 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Multimodal LLMs Solve the Basic Perception Problems of Percept-V?
Aug 28, 2025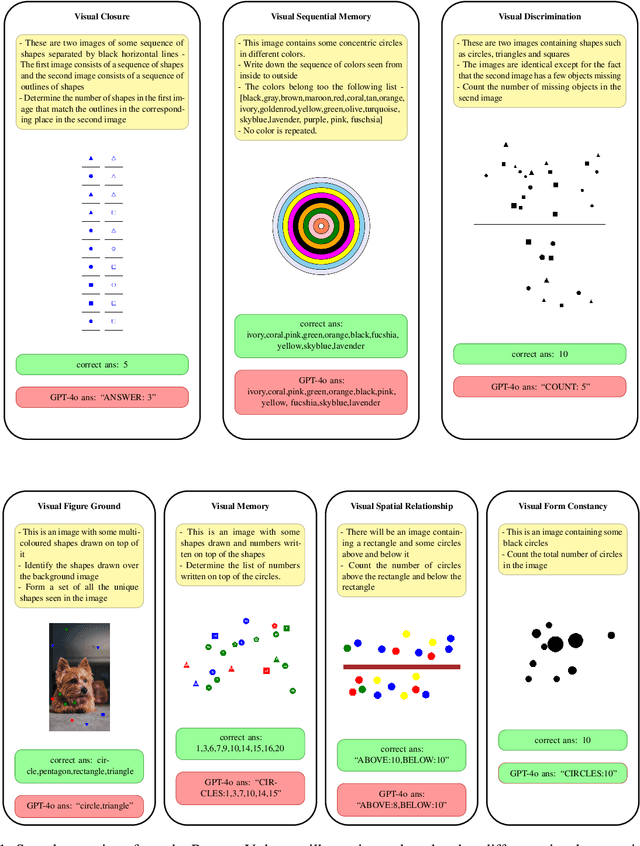
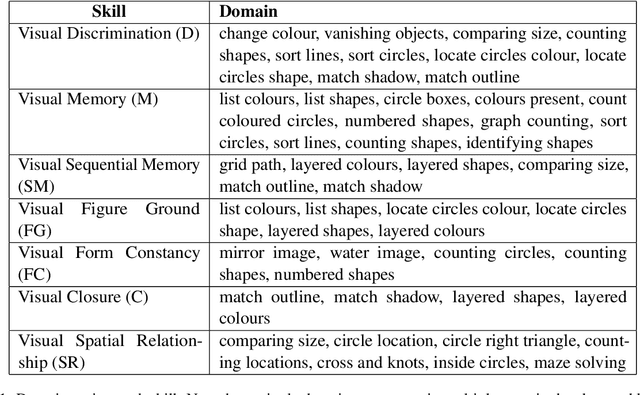

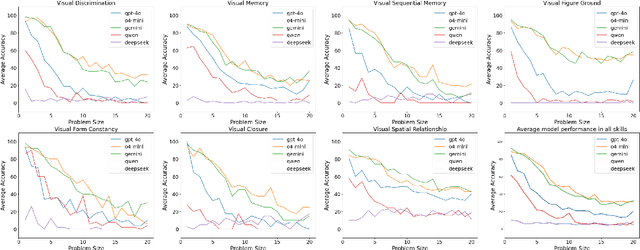
The reasoning abilities of Multimodal Large Language Models (MLLMs) have garnered a lot of attention in recent times, with advances made in frontiers like coding, mathematics, and science. However, very limited experiments have been done to assess their performance in simple perception tasks performed over uncontaminated, generated images containing basic shapes and structures. To address this issue, the paper introduces a dataset, Percept-V, containing a total of 7200 program-generated images equally divided into 30 categories, each testing a combination of visual perception skills. Unlike previously proposed datasets, Percept-V comprises very basic tasks of varying complexity that test the perception abilities of MLLMs. This dataset is then tested on state-of-the-art MLLMs like GPT-4o, Gemini, and Claude as well as Large Reasoning Models (LRMs) like OpenAI o4-mini and DeepSeek R1 to gauge their performance. Contrary to the evidence that MLLMs excel in many complex tasks, our experiments show a significant drop in the models' performance with increasing problem complexity across all categories. An analysis of the performances also reveals that the tested MLLMs exhibit a similar trend in accuracy across categories, testing a particular cognitive skill and find some skills to be more difficult than others.
How far away are truly hyperparameter-free learning algorithms?
May 29, 2025Despite major advances in methodology, hyperparameter tuning remains a crucial (and expensive) part of the development of machine learning systems. Even ignoring architectural choices, deep neural networks have a large number of optimization and regularization hyperparameters that need to be tuned carefully per workload in order to obtain the best results. In a perfect world, training algorithms would not require workload-specific hyperparameter tuning, but would instead have default settings that performed well across many workloads. Recently, there has been a growing literature on optimization methods which attempt to reduce the number of hyperparameters -- particularly the learning rate and its accompanying schedule. Given these developments, how far away is the dream of neural network training algorithms that completely obviate the need for painful tuning? In this paper, we evaluate the potential of learning-rate-free methods as components of hyperparameter-free methods. We freeze their (non-learning rate) hyperparameters to default values, and score their performance using the recently-proposed AlgoPerf: Training Algorithms benchmark. We found that literature-supplied default settings performed poorly on the benchmark, so we performed a search for hyperparameter configurations that performed well across all workloads simultaneously. The best AlgoPerf-calibrated learning-rate-free methods had much improved performance but still lagged slightly behind a similarly calibrated NadamW baseline in overall benchmark score. Our results suggest that there is still much room for improvement for learning-rate-free methods, and that testing against a strong, workload-agnostic baseline is important to improve hyperparameter reduction techniques.
Training neural networks faster with minimal tuning using pre-computed lists of hyperparameters for NAdamW
Mar 06, 2025



If we want to train a neural network using any of the most popular optimization algorithms, we are immediately faced with a dilemma: how to set the various optimization and regularization hyperparameters? When computational resources are abundant, there are a variety of methods for finding good hyperparameter settings, but when resources are limited the only realistic choices are using standard default values of uncertain quality and provenance, or tuning only a couple of the most important hyperparameters via extremely limited handdesigned sweeps. Extending the idea of default settings to a modest tuning budget, Metz et al. (2020) proposed using ordered lists of well-performing hyperparameter settings, derived from a broad hyperparameter search on a large library of training workloads. However, to date, no practical and performant hyperparameter lists that generalize to representative deep learning workloads have been demonstrated. In this paper, we present hyperparameter lists for NAdamW derived from extensive experiments on the realistic workloads in the AlgoPerf: Training Algorithms benchmark. Our hyperparameter lists also include values for basic regularization techniques (i.e. weight decay, label smoothing, and dropout). In particular, our best NAdamW hyperparameter list performs well on AlgoPerf held-out workloads not used to construct it, and represents a compelling turn-key approach to tuning when restricted to five or fewer trials. It also outperforms basic learning rate/weight decay sweeps and an off-the-shelf Bayesian optimization tool when restricted to the same budget.
Provable Length Generalization in Sequence Prediction via Spectral Filtering
Nov 01, 2024



We consider the problem of length generalization in sequence prediction. We define a new metric of performance in this setting -- the Asymmetric-Regret -- which measures regret against a benchmark predictor with longer context length than available to the learner. We continue by studying this concept through the lens of the spectral filtering algorithm. We present a gradient-based learning algorithm that provably achieves length generalization for linear dynamical systems. We conclude with proof-of-concept experiments which are consistent with our theory.
FutureFill: Fast Generation from Convolutional Sequence Models
Oct 02, 2024



We address the challenge of efficient auto-regressive generation in sequence prediction models by introducing FutureFill: a method for fast generation that applies to any sequence prediction algorithm based on convolutional operators. Our approach reduces the generation time requirement from linear to square root relative to the context length. Additionally, FutureFill requires a prefill cache sized only by the number of tokens generated, which is smaller than the cache requirements for standard convolutional and attention-based models. We validate our theoretical findings with experimental evidence demonstrating correctness and efficiency gains in a synthetic generation task.
Stacking as Accelerated Gradient Descent
Mar 08, 2024



Stacking, a heuristic technique for training deep residual networks by progressively increasing the number of layers and initializing new layers by copying parameters from older layers, has proven quite successful in improving the efficiency of training deep neural networks. In this paper, we propose a theoretical explanation for the efficacy of stacking: viz., stacking implements a form of Nesterov's accelerated gradient descent. The theory also covers simpler models such as the additive ensembles constructed in boosting methods, and provides an explanation for a similar widely-used practical heuristic for initializing the new classifier in each round of boosting. We also prove that for certain deep linear residual networks, stacking does provide accelerated training, via a new potential function analysis of the Nesterov's accelerated gradient method which allows errors in updates. We conduct proof-of-concept experiments to validate our theory as well.
Towards Quantifying the Preconditioning Effect of Adam
Feb 11, 2024There is a notable dearth of results characterizing the preconditioning effect of Adam and showing how it may alleviate the curse of ill-conditioning -- an issue plaguing gradient descent (GD). In this work, we perform a detailed analysis of Adam's preconditioning effect for quadratic functions and quantify to what extent Adam can mitigate the dependence on the condition number of the Hessian. Our key finding is that Adam can suffer less from the condition number but at the expense of suffering a dimension-dependent quantity. Specifically, for a $d$-dimensional quadratic with a diagonal Hessian having condition number $\kappa$, we show that the effective condition number-like quantity controlling the iteration complexity of Adam without momentum is $\mathcal{O}(\min(d, \kappa))$. For a diagonally dominant Hessian, we obtain a bound of $\mathcal{O}(\min(d \sqrt{d \kappa}, \kappa))$ for the corresponding quantity. Thus, when $d < \mathcal{O}(\kappa^p)$ where $p = 1$ for a diagonal Hessian and $p = 1/3$ for a diagonally dominant Hessian, Adam can outperform GD (which has an $\mathcal{O}(\kappa)$ dependence). On the negative side, our results suggest that Adam can be worse than GD for a sufficiently non-diagonal Hessian even if $d \ll \mathcal{O}(\kappa^{1/3})$; we corroborate this with empirical evidence. Finally, we extend our analysis to functions satisfying per-coordinate Lipschitz smoothness and a modified version of the Polyak-\L ojasiewicz condition.
Improved Differentially Private and Lazy Online Convex Optimization
Dec 20, 2023We study the task of $(\epsilon, \delta)$-differentially private online convex optimization (OCO). In the online setting, the release of each distinct decision or iterate carries with it the potential for privacy loss. This problem has a long history of research starting with Jain et al. [2012] and the best known results for the regime of {\epsilon} not being very small are presented in Agarwal et al. [2023]. In this paper we improve upon the results of Agarwal et al. [2023] in terms of the dimension factors as well as removing the requirement of smoothness. Our results are now the best known rates for DP-OCO in this regime. Our algorithms builds upon the work of [Asi et al., 2023] which introduced the idea of explicitly limiting the number of switches via rejection sampling. The main innovation in our algorithm is the use of sampling from a strongly log-concave density which allows us to trade-off the dimension factors better leading to improved results.
Spectral State Space Models
Dec 11, 2023



This paper studies sequence modeling for prediction tasks with long range dependencies. We propose a new formulation for state space models based on learning linear dynamical systems with the spectral filtering algorithm [HSZ17]. This gives rise to a novel sequence prediction architecture we call spectral state space models. The resulting models are evaluated on synthetic dynamical systems. These evaluations support the theoretical benefits of spectral filtering for tasks requiring very long range memory.
HAVE-Net: Hallucinated Audio-Visual Embeddings for Few-Shot Classification with Unimodal Cues
Sep 23, 2023Recognition of remote sensing (RS) or aerial images is currently of great interest, and advancements in deep learning algorithms added flavor to it in recent years. Occlusion, intra-class variance, lighting, etc., might arise while training neural networks using unimodal RS visual input. Even though joint training of audio-visual modalities improves classification performance in a low-data regime, it has yet to be thoroughly investigated in the RS domain. Here, we aim to solve a novel problem where both the audio and visual modalities are present during the meta-training of a few-shot learning (FSL) classifier; however, one of the modalities might be missing during the meta-testing stage. This problem formulation is pertinent in the RS domain, given the difficulties in data acquisition or sensor malfunctioning. To mitigate, we propose a novel few-shot generative framework, Hallucinated Audio-Visual Embeddings-Network (HAVE-Net), to meta-train cross-modal features from limited unimodal data. Precisely, these hallucinated features are meta-learned from base classes and used for few-shot classification on novel classes during the inference phase. The experimental results on the benchmark ADVANCE and AudioSetZSL datasets show that our hallucinated modality augmentation strategy for few-shot classification outperforms the classifier performance trained with the real multimodal information at least by 0.8-2%.