 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Language Models are Secretly Energy-Based Models: Insights into the Lookahead Capabilities of Next-Token Prediction
Dec 17, 2025Autoregressive models (ARMs) currently constitute the dominant paradigm for large language models (LLMs). Energy-based models (EBMs) represent another class of models, which have historically been less prevalent in LLM development, yet naturally characterize the optimal policy in post-training alignment. In this paper, we provide a unified view of these two model classes. Taking the chain rule of probability as a starting point, we establish an explicit bijection between ARMs and EBMs in function space, which we show to correspond to a special case of the soft Bellman equation in maximum entropy reinforcement learning. Building upon this bijection, we derive the equivalence between supervised learning of ARMs and EBMs. Furthermore, we analyze the distillation of EBMs into ARMs by providing theoretical error bounds. Our results provide insights into the ability of ARMs to plan ahead, despite being based on the next-token prediction paradigm.
Loss Functions and Operators Generated by f-Divergences
Jan 30, 2025The logistic loss (a.k.a. cross-entropy loss) is one of the most popular loss functions used for multiclass classification. It is also the loss function of choice for next-token prediction in language modeling. It is associated with the Kullback--Leibler (KL) divergence and the softargmax operator. In this work, we propose to construct new convex loss functions based on $f$-divergences. Our loss functions generalize the logistic loss in two directions: i) by replacing the KL divergence with $f$-divergences and ii) by allowing non-uniform reference measures. We instantiate our framework for numerous $f$-divergences, recovering existing losses and creating new ones. By analogy with the logistic loss, the loss function generated by an $f$-divergence is associated with an operator, that we dub $f$-softargmax. We derive a novel parallelizable bisection algorithm for computing the $f$-softargmax associated with any $f$-divergence. On the empirical side, one of the goals of this paper is to determine the effectiveness of loss functions beyond the classical cross-entropy in a language model setting, including on pre-training, post-training (SFT) and distillation. We show that the loss function generated by the $\alpha$-divergence (which is equivalent to Tsallis $\alpha$-negentropy in the case of unit reference measures) with $\alpha=1.5$ performs well across several tasks.
Joint Learning of Energy-based Models and their Partition Function
Jan 30, 2025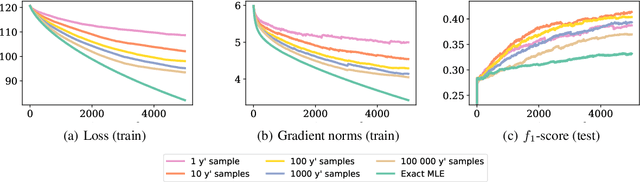
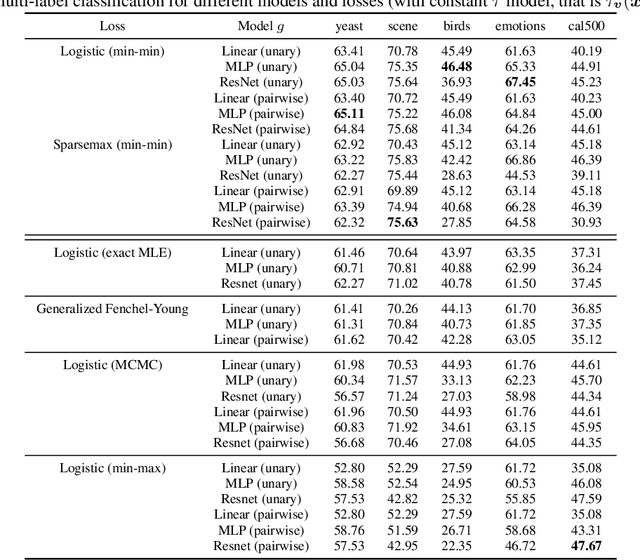
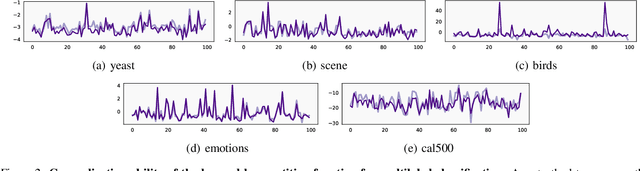
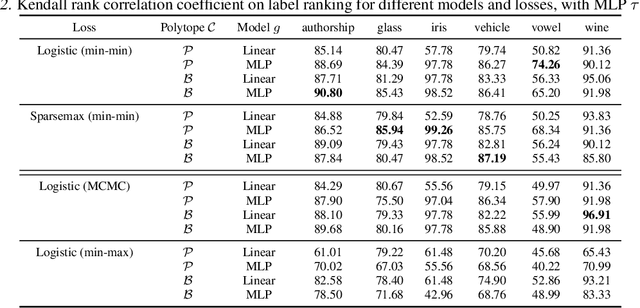
Energy-based models (EBMs) offer a flexible framework for parameterizing probability distributions using neural networks. However, learning EBMs by exact maximum likelihood estimation (MLE) is generally intractable, due to the need to compute the partition function (normalization constant). In this paper, we propose a novel formulation for approximately learning probabilistic EBMs in combinatorially-large discrete spaces, such as sets or permutations. Our key idea is to jointly learn both an energy model and its log-partition, both parameterized as a neural network. Our approach not only provides a novel tractable objective criterion to learn EBMs by stochastic gradient descent (without relying on MCMC), but also a novel means to estimate the log-partition function on unseen data points. On the theoretical side, we show that our approach recovers the optimal MLE solution when optimizing in the space of continuous functions. Furthermore, we show that our approach naturally extends to the broader family of Fenchel-Young losses, allowing us to obtain the first tractable method for optimizing the sparsemax loss in combinatorially-large spaces. We demonstrate our approach on multilabel classification and label ranking.
Adaptive Methods through the Lens of SDEs: Theoretical Insights on the Role of Noise
Nov 24, 2024Despite the vast empirical evidence supporting the efficacy of adaptive optimization methods in deep learning, their theoretical understanding is far from complete. This work introduces novel SDEs for commonly used adaptive optimizers: SignSGD, RMSprop(W), and Adam(W). These SDEs offer a quantitatively accurate description of these optimizers and help illuminate an intricate relationship between adaptivity, gradient noise, and curvature. Our novel analysis of SignSGD highlights a noteworthy and precise contrast to SGD in terms of convergence speed, stationary distribution, and robustness to heavy-tail noise. We extend this analysis to AdamW and RMSpropW, for which we observe that the role of noise is much more complex. Crucially, we support our theoretical analysis with experimental evidence by verifying our insights: this includes numerically integrating our SDEs using Euler-Maruyama discretization on various neural network architectures such as MLPs, CNNs, ResNets, and Transformers. Our SDEs accurately track the behavior of the respective optimizers, especially when compared to previous SDEs derived for Adam and RMSprop. We believe our approach can provide valuable insights into best training practices and novel scaling rules.
LoFi: Scalable Local Image Reconstruction with Implicit Neural Representation
Nov 07, 2024Neural fields or implicit neural representations (INRs) have attracted significant attention in machine learning and signal processing due to their efficient continuous representation of images and 3D volumes. In this work, we build on INRs and introduce a coordinate-based local processing framework for solving imaging inverse problems, termed LoFi (Local Field). Unlike conventional methods for image reconstruction, LoFi processes local information at each coordinate \textit{separately} by multi-layer perceptrons (MLPs), recovering the object at that specific coordinate. Similar to INRs, LoFi can recover images at any continuous coordinate, enabling image reconstruction at multiple resolutions. With comparable or better performance than standard CNNs for image reconstruction, LoFi achieves excellent generalization to out-of-distribution data and memory usage almost independent of image resolution. Remarkably, training on $1024 \times 1024$ images requires just 3GB of memory -- over 20 times less than the memory typically needed by standard CNNs. Additionally, LoFi's local design allows it to train on extremely small datasets with less than 10 samples, without overfitting or the need for regularization or early stopping. Finally, we use LoFi as a denoising prior in a plug-and-play framework for solving general inverse problems to benefit from its continuous image representation and strong generalization. Although trained on low-resolution images, LoFi can be used as a low-dimensional prior to solve inverse problems at any resolution. We validate our framework across a variety of imaging modalities, from low-dose computed tomography to radio interferometric imaging.
SeisLM: a Foundation Model for Seismic Waveforms
Oct 21, 2024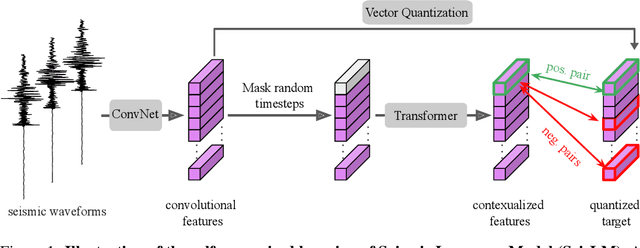
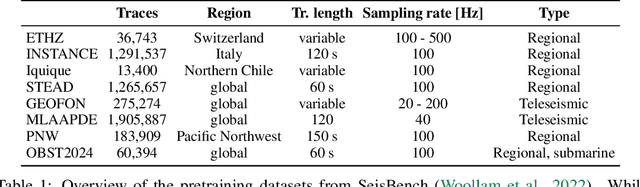
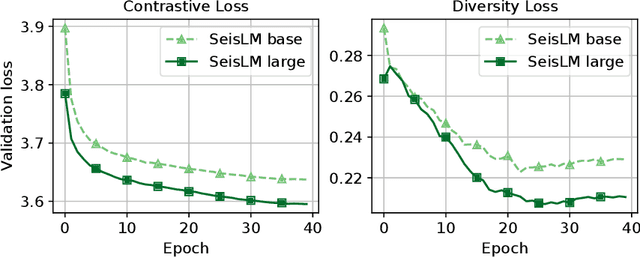
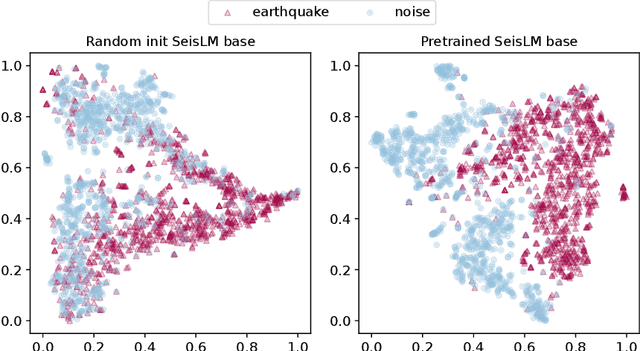
We introduce the Seismic Language Model (SeisLM), a foundational model designed to analyze seismic waveforms -- signals generated by Earth's vibrations such as the ones originating from earthquakes. SeisLM is pretrained on a large collection of open-source seismic datasets using a self-supervised contrastive loss, akin to BERT in language modeling. This approach allows the model to learn general seismic waveform patterns from unlabeled data without being tied to specific downstream tasks. When fine-tuned, SeisLM excels in seismological tasks like event detection, phase-picking, onset time regression, and foreshock-aftershock classification. The code has been made publicly available on https://github.com/liutianlin0121/seisLM.
State Estimation Transformers for Agile Legged Locomotion
Oct 17, 2024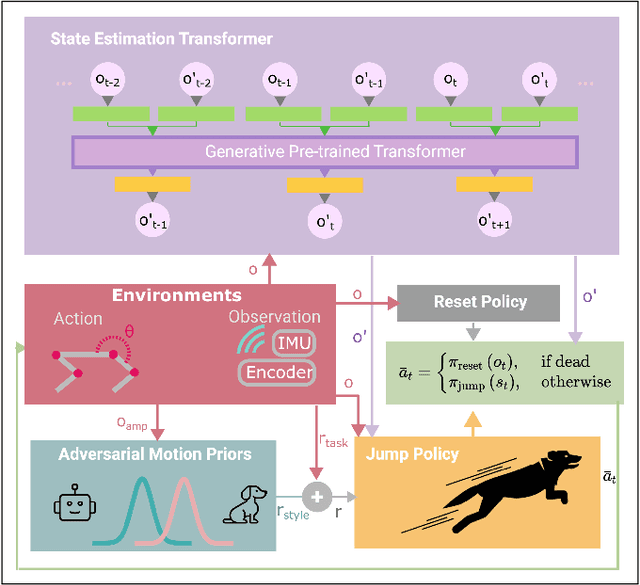
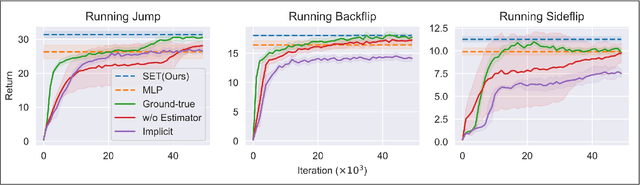

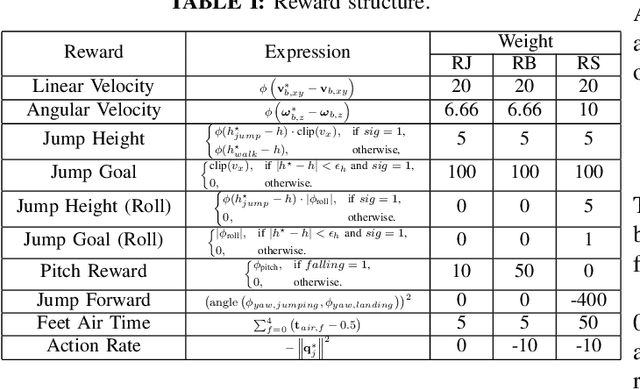
We propose a state estimation method that can accurately predict the robot's privileged states to push the limits of quadruped robots in executing advanced skills such as jumping in the wild. In particular, we present the State Estimation Transformers (SET), an architecture that casts the state estimation problem as conditional sequence modeling. SET outputs the robot states that are hard to obtain directly in the real world, such as the body height and velocities, by leveraging a causally masked Transformer. By conditioning an autoregressive model on the robot's past states, our SET model can predict these privileged observations accurately even in highly dynamic locomotions. We evaluate our methods on three tasks -- running jumping, running backflipping, and running sideslipping -- on a low-cost quadruped robot, Cyberdog2. Results show that SET can outperform other methods in estimation accuracy and transferability in the simulation as well as success rates of jumping and triggering a recovery controller in the real world, suggesting the superiority of such a Transformer-based explicit state estimator in highly dynamic locomotion tasks.
LLMs Assist NLP Researchers: Critique Paper (Meta-)Reviewing
Jun 25, 2024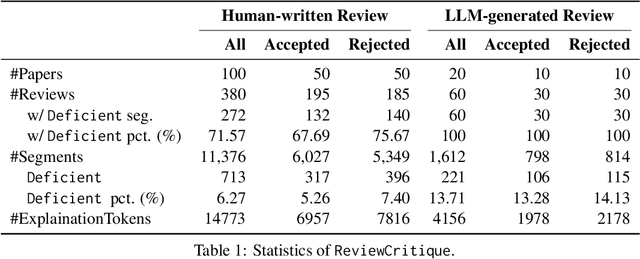
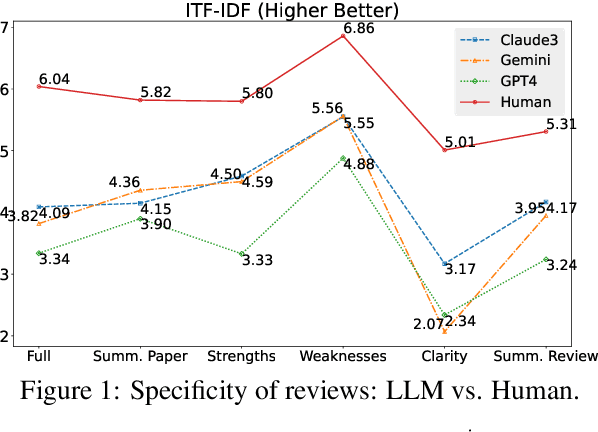

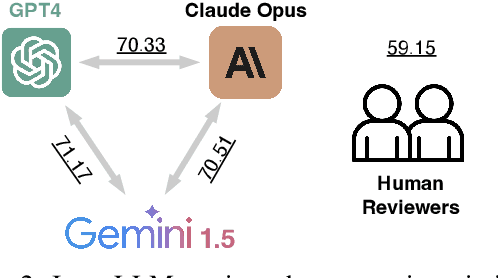
This work is motivated by two key trends. On one hand, large language models (LLMs) have shown remarkable versatility in various generative tasks such as writing, drawing, and question answering, significantly reducing the time required for many routine tasks. On the other hand, researchers, whose work is not only time-consuming but also highly expertise-demanding, face increasing challenges as they have to spend more time reading, writing, and reviewing papers. This raises the question: how can LLMs potentially assist researchers in alleviating their heavy workload? This study focuses on the topic of LLMs assist NLP Researchers, particularly examining the effectiveness of LLM in assisting paper (meta-)reviewing and its recognizability. To address this, we constructed the ReviewCritique dataset, which includes two types of information: (i) NLP papers (initial submissions rather than camera-ready) with both human-written and LLM-generated reviews, and (ii) each review comes with "deficiency" labels and corresponding explanations for individual segments, annotated by experts. Using ReviewCritique, this study explores two threads of research questions: (i) "LLMs as Reviewers", how do reviews generated by LLMs compare with those written by humans in terms of quality and distinguishability? (ii) "LLMs as Metareviewers", how effectively can LLMs identify potential issues, such as Deficient or unprofessional review segments, within individual paper reviews? To our knowledge, this is the first work to provide such a comprehensive analysis.
Direct Language Model Alignment from Online AI Feedback
Feb 07, 2024



Direct alignment from preferences (DAP) methods, such as DPO, have recently emerged as efficient alternatives to reinforcement learning from human feedback (RLHF), that do not require a separate reward model. However, the preference datasets used in DAP methods are usually collected ahead of training and never updated, thus the feedback is purely offline. Moreover, responses in these datasets are often sampled from a language model distinct from the one being aligned, and since the model evolves over training, the alignment phase is inevitably off-policy. In this study, we posit that online feedback is key and improves DAP methods. Our method, online AI feedback (OAIF), uses an LLM as annotator: on each training iteration, we sample two responses from the current model and prompt the LLM annotator to choose which one is preferred, thus providing online feedback. Despite its simplicity, we demonstrate via human evaluation in several tasks that OAIF outperforms both offline DAP and RLHF methods. We further show that the feedback leveraged in OAIF is easily controllable, via instruction prompts to the LLM annotator.
Open RL Benchmark: Comprehensive Tracked Experiments for Reinforcement Learning
Feb 05, 2024



In many Reinforcement Learning (RL) papers, learning curves are useful indicators to measure the effectiveness of RL algorithms. However, the complete raw data of the learning curves are rarely available. As a result, it is usually necessary to reproduce the experiments from scratch, which can be time-consuming and error-prone. We present Open RL Benchmark, a set of fully tracked RL experiments, including not only the usual data such as episodic return, but also all algorithm-specific and system metrics. Open RL Benchmark is community-driven: anyone can download, use, and contribute to the data. At the time of writing, more than 25,000 runs have been tracked, for a cumulative duration of more than 8 years. Open RL Benchmark covers a wide range of RL libraries and reference implementations. Special care is taken to ensure that each experiment is precisely reproducible by providing not only the full parameters, but also the versions of the dependencies used to generate it. In addition, Open RL Benchmark comes with a command-line interface (CLI) for easy fetching and generating figures to present the results. In this document, we include two case studies to demonstrate the usefulness of Open RL Benchmark in practice. To the best of our knowledge, Open RL Benchmark is the first RL benchmark of its kind, and the authors hope that it will improve and facilitate the work of researchers in the field.