 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANO: A Principled Approach to Robust Policy Optimization
May 06, 2026Proximal Policy Optimization (PPO) dominates reinforcement learning and LLM alignment but relies on a "hard clipping" mechanism that discards valuable gradients. Conversely, unconstrained methods like SPO expose the optimization to unbounded updates, causing severe instability and policy collapse during extreme outlier encounters. To resolve this dilemma, we introduce a principled design space for policy optimization, demonstrating that a robust estimator must inherently suppress outliers while maintaining a smooth restoration force. Guided by these geometric principles, we derive Anchored Neighborhood Optimization (ANO), a novel method that seamlessly replaces hard clipping with a redescending gradient mechanism. Extensive evaluations demonstrate ANO's empirical superiority across diverse domains. In continuous (MuJoCo) and discrete (Atari) control, ANO establishes a robust state-of-the-art, uniquely preventing policy collapse even under highly aggressive learning rates ($1 \times 10^{-3}$). Furthermore, in LLM alignment (RLHF), ANO explicitly eliminates the catastrophic KL divergence explosion inherent to unconstrained methods, dominating PPO, SPO, and GRPO in head-to-head win rates.
Anon: Extrapolating Adaptivity Beyond SGD and Adam
May 06, 2026Adaptive optimizers such as Adam have achieved great success in training large-scale models like large language models and diffusion models. However, they often generalize worse than non-adaptive methods, such as SGD on classical architectures like CNNs. We identify a key cause of this performance gap: adaptivity in pre-conditioners, which limits the optimizer's ability to adapt to diverse optimization landscapes. To address this, we propose Anon (Adaptivity Non-restricted Optimizer with Novel convergence technique), a novel optimizer with continuously tunable adaptivity in R, allowing it to interpolate between SGD-like and Adam-like behaviors and even extrapolate beyond both. To ensure convergence across the entire adaptivity spectrum, we introduce incremental delay update (IDU), a novel mechanism that is more flexible than AMSGrad's hard max-tracking strategy and enhances robustness to gradient noise. We theoretically establish convergence guarantees under both convex and non-convex settings. Empirically, Anon consistently outperforms state-of-the-art optimizers on representative image classification, diffusion, and language modeling tasks. These results demonstrate that adaptivity can serve as a valuable tunable design principle, and Anon provides the first unified and reliable framework capable of bridging the gap between classical and modern optimizers and surpassing their advantageous properties.
Multimodal Mixture-of-Experts with Retrieval Augmentation for Protein Active Site Identification
Mar 02, 2026Accurate identification of protein active sites at the residue level is crucial for understanding protein function and advancing drug discovery. However, current methods face two critical challenges: vulnerability in single-instance prediction due to sparse training data, and inadequate modality reliability estimation that leads to performance degradation when unreliable modalities dominate fusion processes. To address these challenges, we introduce Multimodal Mixture-of-Experts with Retrieval Augmentation (MERA), the first retrieval-augmented framework for protein active site identification. MERA employs hierarchical multi-expert retrieval that dynamically aggregates contextual information from chain, sequence, and active-site perspectives through residue-level mixture-of-experts gating. To prevent modality degradation, we propose a reliability-aware fusion strategy based on Dempster-Shafer evidence theory that quantifies modality trustworthiness through belief mass functions and learnable discounting coefficients, enabling principled multimodal integration. Extensive experiments on ProTAD-Gen and TS125 datasets demonstrate that MERA achieves state-of-the-art performance, with 90% AUPRC on active site prediction and significant gains on peptide-binding site identification, validating the effectiveness of retrieval-augmented multi-expert modeling and reliability-guided fusion.
Hierarchical Frequency-Decomposition Graph Neural Networks for Road Network Representation Learning
Nov 16, 2025Road networks are critical infrastructures underpinning intelligent transportation systems and their related applications. Effective representation learning of road networks remains challenging due to the complex interplay between spatial structures and frequency characteristics in traffic patterns. Existing graph neural networks for modeling road networks predominantly fall into two paradigms: spatial-based methods that capture local topology but tend to over-smooth representations, and spectral-based methods that analyze global frequency components but often overlook localized variations. This spatial-spectral misalignment limits their modeling capacity for road networks exhibiting both coarse global trends and fine-grained local fluctuations. To bridge this gap, we propose HiFiNet, a novel hierarchical frequency-decomposition graph neural network that unifies spatial and spectral modeling. HiFiNet constructs a multi-level hierarchy of virtual nodes to enable localized frequency analysis, and employs a decomposition-updating-reconstruction framework with a topology-aware graph transformer to separately model and fuse low- and high-frequency signals. Theoretically justified and empirically validated on multiple real-world datasets across four downstream tasks, HiFiNet demonstrates superior performance and generalization ability in capturing effective road network representations.
Connectivity-Guided Sparsification of 2-FWL GNNs: Preserving Full Expressivity with Improved Efficiency
Nov 16, 2025



Higher-order Graph Neural Networks (HOGNNs) based on the 2-FWL test achieve superior expressivity by modeling 2- and 3-node interactions, but at $\mathcal{O}(n^3)$ computational cost. However, this computational burden is typically mitigated by existing efficiency methods at the cost of reduced expressivity. We propose \textbf{Co-Sparsify}, a connectivity-aware sparsification framework that eliminates \emph{provably redundant} computations while preserving full 2-FWL expressive power. Our key insight is that 3-node interactions are expressively necessary only within \emph{biconnected components} -- maximal subgraphs where every pair of nodes lies on a cycle. Outside these components, structural relationships can be fully captured via 2-node message passing or global readout, rendering higher-order modeling unnecessary. Co-Sparsify restricts 2-node message passing to connected components and 3-node interactions to biconnected ones, removing computation without approximation or sampling. We prove that Co-Sparsified GNNs are as expressive as the 2-FWL test. Empirically, on PPGN, Co-Sparsify matches or exceeds accuracy on synthetic substructure counting tasks and achieves state-of-the-art performance on real-world benchmarks (ZINC, QM9). This study demonstrates that high expressivity and scalability are not mutually exclusive: principled, topology-guided sparsification enables powerful, efficient GNNs with theoretical guarantees.
Moon: A Modality Conversion-based Efficient Multivariate Time Series Anomaly Detection
Oct 02, 2025Multivariate time series (MTS) anomaly detection identifies abnormal patterns where each timestamp contains multiple variables. Existing MTS anomaly detection methods fall into three categories: reconstruction-based, prediction-based, and classifier-based methods. However, these methods face two key challenges: (1) Unsupervised learning methods, such as reconstruction-based and prediction-based methods, rely on error thresholds, which can lead to inaccuracies; (2) Semi-supervised methods mainly model normal data and often underuse anomaly labels, limiting detection of subtle anomalies;(3) Supervised learning methods, such as classifier-based approaches, often fail to capture local relationships, incur high computational costs, and are constrained by the scarcity of labeled data. To address these limitations, we propose Moon, a supervised modality conversion-based multivariate time series anomaly detection framework. Moon enhances the efficiency and accuracy of anomaly detection while providing detailed anomaly analysis reports. First, Moon introduces a novel multivariate Markov Transition Field (MV-MTF) technique to convert numeric time series data into image representations, capturing relationships across variables and timestamps. Since numeric data retains unique patterns that cannot be fully captured by image conversion alone, Moon employs a Multimodal-CNN to integrate numeric and image data through a feature fusion model with parameter sharing, enhancing training efficiency. Finally, a SHAP-based anomaly explainer identifies key variables contributing to anomalies, improving interpretability. Extensive experiments on six real-world MTS datasets demonstrate that Moon outperforms six state-of-the-art methods by up to 93% in efficiency, 4% in accuracy and, 10.8% in interpretation performance.
Underwater Image Quality Assessment: A Perceptual Framework Guided by Physical Imaging
Dec 20, 2024In this paper, we propose a physically imaging-guided framework for underwater image quality assessment (UIQA), called PIGUIQA. First, we formulate UIQA as a comprehensive problem that considers the combined effects of direct transmission attenuation and backwards scattering on image perception. On this basis, we incorporate advanced physics-based underwater imaging estimation into our method and define distortion metrics that measure the impact of direct transmission attenuation and backwards scattering on image quality. Second, acknowledging the significant content differences across various regions of an image and the varying perceptual sensitivity to distortions in these regions, we design a local perceptual module on the basis of the neighborhood attention mechanism. This module effectively captures subtle features in images, thereby enhancing the adaptive perception of distortions on the basis of local information. Finally, by employing a global perceptual module to further integrate the original image content with underwater image distortion information, the proposed model can accurately predict the image quality score. Comprehensive experiments demonstrate that PIGUIQA achieves state-of-the-art performance in underwater image quality prediction and exhibits strong generalizability. The code for PIGUIQA is available on https://anonymous.4open.science/r/PIGUIQA-A465/
Tokenphormer: Structure-aware Multi-token Graph Transformer for Node Classification
Dec 19, 2024Graph Neural Networks (GNNs) are widely used in graph data mining tasks. Traditional GNNs follow a message passing scheme that can effectively utilize local and structural information. However, the phenomena of over-smoothing and over-squashing limit the receptive field in message passing processes. Graph Transformers were introduced to address these issues, achieving a global receptive field but suffering from the noise of irrelevant nodes and loss of structural information. Therefore, drawing inspiration from fine-grained token-based representation learning in Natural Language Processing (NLP), we propose the Structure-aware Multi-token Graph Transformer (Tokenphormer), which generates multiple tokens to effectively capture local and structural information and explore global information at different levels of granularity. Specifically, we first introduce the walk-token generated by mixed walks consisting of four walk types to explore the graph and capture structure and contextual information flexibly. To ensure local and global information coverage, we also introduce the SGPM-token (obtained through the Self-supervised Graph Pre-train Model, SGPM) and the hop-token, extending the length and density limit of the walk-token, respectively. Finally, these expressive tokens are fed into the Transformer model to learn node representations collaboratively. Experimental results demonstrate that the capability of the proposed Tokenphormer can achieve state-of-the-art performance on node classification tasks.
VecCity: A Taxonomy-guided Library for Map Entity Representation Learning
Oct 31, 2024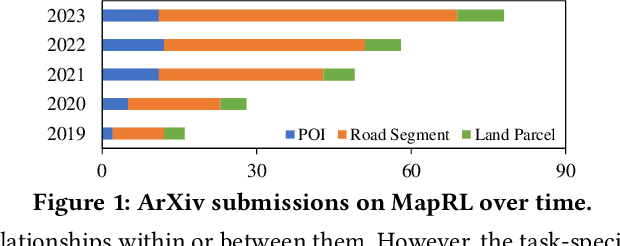
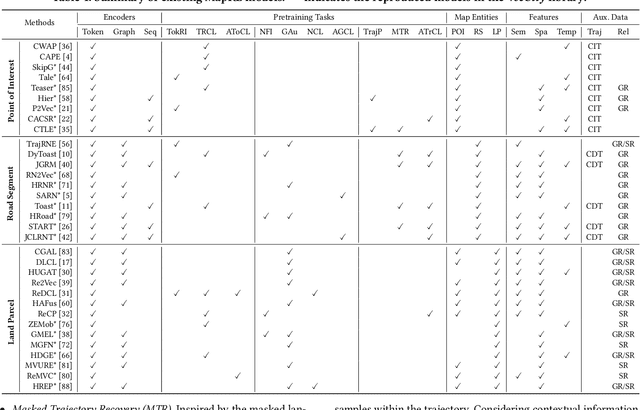
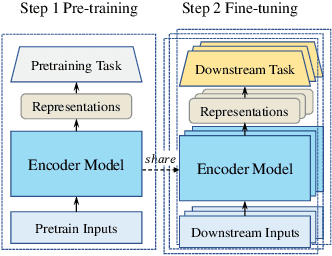
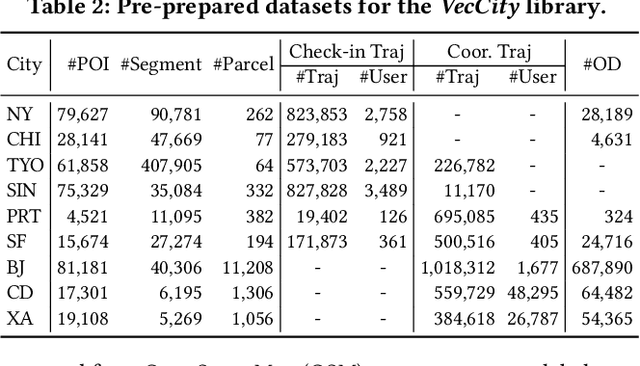
Electronic maps consist of diverse entities, such as points of interest (POIs), road networks, and land parcels, playing a vital role in applications like ITS and LBS. Map entity representation learning (MapRL) generates versatile and reusable data representations, providing essential tools for efficiently managing and utilizing map entity data. Despite the progress in MapRL, two key challenges constrain further development. First, existing research is fragmented, with models classified by the type of map entity, limiting the reusability of techniques across different tasks. Second, the lack of unified benchmarks makes systematic evaluation and comparison of models difficult. To address these challenges, we propose a novel taxonomy for MapRL that organizes models based on functional module-such as encoders, pre-training tasks, and downstream tasks-rather than by entity type. Building on this taxonomy, we present a taxonomy-driven library, VecCity, which offers easy-to-use interfaces for encoding, pre-training, fine-tuning, and evaluation. The library integrates datasets from nine cities and reproduces 21 mainstream MapRL models, establishing the first standardized benchmarks for the field. VecCity also allows users to modify and extend models through modular components, facilitating seamless experimentation. Our comprehensive experiments cover multiple types of map entities and evaluate 21 VecCity pre-built models across various downstream tasks. Experimental results demonstrate the effectiveness of VecCity in streamlining model development and provide insights into the impact of various components on performance. By promoting modular design and reusability, VecCity offers a unified framework to advance research and innovation in MapRL. The code is available at https://github.com/Bigscity-VecCity/VecCity.
Efficient Diversity-based Experience Replay for Deep Reinforcement Learning
Oct 27, 2024



Deep Reinforcement Learning (DRL) has achieved remarkable success in solving complex decision-making problems by combining the representation capabilities of deep learning with the decision-making power of reinforcement learning. However, learning in sparse reward environments remains challenging due to insufficient feedback to guide the optimization of agents, especially in real-life environments with high-dimensional states. To tackle this issue, experience replay is commonly introduced to enhance learning efficiency through past experiences. Nonetheless, current methods of experience replay, whether based on uniform or prioritized sampling, frequently struggle with suboptimal learning efficiency and insufficient utilization of samples. This paper proposes a novel approach, diversity-based experience replay (DBER), which leverages the deterministic point process to prioritize diverse samples in state realizations. We conducted extensive experiments on Robotic Manipulation tasks in MuJoCo, Atari games, and realistic in-door environments in Habitat. The results show that our method not only significantly improves learning efficiency but also demonstrates superior performance in sparse reward environments with high-dimensional states, providing a simple yet effective solution for this field.