 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHearing the Slide: Acoustic-Guided Constraint Learning for Fast Non-Prehensile Transport
Jun 10, 2025Object transport tasks are fundamental in robotic automation, emphasizing the importance of efficient and secure methods for moving objects. Non-prehensile transport can significantly improve transport efficiency, as it enables handling multiple objects simultaneously and accommodating objects unsuitable for parallel-jaw or suction grasps. Existing approaches incorporate constraints based on the Coulomb friction model, which is imprecise during fast motions where inherent mechanical vibrations occur. Imprecise constraints can cause transported objects to slide or even fall off the tray. To address this limitation, we propose a novel method to learn a friction model using acoustic sensing that maps a tray's motion profile to a dynamically conditioned friction coefficient. This learned model enables an optimization-based motion planner to adjust the friction constraint at each control step according to the planned motion at that step. In experiments, we generate time-optimized trajectories for a UR5e robot to transport various objects with constraints using both the standard Coulomb friction model and the learned friction model. Results suggest that the learned friction model reduces object displacement by up to 86.0% compared to the baseline, highlighting the effectiveness of acoustic sensing in learning real-world friction constraints.
RaySt3R: Predicting Novel Depth Maps for Zero-Shot Object Completion
Jun 05, 20253D shape completion has broad applications in robotics, digital twin reconstruction, and extended reality (XR). Although recent advances in 3D object and scene completion have achieved impressive results, existing methods lack 3D consistency, are computationally expensive, and struggle to capture sharp object boundaries. Our work (RaySt3R) addresses these limitations by recasting 3D shape completion as a novel view synthesis problem. Specifically, given a single RGB-D image and a novel viewpoint (encoded as a collection of query rays), we train a feedforward transformer to predict depth maps, object masks, and per-pixel confidence scores for those query rays. RaySt3R fuses these predictions across multiple query views to reconstruct complete 3D shapes. We evaluate RaySt3R on synthetic and real-world datasets, and observe it achieves state-of-the-art performance, outperforming the baselines on all datasets by up to 44% in 3D chamfer distance. Project page: https://rayst3r.github.io
Cloth-Splatting: 3D Cloth State Estimation from RGB Supervision
Jan 03, 2025



We introduce Cloth-Splatting, a method for estimating 3D states of cloth from RGB images through a prediction-update framework. Cloth-Splatting leverages an action-conditioned dynamics model for predicting future states and uses 3D Gaussian Splatting to update the predicted states. Our key insight is that coupling a 3D mesh-based representation with Gaussian Splatting allows us to define a differentiable map between the cloth state space and the image space. This enables the use of gradient-based optimization techniques to refine inaccurate state estimates using only RGB supervision. Our experiments demonstrate that Cloth-Splatting not only improves state estimation accuracy over current baselines but also reduces convergence time.
Residual-NeRF: Learning Residual NeRFs for Transparent Object Manipulation
May 10, 2024Transparent objects are ubiquitous in industry, pharmaceuticals, and households. Grasping and manipulating these objects is a significant challenge for robots. Existing methods have difficulty reconstructing complete depth maps for challenging transparent objects, leaving holes in the depth reconstruction. Recent work has shown neural radiance fields (NeRFs) work well for depth perception in scenes with transparent objects, and these depth maps can be used to grasp transparent objects with high accuracy. NeRF-based depth reconstruction can still struggle with especially challenging transparent objects and lighting conditions. In this work, we propose Residual-NeRF, a method to improve depth perception and training speed for transparent objects. Robots often operate in the same area, such as a kitchen. By first learning a background NeRF of the scene without transparent objects to be manipulated, we reduce the ambiguity faced by learning the changes with the new object. We propose training two additional networks: a residual NeRF learns to infer residual RGB values and densities, and a Mixnet learns how to combine background and residual NeRFs. We contribute synthetic and real experiments that suggest Residual-NeRF improves depth perception of transparent objects. The results on synthetic data suggest Residual-NeRF outperforms the baselines with a 46.1% lower RMSE and a 29.5% lower MAE. Real-world qualitative experiments suggest Residual-NeRF leads to more robust depth maps with less noise and fewer holes. Website: https://residual-nerf.github.io
MD-Splatting: Learning Metric Deformation from 4D Gaussians in Highly Deformable Scenes
Nov 30, 2023



Accurate 3D tracking in highly deformable scenes with occlusions and shadows can facilitate new applications in robotics, augmented reality, and generative AI. However, tracking under these conditions is extremely challenging due to the ambiguity that arises with large deformations, shadows, and occlusions. We introduce MD-Splatting, an approach for simultaneous 3D tracking and novel view synthesis, using video captures of a dynamic scene from various camera poses. MD-Splatting builds on recent advances in Gaussian splatting, a method that learns the properties of a large number of Gaussians for state-of-the-art and fast novel view synthesis. MD-Splatting learns a deformation function to project a set of Gaussians with non-metric, thus canonical, properties into metric space. The deformation function uses a neural-voxel encoding and a multilayer perceptron (MLP) to infer Gaussian position, rotation, and a shadow scalar. We enforce physics-inspired regularization terms based on local rigidity, conservation of momentum, and isometry, which leads to trajectories with smaller trajectory errors. MD-Splatting achieves high-quality 3D tracking on highly deformable scenes with shadows and occlusions. Compared to state-of-the-art, we improve 3D tracking by an average of 23.9 %, while simultaneously achieving high-quality novel view synthesis. With sufficient texture such as in scene 6, MD-Splatting achieves a median tracking error of 3.39 mm on a cloth of 1 x 1 meters in size. Project website: https://md-splatting.github.io/.
Tiny Robot Learning: Challenges and Directions for Machine Learning in Resource-Constrained Robots
May 11, 2022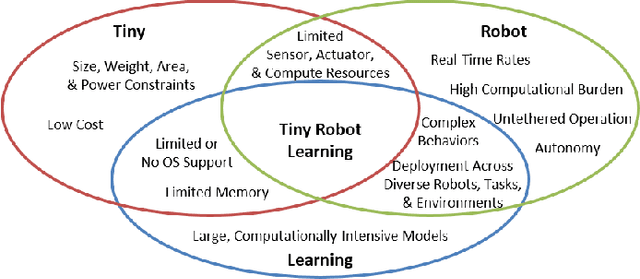
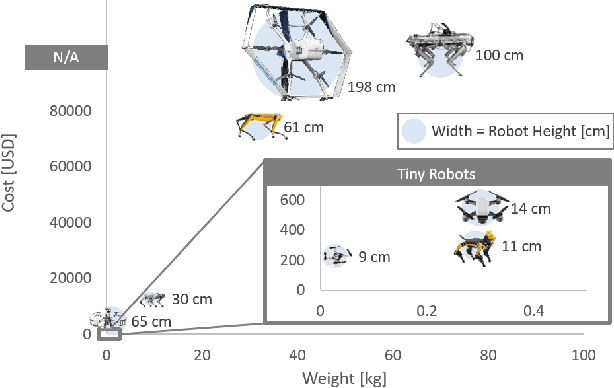
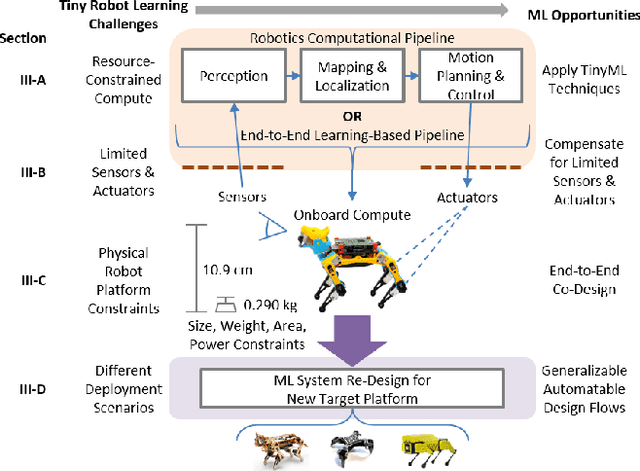
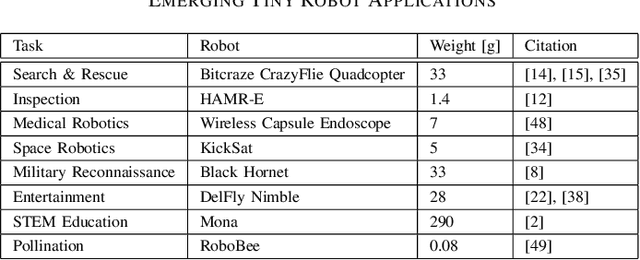
Machine learning (ML) has become a pervasive tool across computing systems. An emerging application that stress-tests the challenges of ML system design is tiny robot learning, the deployment of ML on resource-constrained low-cost autonomous robots. Tiny robot learning lies at the intersection of embedded systems, robotics, and ML, compounding the challenges of these domains. Tiny robot learning is subject to challenges from size, weight, area, and power (SWAP) constraints; sensor, actuator, and compute hardware limitations; end-to-end system tradeoffs; and a large diversity of possible deployment scenarios. Tiny robot learning requires ML models to be designed with these challenges in mind, providing a crucible that reveals the necessity of holistic ML system design and automated end-to-end design tools for agile development. This paper gives a brief survey of the tiny robot learning space, elaborates on key challenges, and proposes promising opportunities for future work in ML system design.
Sniffy Bug: A Fully Autonomous Swarm of Gas-Seeking Nano Quadcopters in Cluttered Environments
Jul 12, 2021
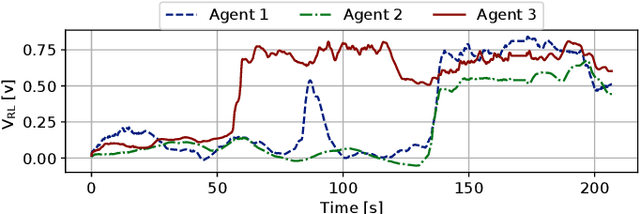


Nano quadcopters are ideal for gas source localization (GSL) as they are safe, agile and inexpensive. However, their extremely restricted sensors and computational resources make GSL a daunting challenge. In this work, we propose a novel bug algorithm named `Sniffy Bug', which allows a fully autonomous swarm of gas-seeking nano quadcopters to localize a gas source in an unknown, cluttered and GPS-denied environments. The computationally efficient, mapless algorithm foresees in the avoidance of obstacles and other swarm members, while pursuing desired waypoints. The waypoints are first set for exploration, and, when a single swarm member has sensed the gas, by a particle swarm optimization-based procedure. We evolve all the parameters of the bug (and PSO) algorithm, using our novel simulation pipeline, `AutoGDM'. It builds on and expands open source tools in order to enable fully automated end-to-end environment generation and gas dispersion modeling, allowing for learning in simulation. Flight tests show that Sniffy Bug with evolved parameters outperforms manually selected parameters in cluttered, real-world environments.
Learning to Seek: Autonomous Source Seeking with Deep Reinforcement Learning Onboard a Nano Drone Microcontroller
Sep 29, 2019


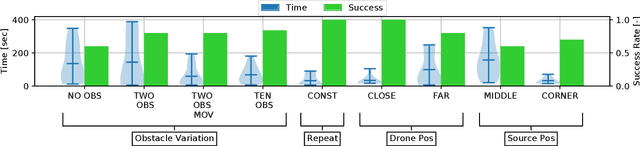
Fully autonomous navigation using nano drones has numerous applications in the real world, ranging from search and rescue to source seeking. Nano drones are well-suited for source seeking because of their agility, low price, and ubiquitous character. Unfortunately, their constrained form factor limits flight time, sensor payload, and compute capability. These challenges are a crucial limitation for the use of source-seeking nano drones in GPS-denied and highly cluttered environments. Hereby, we introduce a fully autonomous deep reinforcement learning-based light-seeking nano drone. The 33-gram nano drone performs all computation on-board the ultra-low-power microcontroller (MCU). We present the method for efficiently training, converting, and utilizing deep reinforcement learning policies. Our training methodology and novel quantization scheme allow fitting the trained policy in 3 kB of memory. The quantization scheme uses representative input data and input scaling to arrive at a full 8-bit model. Finally, we evaluate the approach in simulation and flight tests using a Bitcraze CrazyFlie, achieving 80% success rate on average in a highly cluttered and randomized test environment. Even more, the drone finds the light source in 29% fewer steps compared to a baseline simulation (obstacle avoidance without source information). To our knowledge, this is the first deep reinforcement learning method that enables source seeking within a highly constrained nano drone demonstrating robust flight behavior. Our general methodology is suitable for any (source seeking) highly constrained platform using deep reinforcement learning.