 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAIC: Vision-Guided Humanoid Agile Object Interaction Control via Decoupled Commands
Jun 08, 2026Humanoid robots hold immense potential for real-world assistance, yet agile interaction with objects in unstructured environments demands tightly coupled whole-body coordination. Despite recent advancements, current controllers face a critical deployment gap. They rely heavily on dense reference trajectories and perfect state observability, which inherently limits physical generalization. We present Vision Guided Agile Interaction Control (VAIC), a unified framework that bridges this gap by operating exclusively on onboard depth, historical proprioception, and a decoupled user command interface. VAIC employs a two-stage distillation paradigm. First, a privileged teacher policy masters diverse interaction skills using precise object kinematics and exact environmental states. Second, a deployable student policy distills these capabilities by replacing full body tracking with velocity targets across multiple axes and an interaction indicator for each frame. The student utilizes a recurrent object adaptation module to implicitly infer unobservable object dynamics from raw depth streams and proprioception. Evaluations and real-world deployments on the humanoid robot demonstrate that a single VAIC policy successfully executes highly diverse dynamic tasks. These tasks include box carrying, cart interaction, and skateboarding, consistently outperforming baselines and advancing autonomous humanoid deployment.
HAIC: Humanoid Agile Object Interaction Control via Dynamics-Aware World Model
Feb 12, 2026Humanoid robots show promise for complex whole-body tasks in unstructured environments. Although Human-Object Interaction (HOI) has advanced, most methods focus on fully actuated objects rigidly coupled to the robot, ignoring underactuated objects with independent dynamics and non-holonomic constraints. These introduce control challenges from coupling forces and occlusions. We present HAIC, a unified framework for robust interaction across diverse object dynamics without external state estimation. Our key contribution is a dynamics predictor that estimates high-order object states (velocity, acceleration) solely from proprioceptive history. These predictions are projected onto static geometric priors to form a spatially grounded dynamic occupancy map, enabling the policy to infer collision boundaries and contact affordances in blind spots. We use asymmetric fine-tuning, where a world model continuously adapts to the student policy's exploration, ensuring robust state estimation under distribution shifts. Experiments on a humanoid robot show HAIC achieves high success rates in agile tasks (skateboarding, cart pushing/pulling under various loads) by proactively compensating for inertial perturbations, and also masters multi-object long-horizon tasks like carrying a box across varied terrain by predicting the dynamics of multiple objects.
Learning to Manipulate Anything: Revealing Data Scaling Laws in Bounding-Box Guided Policies
Feb 12, 2026Diffusion-based policies show limited generalization in semantic manipulation, posing a key obstacle to the deployment of real-world robots. This limitation arises because relying solely on text instructions is inadequate to direct the policy's attention toward the target object in complex and dynamic environments. To solve this problem, we propose leveraging bounding-box instruction to directly specify target object, and further investigate whether data scaling laws exist in semantic manipulation tasks. Specifically, we design a handheld segmentation device with an automated annotation pipeline, Label-UMI, which enables the efficient collection of demonstration data with semantic labels. We further propose a semantic-motion-decoupled framework that integrates object detection and bounding-box guided diffusion policy to improve generalization and adaptability in semantic manipulation. Throughout extensive real-world experiments on large-scale datasets, we validate the effectiveness of the approach, and reveal a power-law relationship between generalization performance and the number of bounding-box objects. Finally, we summarize an effective data collection strategy for semantic manipulation, which can achieve 85\% success rates across four tasks on both seen and unseen objects. All datasets and code will be released to the community.
RSHallu: Dual-Mode Hallucination Evaluation for Remote-Sensing Multimodal Large Language Models with Domain-Tailored Mitigation
Feb 11, 2026Multimodal large language models (MLLMs) are increasingly adopted in remote sensing (RS) and have shown strong performance on tasks such as RS visual grounding (RSVG), RS visual question answering (RSVQA), and multimodal dialogue. However, hallucinations, which are responses inconsistent with the input RS images, severely hinder their deployment in high-stakes scenarios (e.g., emergency management and agricultural monitoring) and remain under-explored in RS. In this work, we present RSHallu, a systematic study with three deliverables: (1) we formalize RS hallucinations with an RS-oriented taxonomy and introduce image-level hallucination to capture RS-specific inconsistencies beyond object-centric errors (e.g., modality, resolution, and scene-level semantics); (2) we build a hallucination benchmark RSHalluEval (2,023 QA pairs) and enable dual-mode checking, supporting high-precision cloud auditing and low-cost reproducible local checking via a compact checker fine-tuned on RSHalluCheck dataset (15,396 QA pairs); and (3) we introduce a domain-tailored dataset RSHalluShield (30k QA pairs) for training-friendly mitigation and further propose training-free plug-and-play strategies, including decoding-time logit correction and RS-aware prompting. Across representative RS-MLLMs, our mitigation improves the hallucination-free rate by up to 21.63 percentage points under a unified protocol, while maintaining competitive performance on downstream RS tasks (RSVQA/RSVG). Code and datasets will be released.
Learning Diverse Skills for Behavior Models with Mixture of Experts
Jan 18, 2026Imitation learning has demonstrated strong performance in robotic manipulation by learning from large-scale human demonstrations. While existing models excel at single-task learning, it is observed in practical applications that their performance degrades in the multi-task setting, where interference across tasks leads to an averaging effect. To address this issue, we propose to learn diverse skills for behavior models with Mixture of Experts, referred to as Di-BM. Di-BM associates each expert with a distinct observation distribution, enabling experts to specialize in sub-regions of the observation space. Specifically, we employ energy-based models to represent expert-specific observation distributions and jointly train them alongside the corresponding action models. Our approach is plug-and-play and can be seamlessly integrated into standard imitation learning methods. Extensive experiments on multiple real-world robotic manipulation tasks demonstrate that Di-BM significantly outperforms state-of-the-art baselines. Moreover, fine-tuning the pretrained Di-BM on novel tasks exhibits superior data efficiency and the reusable of expert-learned knowledge. Code is available at https://github.com/robotnav-bot/Di-BM.
An Efficient and Multi-Modal Navigation System with One-Step World Model
Jan 18, 2026Navigation is a fundamental capability for mobile robots. While the current trend is to use learning-based approaches to replace traditional geometry-based methods, existing end-to-end learning-based policies often struggle with 3D spatial reasoning and lack a comprehensive understanding of physical world dynamics. Integrating world models-which predict future observations conditioned on given actions-with iterative optimization planning offers a promising solution due to their capacity for imagination and flexibility. However, current navigation world models, typically built on pure transformer architectures, often rely on multi-step diffusion processes and autoregressive frame-by-frame generation. These mechanisms result in prohibitive computational latency, rendering real-time deployment impossible. To address this bottleneck, we propose a lightweight navigation world model that adopts a one-step generation paradigm and a 3D U-Net backbone equipped with efficient spatial-temporal attention. This design drastically reduces inference latency, enabling high-frequency control while achieving superior predictive performance. We also integrate this model into an optimization-based planning framework utilizing anchor-based initialization to handle multi-modal goal navigation tasks. Extensive closed-loop experiments in both simulation and real-world environments demonstrate our system's superior efficiency and robustness compared to state-of-the-art baselines.
Implicit Kinodynamic Motion Retargeting for Human-to-humanoid Imitation Learning
Sep 18, 2025Human-to-humanoid imitation learning aims to learn a humanoid whole-body controller from human motion. Motion retargeting is a crucial step in enabling robots to acquire reference trajectories when exploring locomotion skills. However, current methods focus on motion retargeting frame by frame, which lacks scalability. Could we directly convert large-scale human motion into robot-executable motion through a more efficient approach? To address this issue, we propose Implicit Kinodynamic Motion Retargeting (IKMR), a novel efficient and scalable retargeting framework that considers both kinematics and dynamics. In kinematics, IKMR pretrains motion topology feature representation and a dual encoder-decoder architecture to learn a motion domain mapping. In dynamics, IKMR integrates imitation learning with the motion retargeting network to refine motion into physically feasible trajectories. After fine-tuning using the tracking results, IKMR can achieve large-scale physically feasible motion retargeting in real time, and a whole-body controller could be directly trained and deployed for tracking its retargeted trajectories. We conduct our experiments both in the simulator and the real robot on a full-size humanoid robot. Extensive experiments and evaluation results verify the effectiveness of our proposed framework.
DFDNet: Dynamic Frequency-Guided De-Flare Network
Jul 23, 2025
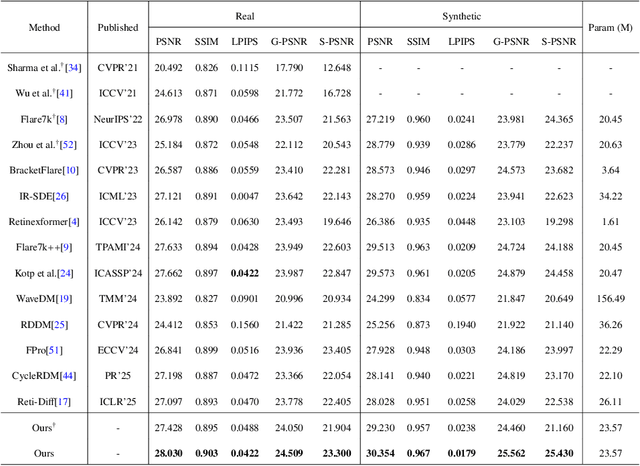
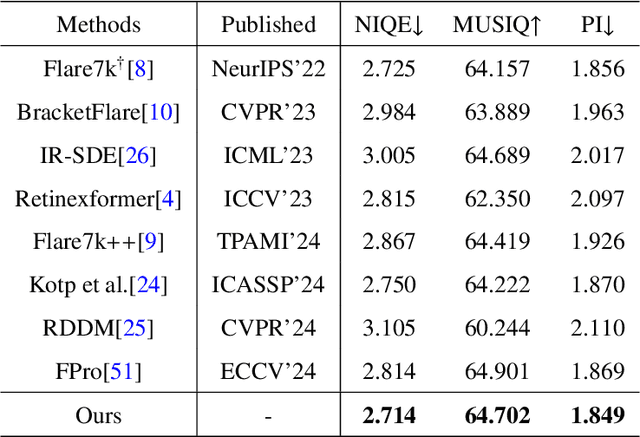
Strong light sources in nighttime photography frequently produce flares in images, significantly degrading visual quality and impacting the performance of downstream tasks. While some progress has been made, existing methods continue to struggle with removing large-scale flare artifacts and repairing structural damage in regions near the light source. We observe that these challenging flare artifacts exhibit more significant discrepancies from the reference images in the frequency domain compared to the spatial domain. Therefore, this paper presents a novel dynamic frequency-guided deflare network (DFDNet) that decouples content information from flare artifacts in the frequency domain, effectively removing large-scale flare artifacts. Specifically, DFDNet consists mainly of a global dynamic frequency-domain guidance (GDFG) module and a local detail guidance module (LDGM). The GDFG module guides the network to perceive the frequency characteristics of flare artifacts by dynamically optimizing global frequency domain features, effectively separating flare information from content information. Additionally, we design an LDGM via a contrastive learning strategy that aligns the local features of the light source with the reference image, reduces local detail damage from flare removal, and improves fine-grained image restoration. The experimental results demonstrate that the proposed method outperforms existing state-of-the-art methods in terms of performance. The code is available at \href{https://github.com/AXNing/DFDNet}{https://github.com/AXNing/DFDNet}.
UR2P-Dehaze: Learning a Simple Image Dehaze Enhancer via Unpaired Rich Physical Prior
Jan 12, 2025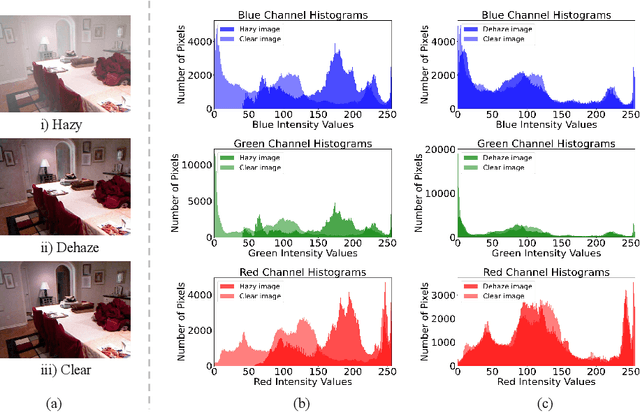
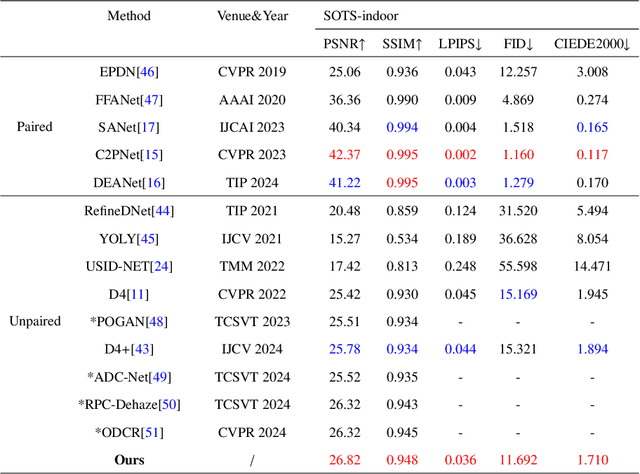
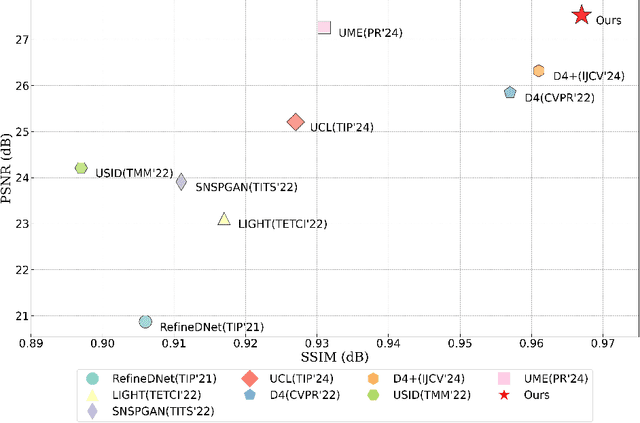
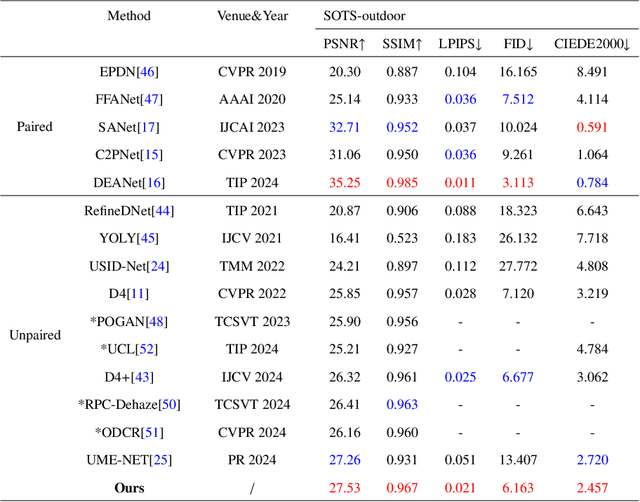
Image dehazing techniques aim to enhance contrast and restore details, which are essential for preserving visual information and improving image processing accuracy. Existing methods rely on a single manual prior, which cannot effectively reveal image details. To overcome this limitation, we propose an unpaired image dehazing network, called the Simple Image Dehaze Enhancer via Unpaired Rich Physical Prior (UR2P-Dehaze). First, to accurately estimate the illumination, reflectance, and color information of the hazy image, we design a shared prior estimator (SPE) that is iteratively trained to ensure the consistency of illumination and reflectance, generating clear, high-quality images. Additionally, a self-monitoring mechanism is introduced to eliminate undesirable features, providing reliable priors for image reconstruction. Next, we propose Dynamic Wavelet Separable Convolution (DWSC), which effectively integrates key features across both low and high frequencies, significantly enhancing the preservation of image details and ensuring global consistency. Finally, to effectively restore the color information of the image, we propose an Adaptive Color Corrector that addresses the problem of unclear colors. The PSNR, SSIM, LPIPS, FID and CIEDE2000 metrics on the benchmark dataset show that our method achieves state-of-the-art performance. It also contributes to the performance improvement of downstream tasks. The project code will be available at https://github.com/Fan-pixel/UR2P-Dehaze. \end{abstract}
Image Quality Assessment: Exploring Regional Heterogeneity via Response of Adaptive Multiple Quality Factors in Dictionary Space
Dec 24, 2024



Given that the factors influencing image quality vary significantly with scene, content, and distortion type, particularly in the context of regional heterogeneity, we propose an adaptive multi-quality factor (AMqF) framework to represent image quality in a dictionary space, enabling the precise capture of quality features in non-uniformly distorted regions. By designing an adapter, the framework can flexibly decompose quality factors (such as brightness, structure, contrast, etc.) that best align with human visual perception and quantify them into discrete visual words. These visual words respond to the constructed dictionary basis vector, and by obtaining the corresponding coordinate vectors, we can measure visual similarity. Our method offers two key contributions. First, an adaptive mechanism that extracts and decomposes quality factors according to human visual perception principles enhances their representation ability through reconstruction constraints. Second, the construction of a comprehensive and discriminative dictionary space and basis vector allows quality factors to respond effectively to the dictionary basis vector and capture non-uniform distortion patterns in images, significantly improving the accuracy of visual similarity measurement. The experimental results demonstrate that the proposed method outperforms existing state-of-the-art approaches in handling various types of distorted images. The source code is available at https://anonymous.4open.science/r/AMqF-44B2.