 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Data Collection in Deep Reinforcement Learning
Jul 15, 2022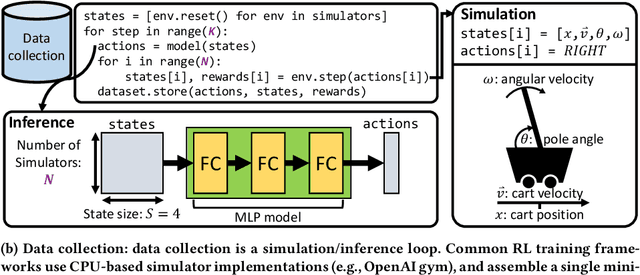
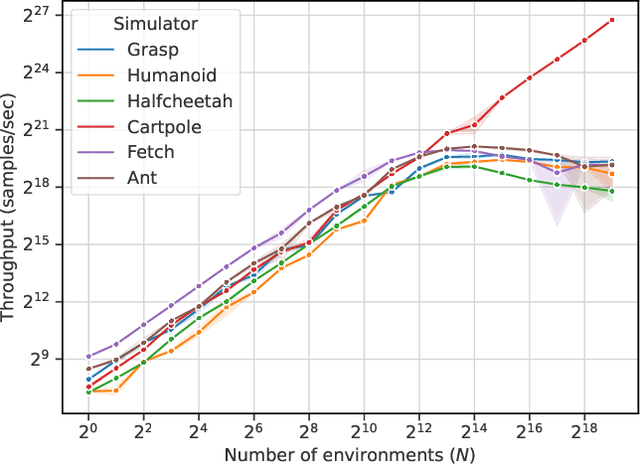
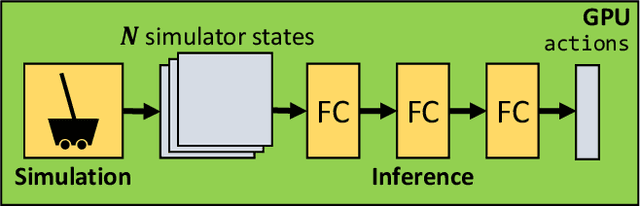
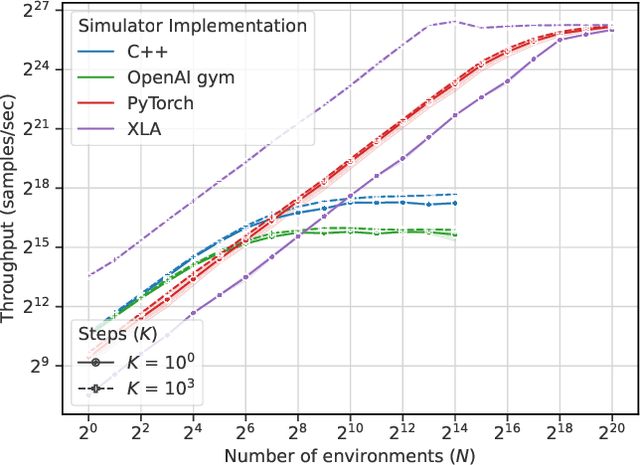
Reinforcement learning (RL) workloads take a notoriously long time to train due to the large number of samples collected at run-time from simulators. Unfortunately, cluster scale-up approaches remain expensive, and commonly used CPU implementations of simulators induce high overhead when switching back and forth between GPU computations. We explore two optimizations that increase RL data collection efficiency by increasing GPU utilization: (1) GPU vectorization: parallelizing simulation on the GPU for increased hardware parallelism, and (2) simulator kernel fusion: fusing multiple simulation steps to run in a single GPU kernel launch to reduce global memory bandwidth requirements. We find that GPU vectorization can achieve up to $1024\times$ speedup over commonly used CPU simulators. We profile the performance of different implementations and show that for a simple simulator, ML compiler implementations (XLA) of GPU vectorization outperform a DNN framework (PyTorch) by $13.4\times$ by reducing CPU overhead from repeated Python to DL backend API calls. We show that simulator kernel fusion speedups with a simple simulator are $11.3\times$ and increase by up to $1024\times$ as simulator complexity increases in terms of memory bandwidth requirements. We show that the speedups from simulator kernel fusion are orthogonal and combinable with GPU vectorization, leading to a multiplicative speedup.
RL-Scope: Cross-Stack Profiling for Deep Reinforcement Learning Workloads
Mar 04, 2021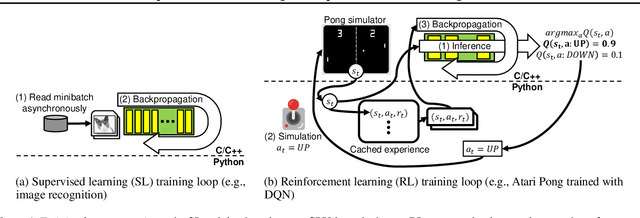



Deep reinforcement learning (RL) has made groundbreaking advancements in robotics, data center management and other applications. Unfortunately, system-level bottlenecks in RL workloads are poorly understood; we observe fundamental structural differences in RL workloads that make them inherently less GPU-bound than supervised learning (SL). To explain where training time is spent in RL workloads, we propose RL-Scope, a cross-stack profiler that scopes low-level CPU/GPU resource usage to high-level algorithmic operations, and provides accurate insights by correcting for profiling overhead. Using RL-Scope, we survey RL workloads across its major dimensions including ML backend, RL algorithm, and simulator. For ML backends, we explain a $2.3\times$ difference in runtime between equivalent PyTorch and TensorFlow algorithm implementations, and identify a bottleneck rooted in overly abstracted algorithm implementations. For RL algorithms and simulators, we show that on-policy algorithms are at least $3.5\times$ more simulation-bound than off-policy algorithms. Finally, we profile a scale-up workload and demonstrate that GPU utilization metrics reported by commonly used tools dramatically inflate GPU usage, whereas RL-Scope reports true GPU-bound time. RL-Scope is an open-source tool available at https://github.com/UofT-EcoSystem/rlscope .