 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2Perf: Real-World Autonomous Agents Benchmark
Mar 04, 2025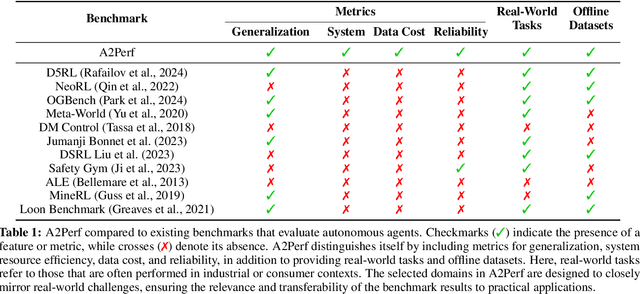

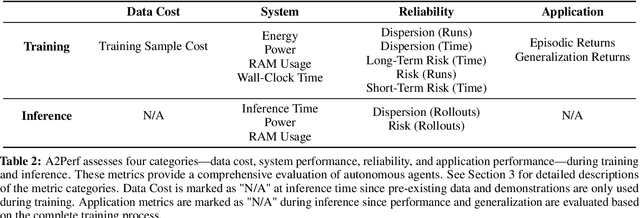

Autonomous agents and systems cover a number of application areas, from robotics and digital assistants to combinatorial optimization, all sharing common, unresolved research challenges. It is not sufficient for agents to merely solve a given task; they must generalize to out-of-distribution tasks, perform reliably, and use hardware resources efficiently during training and inference, among other requirements. Several methods, such as reinforcement learning and imitation learning, are commonly used to tackle these problems, each with different trade-offs. However, there is a lack of benchmarking suites that define the environments, datasets, and metrics which can be used to provide a meaningful way for the community to compare progress on applying these methods to real-world problems. We introduce A2Perf--a benchmark with three environments that closely resemble real-world domains: computer chip floorplanning, web navigation, and quadruped locomotion. A2Perf provides metrics that track task performance, generalization, system resource efficiency, and reliability, which are all critical to real-world applications. Using A2Perf, we demonstrate that web navigation agents can achieve latencies comparable to human reaction times on consumer hardware, reveal reliability trade-offs between algorithms for quadruped locomotion, and quantify the energy costs of different learning approaches for computer chip-design. In addition, we propose a data cost metric to account for the cost incurred acquiring offline data for imitation learning and hybrid algorithms, which allows us to better compare these approaches. A2Perf also contains several standard baselines, enabling apples-to-apples comparisons across methods and facilitating progress in real-world autonomy. As an open-source benchmark, A2Perf is designed to remain accessible, up-to-date, and useful to the research community over the long term.
ArchGym: An Open-Source Gymnasium for Machine Learning Assisted Architecture Design
Jun 15, 2023Machine learning is a prevalent approach to tame the complexity of design space exploration for domain-specific architectures. Using ML for design space exploration poses challenges. First, it's not straightforward to identify the suitable algorithm from an increasing pool of ML methods. Second, assessing the trade-offs between performance and sample efficiency across these methods is inconclusive. Finally, lack of a holistic framework for fair, reproducible, and objective comparison across these methods hinders progress of adopting ML-aided architecture design space exploration and impedes creating repeatable artifacts. To mitigate these challenges, we introduce ArchGym, an open-source gym and easy-to-extend framework that connects diverse search algorithms to architecture simulators. To demonstrate utility, we evaluate ArchGym across multiple vanilla and domain-specific search algorithms in designing custom memory controller, deep neural network accelerators, and custom SoC for AR/VR workloads, encompassing over 21K experiments. Results suggest that with unlimited samples, ML algorithms are equally favorable to meet user-defined target specification if hyperparameters are tuned; no solution is necessarily better than another (e.g., reinforcement learning vs. Bayesian methods). We coin the term hyperparameter lottery to describe the chance for a search algorithm to find an optimal design provided meticulously selected hyperparameters. The ease of data collection and aggregation in ArchGym facilitates research in ML-aided architecture design space exploration. As a case study, we show this advantage by developing a proxy cost model with an RMSE of 0.61% that offers a 2,000-fold reduction in simulation time. Code and data for ArchGym is available at https://bit.ly/ArchGym.
Multi-Agent Reinforcement Learning for Microprocessor Design Space Exploration
Nov 29, 2022



Microprocessor architects are increasingly resorting to domain-specific customization in the quest for high-performance and energy-efficiency. As the systems grow in complexity, fine-tuning architectural parameters across multiple sub-systems (e.g., datapath, memory blocks in different hierarchies, interconnects, compiler optimization, etc.) quickly results in a combinatorial explosion of design space. This makes domain-specific customization an extremely challenging task. Prior work explores using reinforcement learning (RL) and other optimization methods to automatically explore the large design space. However, these methods have traditionally relied on single-agent RL/ML formulations. It is unclear how scalable single-agent formulations are as we increase the complexity of the design space (e.g., full stack System-on-Chip design). Therefore, we propose an alternative formulation that leverages Multi-Agent RL (MARL) to tackle this problem. The key idea behind using MARL is an observation that parameters across different sub-systems are more or less independent, thus allowing a decentralized role assigned to each agent. We test this hypothesis by designing domain-specific DRAM memory controller for several workload traces. Our evaluation shows that the MARL formulation consistently outperforms single-agent RL baselines such as Proximal Policy Optimization and Soft Actor-Critic over different target objectives such as low power and latency. To this end, this work opens the pathway for new and promising research in MARL solutions for hardware architecture search.
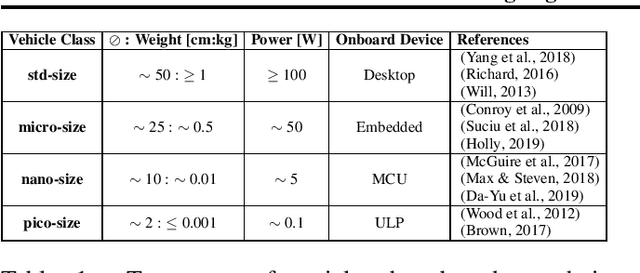
Tiny Robot Learning: Challenges and Directions for Machine Learning in Resource-Constrained Robots
May 11, 2022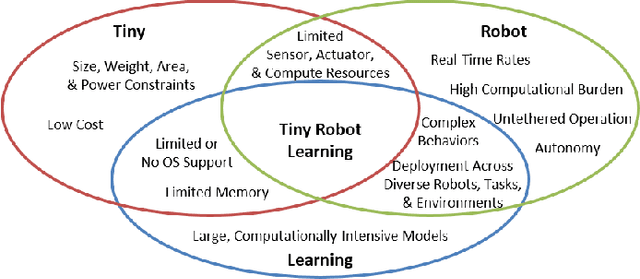
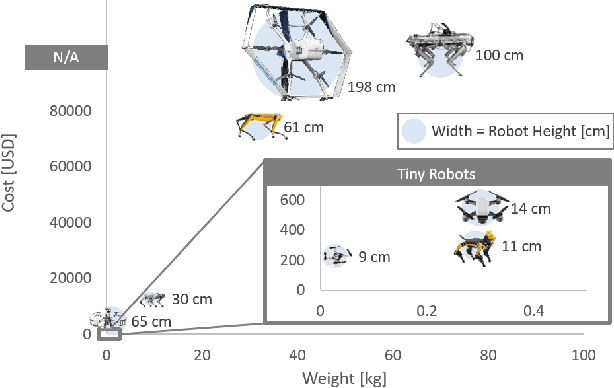
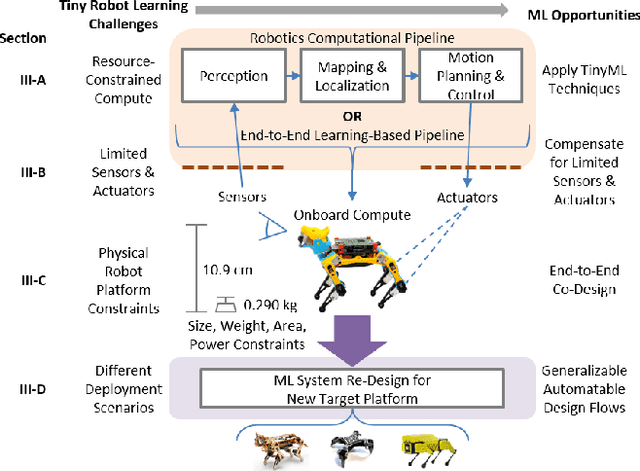
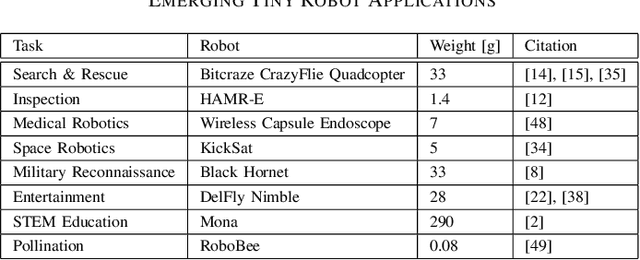
Machine learning (ML) has become a pervasive tool across computing systems. An emerging application that stress-tests the challenges of ML system design is tiny robot learning, the deployment of ML on resource-constrained low-cost autonomous robots. Tiny robot learning lies at the intersection of embedded systems, robotics, and ML, compounding the challenges of these domains. Tiny robot learning is subject to challenges from size, weight, area, and power (SWAP) constraints; sensor, actuator, and compute hardware limitations; end-to-end system tradeoffs; and a large diversity of possible deployment scenarios. Tiny robot learning requires ML models to be designed with these challenges in mind, providing a crucible that reveals the necessity of holistic ML system design and automated end-to-end design tools for agile development. This paper gives a brief survey of the tiny robot learning space, elaborates on key challenges, and proposes promising opportunities for future work in ML system design.
Roofline Model for UAVs: A Bottleneck Analysis Tool for Onboard Compute Characterization of Autonomous Unmanned Aerial Vehicles
Apr 22, 2022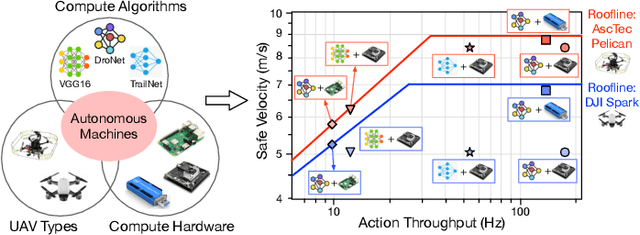
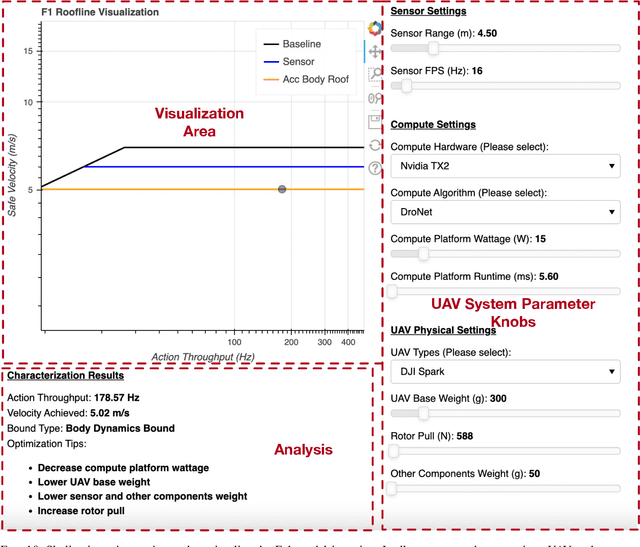
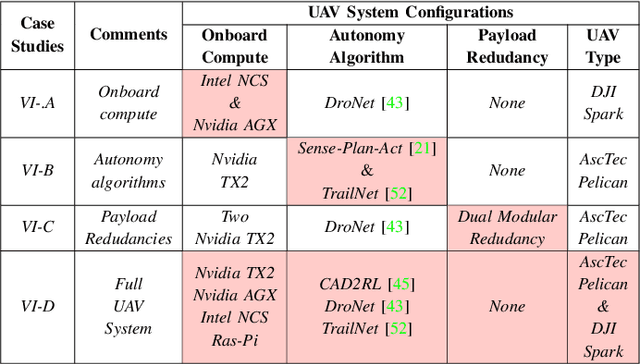
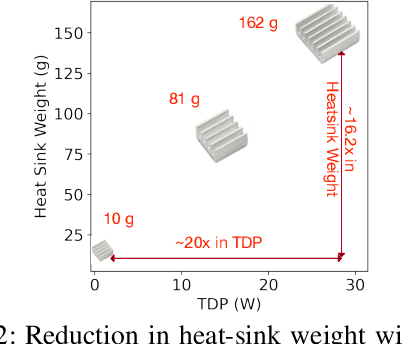
We introduce an early-phase bottleneck analysis and characterization model called the F-1 for designing computing systems that target autonomous Unmanned Aerial Vehicles (UAVs). The model provides insights by exploiting the fundamental relationships between various components in the autonomous UAV, such as sensor, compute, and body dynamics. To guarantee safe operation while maximizing the performance (e.g., velocity) of the UAV, the compute, sensor, and other mechanical properties must be carefully selected or designed. The F-1 model provides visual insights that can aid a system architect in understanding the optimal compute design or selection for autonomous UAVs. The model is experimentally validated using real UAVs, and the error is between 5.1\% to 9.5\% compared to real-world flight tests. An interactive web-based tool for the F-1 model called Skyline is available for free of cost use at: ~\url{https://bit.ly/skyline-tool}
Roofline Model for UAVs:A Bottleneck Analysis Tool for Designing Compute Systems for Autonomous Drones
Nov 13, 2021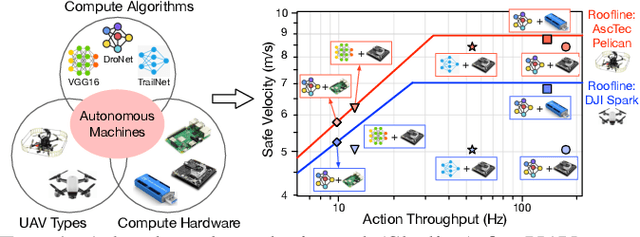
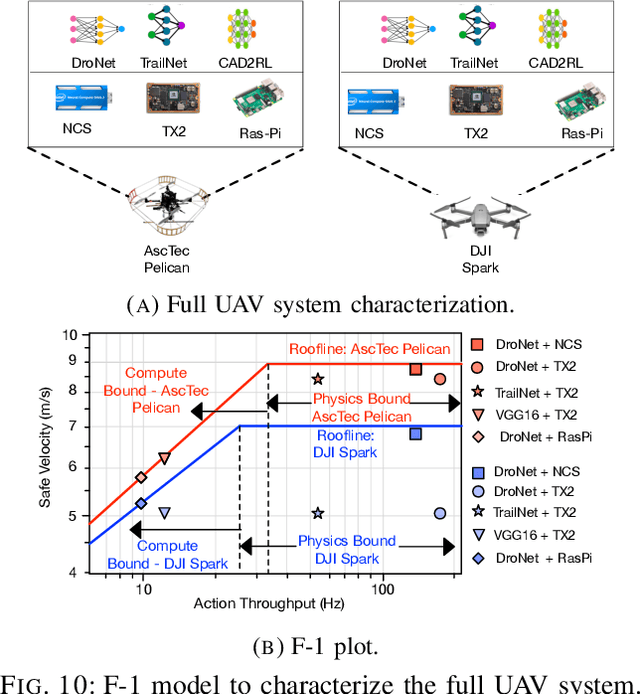


We present a bottleneck analysis tool for designing compute systems for autonomous Unmanned Aerial Vehicles (UAV). The tool provides insights by exploiting the fundamental relationships between various components in the autonomous UAV such as sensor, compute, body dynamics. To guarantee safe operation while maximizing the performance (e.g., velocity) of the UAV, the compute, sensor, and other mechanical properties must be carefully designed (or selected). The goal of our proposed tool is to provide a visual model which aids system architects to understand optimal compute design (or selection) for autonomous UAVs. The tool is available here:~\url{https://bit.ly/skyline-tool}
AutoSoC: Automating Algorithm-SOC Co-design for Aerial Robots
Sep 13, 2021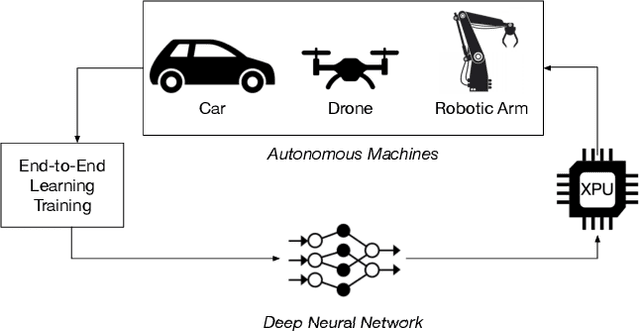
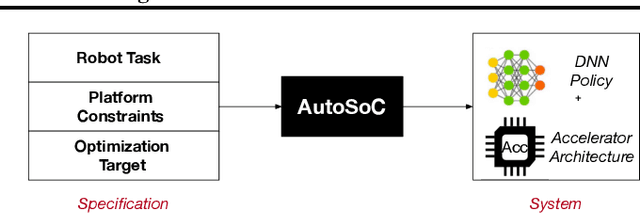

Aerial autonomous machines (Drones) has a plethora of promising applications and use cases. While the popularity of these autonomous machines continues to grow, there are many challenges, such as endurance and agility, that could hinder the practical deployment of these machines. The closed-loop control frequency must be high to achieve high agility. However, given the resource-constrained nature of the aerial robot, achieving high control loop frequency is hugely challenging and requires careful co-design of algorithm and onboard computer. Such an effort requires infrastructures that bridge various domains, namely robotics, machine learning, and system architecture design. To that end, we present AutoSoC, a framework for co-designing algorithms as well as hardware accelerator systems for end-to-end learning-based aerial autonomous machines. We demonstrate the efficacy of the framework by training an obstacle avoidance algorithm for aerial robots to navigate in a densely cluttered environment. For the best performing algorithm, our framework generates various accelerator design candidates with varying performance, area, and power consumption. The framework also runs the ASIC flow of place and route and generates a layout of the floor-planed accelerator, which can be used to tape-out the final hardware chip.
Widening Access to Applied Machine Learning with TinyML
Jun 09, 2021
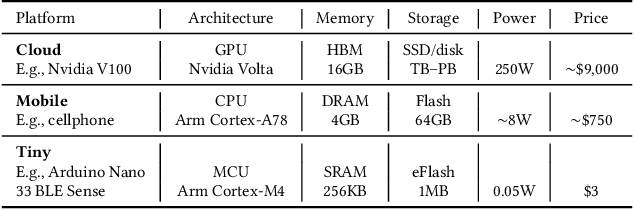

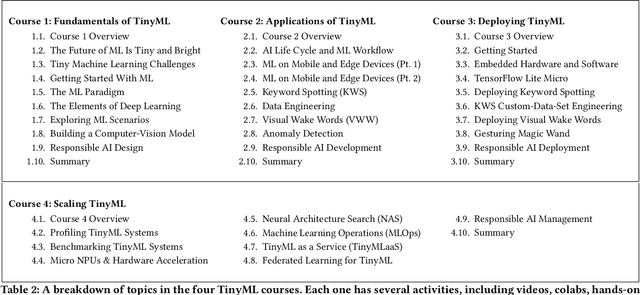
Broadening access to both computational and educational resources is critical to diffusing machine-learning (ML) innovation. However, today, most ML resources and experts are siloed in a few countries and organizations. In this paper, we describe our pedagogical approach to increasing access to applied ML through a massive open online course (MOOC) on Tiny Machine Learning (TinyML). We suggest that TinyML, ML on resource-constrained embedded devices, is an attractive means to widen access because TinyML both leverages low-cost and globally accessible hardware, and encourages the development of complete, self-contained applications, from data collection to deployment. To this end, a collaboration between academia (Harvard University) and industry (Google) produced a four-part MOOC that provides application-oriented instruction on how to develop solutions using TinyML. The series is openly available on the edX MOOC platform, has no prerequisites beyond basic programming, and is designed for learners from a global variety of backgrounds. It introduces pupils to real-world applications, ML algorithms, data-set engineering, and the ethical considerations of these technologies via hands-on programming and deployment of TinyML applications in both the cloud and their own microcontrollers. To facilitate continued learning, community building, and collaboration beyond the courses, we launched a standalone website, a forum, a chat, and an optional course-project competition. We also released the course materials publicly, hoping they will inspire the next generation of ML practitioners and educators and further broaden access to cutting-edge ML technologies.
RL-Scope: Cross-Stack Profiling for Deep Reinforcement Learning Workloads
Mar 04, 2021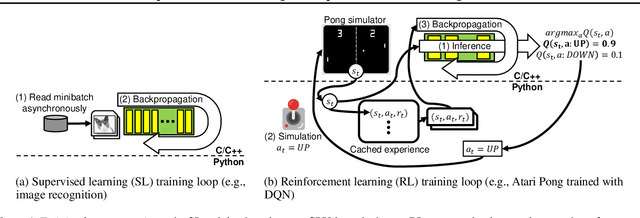



Deep reinforcement learning (RL) has made groundbreaking advancements in robotics, data center management and other applications. Unfortunately, system-level bottlenecks in RL workloads are poorly understood; we observe fundamental structural differences in RL workloads that make them inherently less GPU-bound than supervised learning (SL). To explain where training time is spent in RL workloads, we propose RL-Scope, a cross-stack profiler that scopes low-level CPU/GPU resource usage to high-level algorithmic operations, and provides accurate insights by correcting for profiling overhead. Using RL-Scope, we survey RL workloads across its major dimensions including ML backend, RL algorithm, and simulator. For ML backends, we explain a $2.3\times$ difference in runtime between equivalent PyTorch and TensorFlow algorithm implementations, and identify a bottleneck rooted in overly abstracted algorithm implementations. For RL algorithms and simulators, we show that on-policy algorithms are at least $3.5\times$ more simulation-bound than off-policy algorithms. Finally, we profile a scale-up workload and demonstrate that GPU utilization metrics reported by commonly used tools dramatically inflate GPU usage, whereas RL-Scope reports true GPU-bound time. RL-Scope is an open-source tool available at https://github.com/UofT-EcoSystem/rlscope .
Machine Learning-Based Automated Design Space Exploration for Autonomous Aerial Robots
Feb 05, 2021
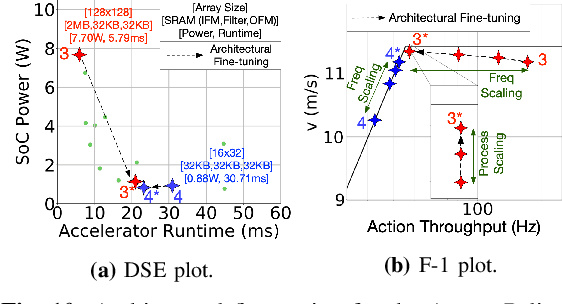


Building domain-specific architectures for autonomous aerial robots is challenging due to a lack of systematic methodology for designing onboard compute. We introduce a novel performance model called the F-1 roofline to help architects understand how to build a balanced computing system for autonomous aerial robots considering both its cyber (sensor rate, compute performance) and physical components (body-dynamics) that affect the performance of the machine. We use F-1 to characterize commonly used learning-based autonomy algorithms with onboard platforms to demonstrate the need for cyber-physical co-design. To navigate the cyber-physical design space automatically, we subsequently introduce AutoPilot. This push-button framework automates the co-design of cyber-physical components for aerial robots from a high-level specification guided by the F-1 model. AutoPilot uses Bayesian optimization to automatically co-design the autonomy algorithm and hardware accelerator while considering various cyber-physical parameters to generate an optimal design under different task level complexities for different robots and sensor framerates. As a result, designs generated by AutoPilot, on average, lower mission time up to 2x over baseline approaches, conserving battery energy.