 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Quality Assessment: Exploring Regional Heterogeneity via Response of Adaptive Multiple Quality Factors in Dictionary Space
Dec 24, 2024



Given that the factors influencing image quality vary significantly with scene, content, and distortion type, particularly in the context of regional heterogeneity, we propose an adaptive multi-quality factor (AMqF) framework to represent image quality in a dictionary space, enabling the precise capture of quality features in non-uniformly distorted regions. By designing an adapter, the framework can flexibly decompose quality factors (such as brightness, structure, contrast, etc.) that best align with human visual perception and quantify them into discrete visual words. These visual words respond to the constructed dictionary basis vector, and by obtaining the corresponding coordinate vectors, we can measure visual similarity. Our method offers two key contributions. First, an adaptive mechanism that extracts and decomposes quality factors according to human visual perception principles enhances their representation ability through reconstruction constraints. Second, the construction of a comprehensive and discriminative dictionary space and basis vector allows quality factors to respond effectively to the dictionary basis vector and capture non-uniform distortion patterns in images, significantly improving the accuracy of visual similarity measurement. The experimental results demonstrate that the proposed method outperforms existing state-of-the-art approaches in handling various types of distorted images. The source code is available at https://anonymous.4open.science/r/AMqF-44B2.
Image Quality Assessment: Investigating Causal Perceptual Effects with Abductive Counterfactual Inference
Dec 22, 2024Existing full-reference image quality assessment (FR-IQA) methods often fail to capture the complex causal mechanisms that underlie human perceptual responses to image distortions, limiting their ability to generalize across diverse scenarios. In this paper, we propose an FR-IQA method based on abductive counterfactual inference to investigate the causal relationships between deep network features and perceptual distortions. First, we explore the causal effects of deep features on perception and integrate causal reasoning with feature comparison, constructing a model that effectively handles complex distortion types across different IQA scenarios. Second, the analysis of the perceptual causal correlations of our proposed method is independent of the backbone architecture and thus can be applied to a variety of deep networks. Through abductive counterfactual experiments, we validate the proposed causal relationships, confirming the model's superior perceptual relevance and interpretability of quality scores. The experimental results demonstrate the robustness and effectiveness of the method, providing competitive quality predictions across multiple benchmarks. The source code is available at https://anonymous.4open.science/r/DeepCausalQuality-25BC.
Image Quality Assessment: Enhancing Perceptual Exploration and Interpretation with Collaborative Feature Refinement and Hausdorff distance
Dec 20, 2024



Current full-reference image quality assessment (FR-IQA) methods often fuse features from reference and distorted images, overlooking that color and luminance distortions occur mainly at low frequencies, whereas edge and texture distortions occur at high frequencies. This work introduces a pioneering training-free FR-IQA method that accurately predicts image quality in alignment with the human visual system (HVS) by leveraging a novel perceptual degradation modelling approach to address this limitation. First, a collaborative feature refinement module employs a carefully designed wavelet transform to extract perceptually relevant features, capturing multiscale perceptual information and mimicking how the HVS analyses visual information at various scales and orientations in the spatial and frequency domains. Second, a Hausdorff distance-based distribution similarity measurement module robustly assesses the discrepancy between the feature distributions of the reference and distorted images, effectively handling outliers and variations while mimicking the ability of HVS to perceive and tolerate certain levels of distortion. The proposed method accurately captures perceptual quality differences without requiring training data or subjective quality scores. Extensive experiments on multiple benchmark datasets demonstrate superior performance compared with existing state-of-the-art approaches, highlighting its ability to correlate strongly with the HVS.\footnote{The code is available at \url{https://anonymous.4open.science/r/CVPR2025-F339}.}
Tokenphormer: Structure-aware Multi-token Graph Transformer for Node Classification
Dec 19, 2024Graph Neural Networks (GNNs) are widely used in graph data mining tasks. Traditional GNNs follow a message passing scheme that can effectively utilize local and structural information. However, the phenomena of over-smoothing and over-squashing limit the receptive field in message passing processes. Graph Transformers were introduced to address these issues, achieving a global receptive field but suffering from the noise of irrelevant nodes and loss of structural information. Therefore, drawing inspiration from fine-grained token-based representation learning in Natural Language Processing (NLP), we propose the Structure-aware Multi-token Graph Transformer (Tokenphormer), which generates multiple tokens to effectively capture local and structural information and explore global information at different levels of granularity. Specifically, we first introduce the walk-token generated by mixed walks consisting of four walk types to explore the graph and capture structure and contextual information flexibly. To ensure local and global information coverage, we also introduce the SGPM-token (obtained through the Self-supervised Graph Pre-train Model, SGPM) and the hop-token, extending the length and density limit of the walk-token, respectively. Finally, these expressive tokens are fed into the Transformer model to learn node representations collaboratively. Experimental results demonstrate that the capability of the proposed Tokenphormer can achieve state-of-the-art performance on node classification tasks.
An Ensemble Rate Adaptation Framework for Dynamic Adaptive Streaming Over HTTP
Dec 26, 2019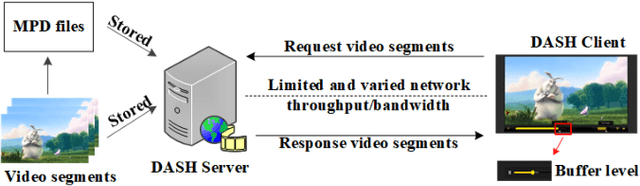
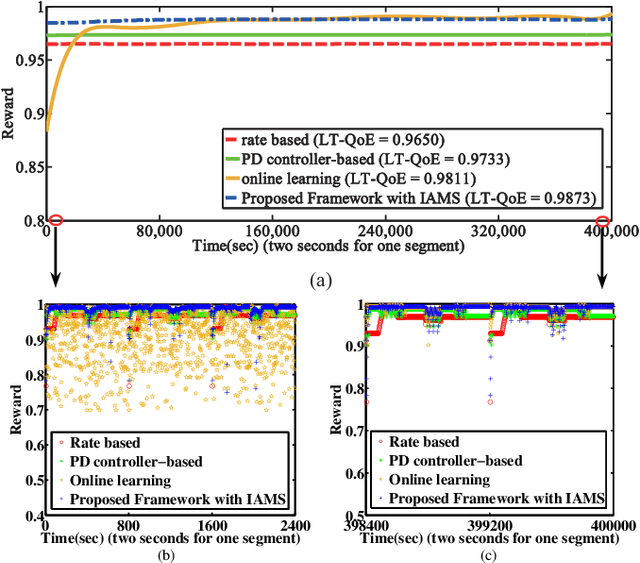
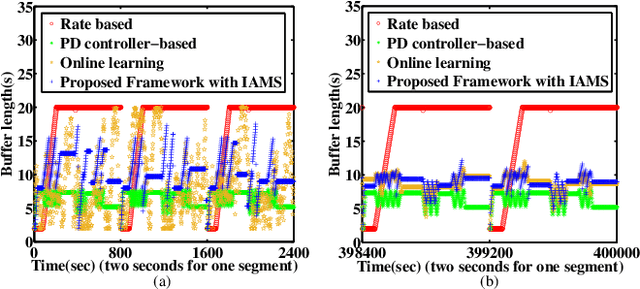
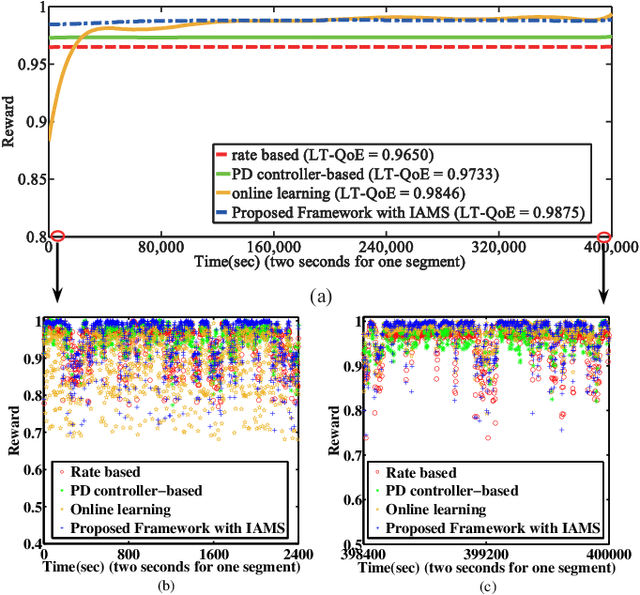
Rate adaptation is one of the most important issues in dynamic adaptive streaming over HTTP (DASH). Due to the frequent fluctuations of the network bandwidth and complex variations of video content, it is difficult to deal with the varying network conditions and video content perfectly by using a single rate adaptation method. In this paper, we propose an ensemble rate adaptation framework for DASH, which aims to leverage the advantages of multiple methods involved in the framework to improve the quality of experience (QoE) of users. The proposed framework is simple yet very effective. Specifically, the proposed framework is composed of two modules, i.e., the method pool and method controller. In the method pool, several rate adap tation methods are integrated. At each decision time, only the method that can achieve the best QoE is chosen to determine the bitrate of the requested video segment. Besides, we also propose two strategies for switching methods, i.e., InstAnt Method Switching, and InterMittent Method Switching, for the method controller to determine which method can provide the best QoEs. Simulation results demonstrate that, the proposed framework always achieves the highest QoE for the change of channel environment and video complexity, compared with state-of-the-art rate adaptation methods.
Spatial and Temporal Consistency-Aware Dynamic Adaptive Streaming for 360-Degree Videos
Dec 20, 2019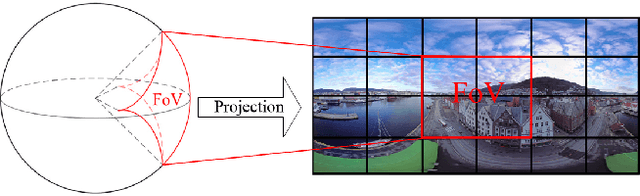

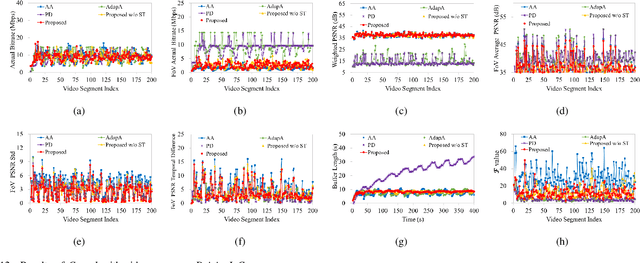
The 360-degree video allows users to enjoy the whole scene by interactively switching viewports. However, the huge data volume of the 360-degree video limits its remote applications via network. To provide high quality of experience (QoE) for remote web users, this paper presents a tile-based adaptive streaming method for 360-degree videos. First, we propose a simple yet effective rate adaptation algorithm to determine the requested bitrate for downloading the current video segment by considering the balance between the buffer length and video quality. Then, we propose to use a Gaussian model to predict the field of view at the beginning of each requested video segment. To deal with the circumstance that the view angle is switched during the display of a video segment, we propose to download all the tiles in the 360-degree video with different priorities based on a Zipf model. Finally, in order to allocate bitrates for all the tiles, a two-stage optimization algorithm is proposed to preserve the quality of tiles in FoV and guarantee the spatial and temporal smoothness. Experimental results demonstrate the effectiveness and advantage of the proposed method compared with the state-of-the-art methods. That is, our method preserves both the quality and the smoothness of tiles in FoV, thus providing the best QoE for users.