 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Language Models are Secretly Energy-Based Models: Insights into the Lookahead Capabilities of Next-Token Prediction
Dec 17, 2025Autoregressive models (ARMs) currently constitute the dominant paradigm for large language models (LLMs). Energy-based models (EBMs) represent another class of models, which have historically been less prevalent in LLM development, yet naturally characterize the optimal policy in post-training alignment. In this paper, we provide a unified view of these two model classes. Taking the chain rule of probability as a starting point, we establish an explicit bijection between ARMs and EBMs in function space, which we show to correspond to a special case of the soft Bellman equation in maximum entropy reinforcement learning. Building upon this bijection, we derive the equivalence between supervised learning of ARMs and EBMs. Furthermore, we analyze the distillation of EBMs into ARMs by providing theoretical error bounds. Our results provide insights into the ability of ARMs to plan ahead, despite being based on the next-token prediction paradigm.
How far away are truly hyperparameter-free learning algorithms?
May 29, 2025Despite major advances in methodology, hyperparameter tuning remains a crucial (and expensive) part of the development of machine learning systems. Even ignoring architectural choices, deep neural networks have a large number of optimization and regularization hyperparameters that need to be tuned carefully per workload in order to obtain the best results. In a perfect world, training algorithms would not require workload-specific hyperparameter tuning, but would instead have default settings that performed well across many workloads. Recently, there has been a growing literature on optimization methods which attempt to reduce the number of hyperparameters -- particularly the learning rate and its accompanying schedule. Given these developments, how far away is the dream of neural network training algorithms that completely obviate the need for painful tuning? In this paper, we evaluate the potential of learning-rate-free methods as components of hyperparameter-free methods. We freeze their (non-learning rate) hyperparameters to default values, and score their performance using the recently-proposed AlgoPerf: Training Algorithms benchmark. We found that literature-supplied default settings performed poorly on the benchmark, so we performed a search for hyperparameter configurations that performed well across all workloads simultaneously. The best AlgoPerf-calibrated learning-rate-free methods had much improved performance but still lagged slightly behind a similarly calibrated NadamW baseline in overall benchmark score. Our results suggest that there is still much room for improvement for learning-rate-free methods, and that testing against a strong, workload-agnostic baseline is important to improve hyperparameter reduction techniques.
Joint Learning of Energy-based Models and their Partition Function
Jan 30, 2025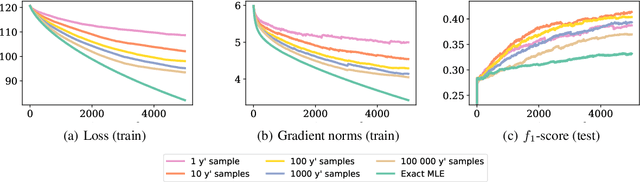
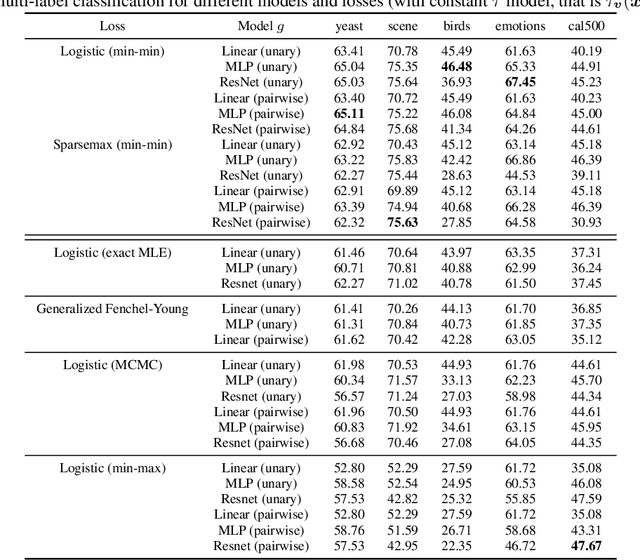
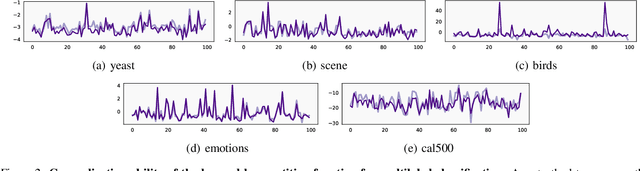
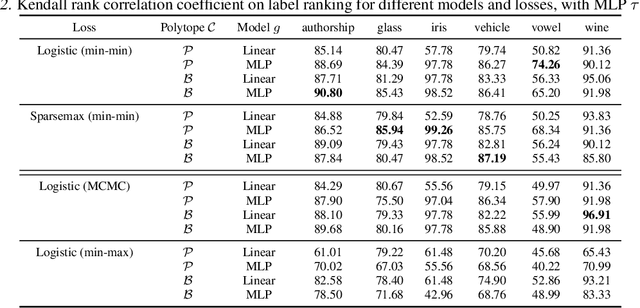
Energy-based models (EBMs) offer a flexible framework for parameterizing probability distributions using neural networks. However, learning EBMs by exact maximum likelihood estimation (MLE) is generally intractable, due to the need to compute the partition function (normalization constant). In this paper, we propose a novel formulation for approximately learning probabilistic EBMs in combinatorially-large discrete spaces, such as sets or permutations. Our key idea is to jointly learn both an energy model and its log-partition, both parameterized as a neural network. Our approach not only provides a novel tractable objective criterion to learn EBMs by stochastic gradient descent (without relying on MCMC), but also a novel means to estimate the log-partition function on unseen data points. On the theoretical side, we show that our approach recovers the optimal MLE solution when optimizing in the space of continuous functions. Furthermore, we show that our approach naturally extends to the broader family of Fenchel-Young losses, allowing us to obtain the first tractable method for optimizing the sparsemax loss in combinatorially-large spaces. We demonstrate our approach on multilabel classification and label ranking.
Loss Functions and Operators Generated by f-Divergences
Jan 30, 2025The logistic loss (a.k.a. cross-entropy loss) is one of the most popular loss functions used for multiclass classification. It is also the loss function of choice for next-token prediction in language modeling. It is associated with the Kullback--Leibler (KL) divergence and the softargmax operator. In this work, we propose to construct new convex loss functions based on $f$-divergences. Our loss functions generalize the logistic loss in two directions: i) by replacing the KL divergence with $f$-divergences and ii) by allowing non-uniform reference measures. We instantiate our framework for numerous $f$-divergences, recovering existing losses and creating new ones. By analogy with the logistic loss, the loss function generated by an $f$-divergence is associated with an operator, that we dub $f$-softargmax. We derive a novel parallelizable bisection algorithm for computing the $f$-softargmax associated with any $f$-divergence. On the empirical side, one of the goals of this paper is to determine the effectiveness of loss functions beyond the classical cross-entropy in a language model setting, including on pre-training, post-training (SFT) and distillation. We show that the loss function generated by the $\alpha$-divergence (which is equivalent to Tsallis $\alpha$-negentropy in the case of unit reference measures) with $\alpha=1.5$ performs well across several tasks.
Stepping on the Edge: Curvature Aware Learning Rate Tuners
Jul 08, 2024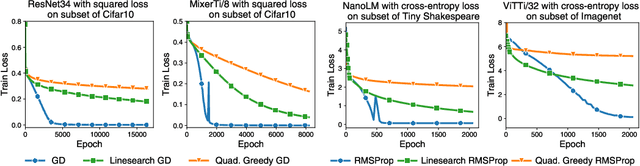
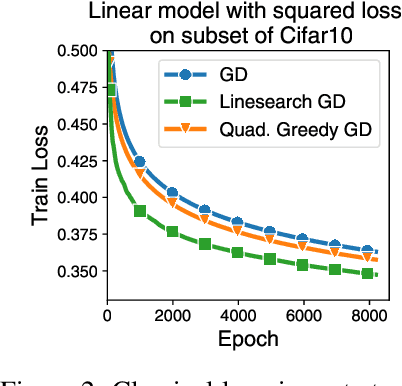
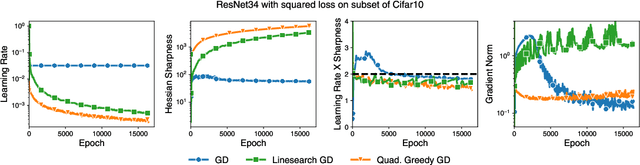
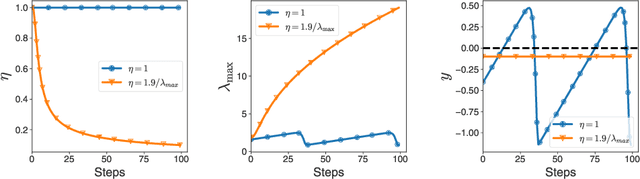
Curvature information -- particularly, the largest eigenvalue of the loss Hessian, known as the sharpness -- often forms the basis for learning rate tuners. However, recent work has shown that the curvature information undergoes complex dynamics during training, going from a phase of increasing sharpness to eventual stabilization. We analyze the closed-loop feedback effect between learning rate tuning and curvature. We find that classical learning rate tuners may yield greater one-step loss reduction, yet they ultimately underperform in the long term when compared to constant learning rates in the full batch regime. These models break the stabilization of the sharpness, which we explain using a simplified model of the joint dynamics of the learning rate and the curvature. To further investigate these effects, we introduce a new learning rate tuning method, Curvature Dynamics Aware Tuning (CDAT), which prioritizes long term curvature stabilization over instantaneous progress on the objective. In the full batch regime, CDAT shows behavior akin to prefixed warm-up schedules on deep learning objectives, outperforming tuned constant learning rates. In the mini batch regime, we observe that stochasticity introduces confounding effects that explain the previous success of some learning rate tuners at appropriate batch sizes. Our findings highlight the critical role of understanding the joint dynamics of the learning rate and curvature, beyond greedy minimization, to diagnose failures and design effective adaptive learning rate tuners.
The Elements of Differentiable Programming
Mar 21, 2024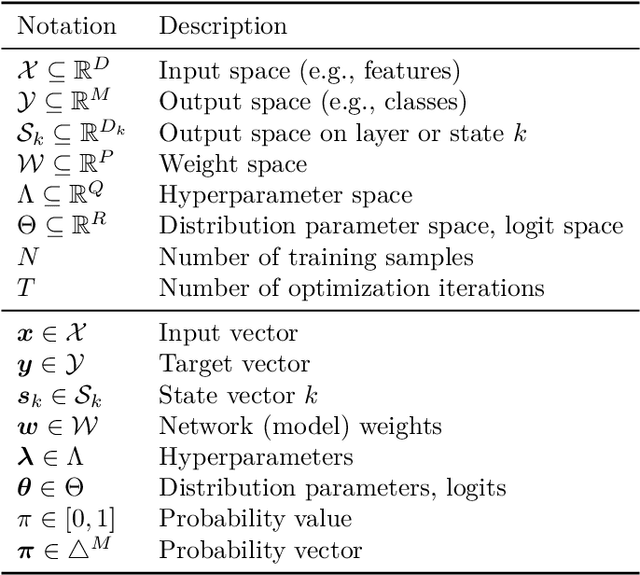
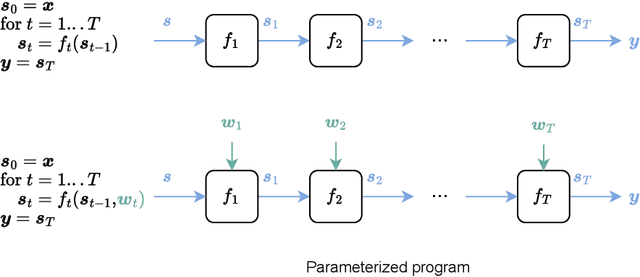

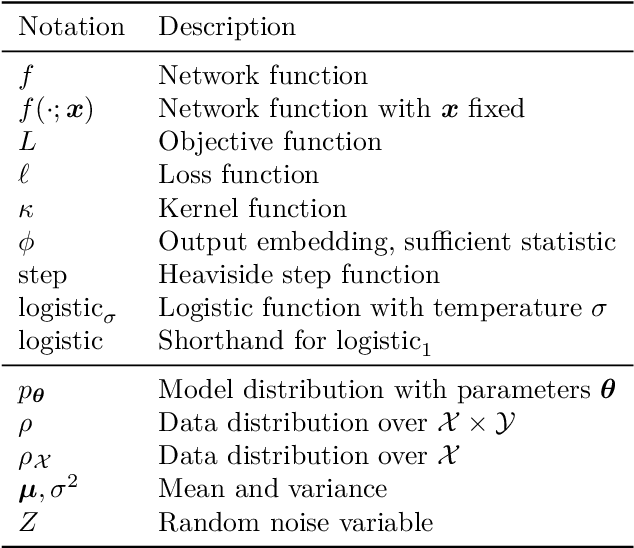
Artificial intelligence has recently experienced remarkable advances, fueled by large models, vast datasets, accelerated hardware, and, last but not least, the transformative power of differentiable programming. This new programming paradigm enables end-to-end differentiation of complex computer programs (including those with control flows and data structures), making gradient-based optimization of program parameters possible. As an emerging paradigm, differentiable programming builds upon several areas of computer science and applied mathematics, including automatic differentiation, graphical models, optimization and statistics. This book presents a comprehensive review of the fundamental concepts useful for differentiable programming. We adopt two main perspectives, that of optimization and that of probability, with clear analogies between the two. Differentiable programming is not merely the differentiation of programs, but also the thoughtful design of programs intended for differentiation. By making programs differentiable, we inherently introduce probability distributions over their execution, providing a means to quantify the uncertainty associated with program outputs.
On the Interplay Between Stepsize Tuning and Progressive Sharpening
Dec 07, 2023



Recent empirical work has revealed an intriguing property of deep learning models by which the sharpness (largest eigenvalue of the Hessian) increases throughout optimization until it stabilizes around a critical value at which the optimizer operates at the edge of stability, given a fixed stepsize (Cohen et al, 2022). We investigate empirically how the sharpness evolves when using stepsize-tuners, the Armijo linesearch and Polyak stepsizes, that adapt the stepsize along the iterations to local quantities such as, implicitly, the sharpness itself. We find that the surprisingly poor performance of a classical Armijo linesearch may be well explained by its tendency to ever-increase the sharpness of the objective in the full or large batch regimes. On the other hand, we observe that Polyak stepsizes operate generally at the edge of stability or even slightly beyond, while outperforming its Armijo and constant stepsizes counterparts. We conclude with an analysis that suggests unlocking stepsize tuners requires an understanding of the joint dynamics of the step size and the sharpness.
Distributionally Robust Optimization with Bias and Variance Reduction
Oct 21, 2023



We consider the distributionally robust optimization (DRO) problem with spectral risk-based uncertainty set and $f$-divergence penalty. This formulation includes common risk-sensitive learning objectives such as regularized condition value-at-risk (CVaR) and average top-$k$ loss. We present Prospect, a stochastic gradient-based algorithm that only requires tuning a single learning rate hyperparameter, and prove that it enjoys linear convergence for smooth regularized losses. This contrasts with previous algorithms that either require tuning multiple hyperparameters or potentially fail to converge due to biased gradient estimates or inadequate regularization. Empirically, we show that Prospect can converge 2-3$\times$ faster than baselines such as stochastic gradient and stochastic saddle-point methods on distribution shift and fairness benchmarks spanning tabular, vision, and language domains.
Dual Gauss-Newton Directions for Deep Learning
Aug 17, 2023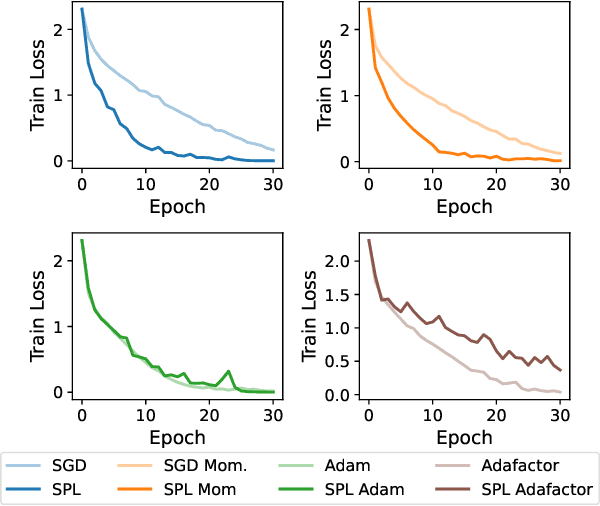
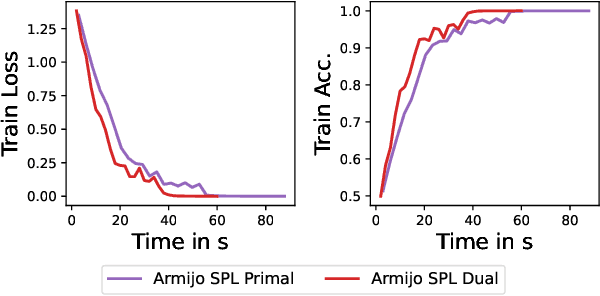
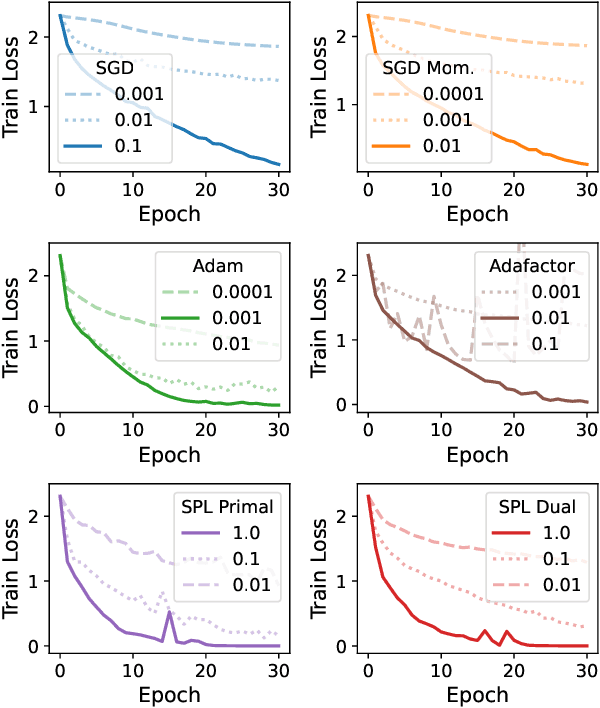
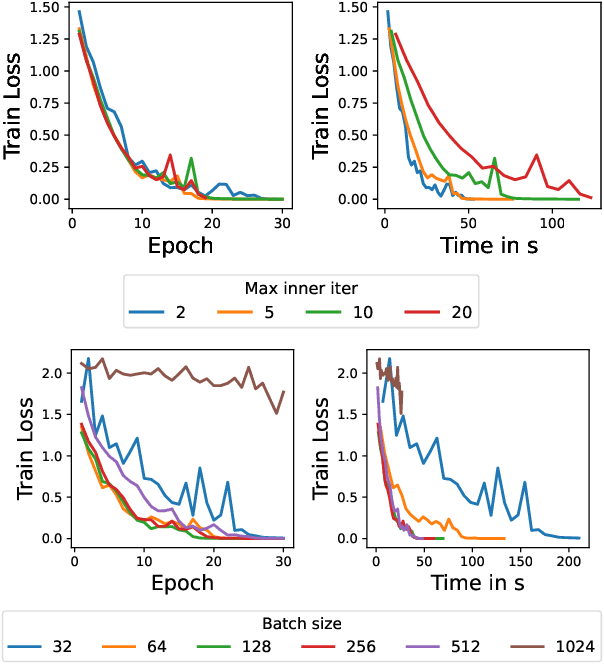
Inspired by Gauss-Newton-like methods, we study the benefit of leveraging the structure of deep learning objectives, namely, the composition of a convex loss function and of a nonlinear network, in order to derive better direction oracles than stochastic gradients, based on the idea of partial linearization. In a departure from previous works, we propose to compute such direction oracles via their dual formulation, leading to both computational benefits and new insights. We demonstrate that the resulting oracles define descent directions that can be used as a drop-in replacement for stochastic gradients, in existing optimization algorithms. We empirically study the advantage of using the dual formulation as well as the computational trade-offs involved in the computation of such oracles.
Modified Gauss-Newton Algorithms under Noise
May 18, 2023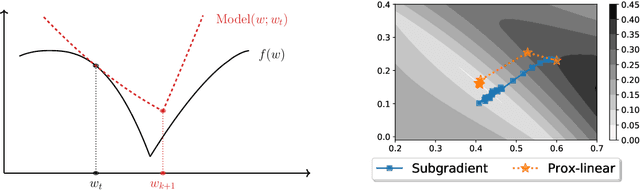
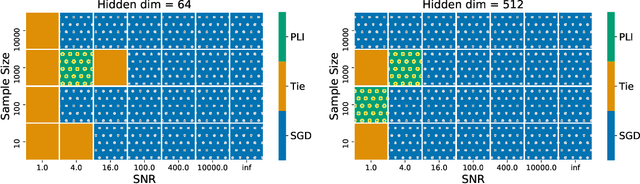
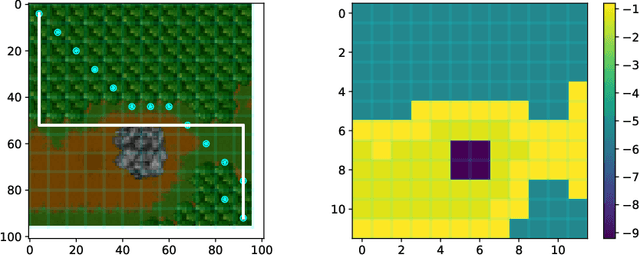
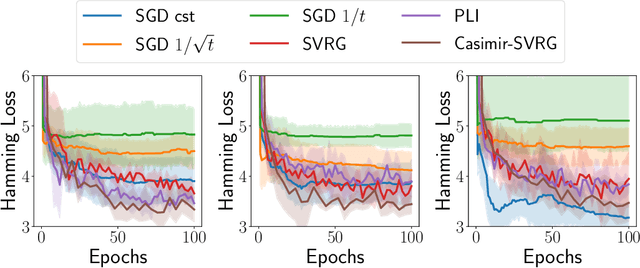
Gauss-Newton methods and their stochastic version have been widely used in machine learning and signal processing. Their nonsmooth counterparts, modified Gauss-Newton or prox-linear algorithms, can lead to contrasting outcomes when compared to gradient descent in large-scale statistical settings. We explore the contrasting performance of these two classes of algorithms in theory on a stylized statistical example, and experimentally on learning problems including structured prediction. In theory, we delineate the regime where the quadratic convergence of the modified Gauss-Newton method is active under statistical noise. In the experiments, we underline the versatility of stochastic (sub)-gradient descent to minimize nonsmooth composite objectives.