities within the same experimental context of human-robot handovers. Our analysis reveals that handover intention can be detected from all three modalities. Nevertheless, gaze signals are the earliest as well as the most accurate to classify the motion as intended for handover or non-handover.
Human-Aligned Image Models Improve Visual Decoding from the Brain
Feb 05, 2025Decoding visual images from brain activity has significant potential for advancing brain-computer interaction and enhancing the understanding of human perception. Recent approaches align the representation spaces of images and brain activity to enable visual decoding. In this paper, we introduce the use of human-aligned image encoders to map brain signals to images. We hypothesize that these models more effectively capture perceptual attributes associated with the rapid visual stimuli presentations commonly used in visual brain data recording experiments. Our empirical results support this hypothesis, demonstrating that this simple modification improves image retrieval accuracy by up to 21% compared to state-of-the-art methods. Comprehensive experiments confirm consistent performance improvements across diverse EEG architectures, image encoders, alignment methods, participants, and brain imaging modalities.
Cloth-Splatting: 3D Cloth State Estimation from RGB Supervision
Jan 03, 2025



We introduce Cloth-Splatting, a method for estimating 3D states of cloth from RGB images through a prediction-update framework. Cloth-Splatting leverages an action-conditioned dynamics model for predicting future states and uses 3D Gaussian Splatting to update the predicted states. Our key insight is that coupling a 3D mesh-based representation with Gaussian Splatting allows us to define a differentiable map between the cloth state space and the image space. This enables the use of gradient-based optimization techniques to refine inaccurate state estimates using only RGB supervision. Our experiments demonstrate that Cloth-Splatting not only improves state estimation accuracy over current baselines but also reduces convergence time.