 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Neural Network Training Algorithms
Jun 12, 2023



Training algorithms, broadly construed, are an essential part of every deep learning pipeline. Training algorithm improvements that speed up training across a wide variety of workloads (e.g., better update rules, tuning protocols, learning rate schedules, or data selection schemes) could save time, save computational resources, and lead to better, more accurate, models. Unfortunately, as a community, we are currently unable to reliably identify training algorithm improvements, or even determine the state-of-the-art training algorithm. In this work, using concrete experiments, we argue that real progress in speeding up training requires new benchmarks that resolve three basic challenges faced by empirical comparisons of training algorithms: (1) how to decide when training is complete and precisely measure training time, (2) how to handle the sensitivity of measurements to exact workload details, and (3) how to fairly compare algorithms that require hyperparameter tuning. In order to address these challenges, we introduce a new, competitive, time-to-result benchmark using multiple workloads running on fixed hardware, the AlgoPerf: Training Algorithms benchmark. Our benchmark includes a set of workload variants that make it possible to detect benchmark submissions that are more robust to workload changes than current widely-used methods. Finally, we evaluate baseline submissions constructed using various optimizers that represent current practice, as well as other optimizers that have recently received attention in the literature. These baseline results collectively demonstrate the feasibility of our benchmark, show that non-trivial gaps between methods exist, and set a provisional state-of-the-art for future benchmark submissions to try and surpass.
Operator Fusion in XLA: Analysis and Evaluation
Jan 30, 2023

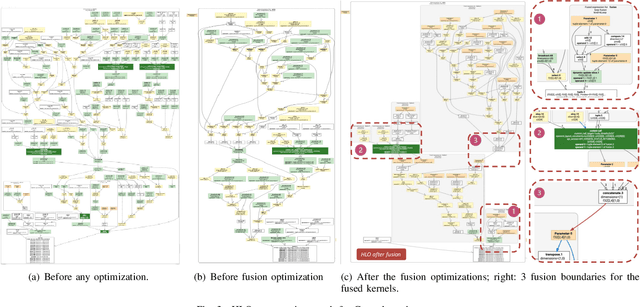

Machine learning (ML) compilers are an active area of research because they offer the potential to automatically speedup tensor programs. Kernel fusion is often cited as an important optimization performed by ML compilers. However, there exists a knowledge gap about how XLA, the most common ML compiler, applies this nuanced optimization, what kind of speedup it can afford, and what low-level effects it has on hardware. Our paper aims to bridge this knowledge gap by studying key compiler passes of XLA's source code. Our evaluation on a reinforcement learning environment Cartpole shows how different fusion decisions in XLA are made in practice. Furthermore, we implement several XLA kernel fusion strategies that can achieve up to 10.56x speedup compared to our baseline implementation.
Optimizing Data Collection in Deep Reinforcement Learning
Jul 15, 2022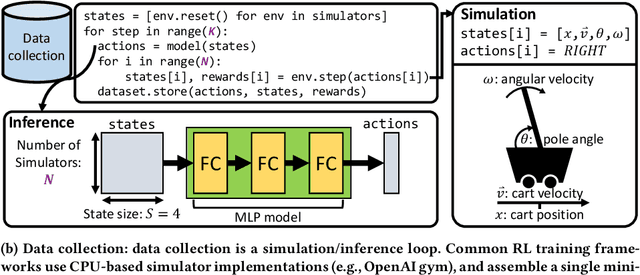
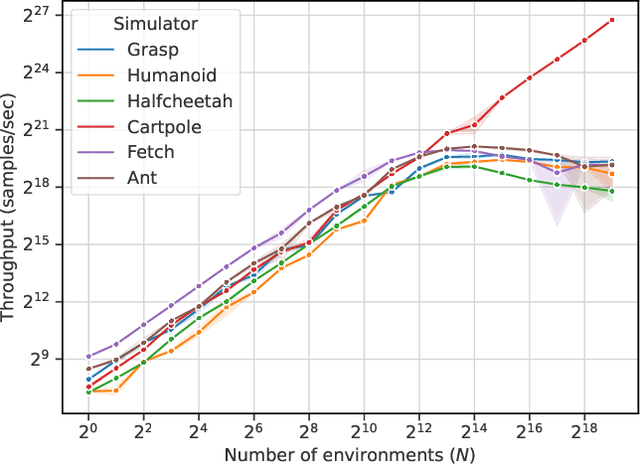
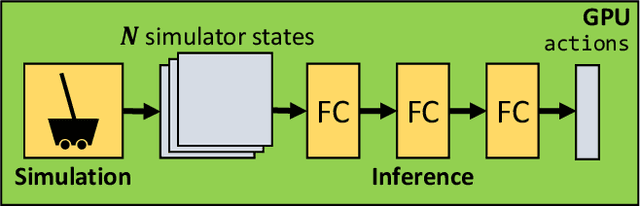
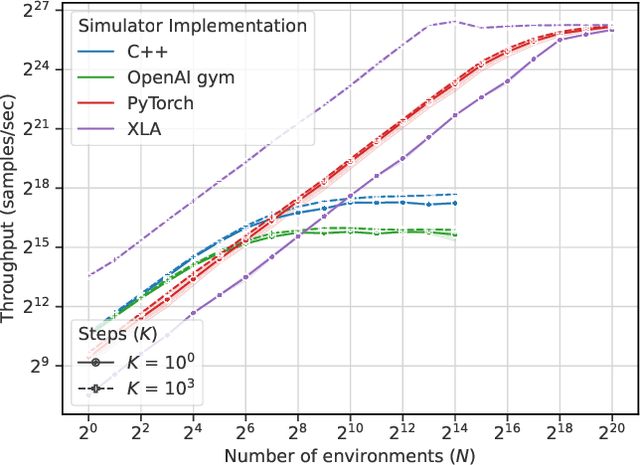
Reinforcement learning (RL) workloads take a notoriously long time to train due to the large number of samples collected at run-time from simulators. Unfortunately, cluster scale-up approaches remain expensive, and commonly used CPU implementations of simulators induce high overhead when switching back and forth between GPU computations. We explore two optimizations that increase RL data collection efficiency by increasing GPU utilization: (1) GPU vectorization: parallelizing simulation on the GPU for increased hardware parallelism, and (2) simulator kernel fusion: fusing multiple simulation steps to run in a single GPU kernel launch to reduce global memory bandwidth requirements. We find that GPU vectorization can achieve up to $1024\times$ speedup over commonly used CPU simulators. We profile the performance of different implementations and show that for a simple simulator, ML compiler implementations (XLA) of GPU vectorization outperform a DNN framework (PyTorch) by $13.4\times$ by reducing CPU overhead from repeated Python to DL backend API calls. We show that simulator kernel fusion speedups with a simple simulator are $11.3\times$ and increase by up to $1024\times$ as simulator complexity increases in terms of memory bandwidth requirements. We show that the speedups from simulator kernel fusion are orthogonal and combinable with GPU vectorization, leading to a multiplicative speedup.