 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBACH-V: Bridging Abstract and Concrete Human-Values in Large Language Models
Jan 20, 2026Do large language models (LLMs) genuinely understand abstract concepts, or merely manipulate them as statistical patterns? We introduce an abstraction-grounding framework that decomposes conceptual understanding into three capacities: interpretation of abstract concepts (Abstract-Abstract, A-A), grounding of abstractions in concrete events (Abstract-Concrete, A-C), and application of abstract principles to regulate concrete decisions (Concrete-Concrete, C-C). Using human values as a testbed - given their semantic richness and centrality to alignment - we employ probing (detecting value traces in internal activations) and steering (modifying representations to shift behavior). Across six open-source LLMs and ten value dimensions, probing shows that diagnostic probes trained solely on abstract value descriptions reliably detect the same values in concrete event narratives and decision reasoning, demonstrating cross-level transfer. Steering reveals an asymmetry: intervening on value representations causally shifts concrete judgments and decisions (A-C, C-C), yet leaves abstract interpretations unchanged (A-A), suggesting that encoded abstract values function as stable anchors rather than malleable activations. These findings indicate LLMs maintain structured value representations that bridge abstraction and action, providing a mechanistic and operational foundation for building value-driven autonomous AI systems with more transparent, generalizable alignment and control.
When Reasoning Meets Its Laws
Dec 19, 2025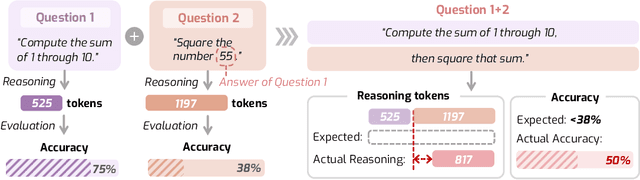
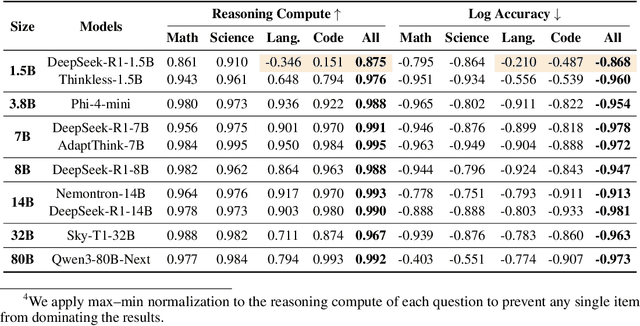
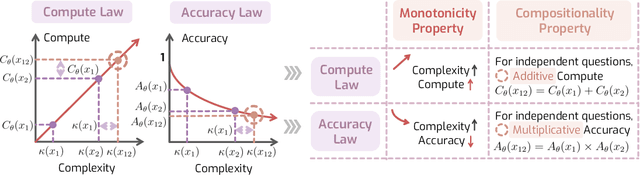
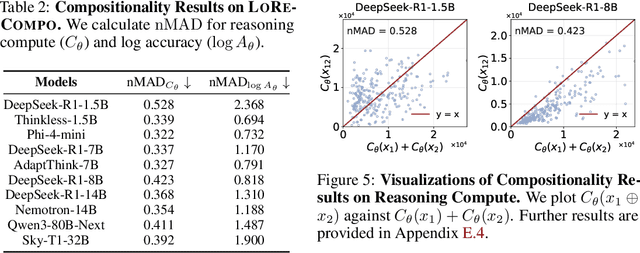
Despite the superior performance of Large Reasoning Models (LRMs), their reasoning behaviors are often counterintuitive, leading to suboptimal reasoning capabilities. To theoretically formalize the desired reasoning behaviors, this paper presents the Laws of Reasoning (LoRe), a unified framework that characterizes intrinsic reasoning patterns in LRMs. We first propose compute law with the hypothesis that the reasoning compute should scale linearly with question complexity. Beyond compute, we extend LoRe with a supplementary accuracy law. Since the question complexity is difficult to quantify in practice, we examine these hypotheses by two properties of the laws, monotonicity and compositionality. We therefore introduce LoRe-Bench, a benchmark that systematically measures these two tractable properties for large reasoning models. Evaluation shows that most reasoning models exhibit reasonable monotonicity but lack compositionality. In response, we develop an effective finetuning approach that enforces compute-law compositionality. Extensive empirical studies demonstrate that better compliance with compute laws yields consistently improved reasoning performance on multiple benchmarks, and uncovers synergistic effects across properties and laws. Project page: https://lore-project.github.io/
Non-Asymptotic Global Convergence of PPO-Clip
Dec 18, 2025
Reinforcement learning (RL) has gained attention for aligning large language models (LLMs) via reinforcement learning from human feedback (RLHF). The actor-only variants of Proximal Policy Optimization (PPO) are widely applied for their efficiency. These algorithms incorporate a clipping mechanism to improve stability. Besides, a regularization term, such as the reverse KL-divergence or a more general \(f\)-divergence, is introduced to prevent policy drift. Despite their empirical success, a rigorous theoretical understanding of the problem and the algorithm's properties is limited. This paper advances the theoretical foundations of the PPO-Clip algorithm by analyzing a deterministic actor-only PPO algorithm within the general RL setting with \(f\)-divergence regularization under the softmax policy parameterization. We derive a non-uniform Lipschitz smoothness condition and a Łojasiewicz inequality for the considered problem. Based on these, a non-asymptotic linear convergence rate to the globally optimal policy is established for the forward KL-regularizer. Furthermore, stationary convergence and local linear convergence are derived for the reverse KL-regularizer.
AlphaOne: Reasoning Models Thinking Slow and Fast at Test Time
May 30, 2025This paper presents AlphaOne ($\alpha$1), a universal framework for modulating reasoning progress in large reasoning models (LRMs) at test time. $\alpha$1 first introduces $\alpha$ moment, which represents the scaled thinking phase with a universal parameter $\alpha$. Within this scaled pre-$\alpha$ moment phase, it dynamically schedules slow thinking transitions by modeling the insertion of reasoning transition tokens as a Bernoulli stochastic process. After the $\alpha$ moment, $\alpha$1 deterministically terminates slow thinking with the end-of-thinking token, thereby fostering fast reasoning and efficient answer generation. This approach unifies and generalizes existing monotonic scaling methods by enabling flexible and dense slow-to-fast reasoning modulation. Extensive empirical studies on various challenging benchmarks across mathematical, coding, and scientific domains demonstrate $\alpha$1's superior reasoning capability and efficiency. Project page: https://alphaone-project.github.io/
EmbodiedBench: Comprehensive Benchmarking Multi-modal Large Language Models for Vision-Driven Embodied Agents
Feb 13, 2025



Leveraging Multi-modal Large Language Models (MLLMs) to create embodied agents offers a promising avenue for tackling real-world tasks. While language-centric embodied agents have garnered substantial attention, MLLM-based embodied agents remain underexplored due to the lack of comprehensive evaluation frameworks. To bridge this gap, we introduce EmbodiedBench, an extensive benchmark designed to evaluate vision-driven embodied agents. EmbodiedBench features: (1) a diverse set of 1,128 testing tasks across four environments, ranging from high-level semantic tasks (e.g., household) to low-level tasks involving atomic actions (e.g., navigation and manipulation); and (2) six meticulously curated subsets evaluating essential agent capabilities like commonsense reasoning, complex instruction understanding, spatial awareness, visual perception, and long-term planning. Through extensive experiments, we evaluated 13 leading proprietary and open-source MLLMs within EmbodiedBench. Our findings reveal that: MLLMs excel at high-level tasks but struggle with low-level manipulation, with the best model, GPT-4o, scoring only 28.9% on average. EmbodiedBench provides a multifaceted standardized evaluation platform that not only highlights existing challenges but also offers valuable insights to advance MLLM-based embodied agents. Our code is available at https://embodiedbench.github.io.
Generative Physical AI in Vision: A Survey
Jan 19, 2025



Generative Artificial Intelligence (AI) has rapidly advanced the field of computer vision by enabling machines to create and interpret visual data with unprecedented sophistication. This transformation builds upon a foundation of generative models to produce realistic images, videos, and 3D or 4D content. Traditionally, generative models primarily focus on visual fidelity while often neglecting the physical plausibility of generated content. This gap limits their effectiveness in applications requiring adherence to real-world physical laws, such as robotics, autonomous systems, and scientific simulations. As generative AI evolves to increasingly integrate physical realism and dynamic simulation, its potential to function as a "world simulator" expands-enabling the modeling of interactions governed by physics and bridging the divide between virtual and physical realities. This survey systematically reviews this emerging field of physics-aware generative AI in computer vision, categorizing methods based on how they incorporate physical knowledge-either through explicit simulation or implicit learning. We analyze key paradigms, discuss evaluation protocols, and identify future research directions. By offering a comprehensive overview, this survey aims to help future developments in physically grounded generation for vision. The reviewed papers are summarized at https://github.com/BestJunYu/Awesome-Physics-aware-Generation.
Image Quality Assessment: Enhancing Perceptual Exploration and Interpretation with Collaborative Feature Refinement and Hausdorff distance
Dec 20, 2024Current full-reference image quality assessment (FR-IQA) methods often fuse features from reference and distorted images, overlooking that color and luminance distortions occur mainly at low frequencies, whereas edge and texture distortions occur at high frequencies. This work introduces a pioneering training-free FR-IQA method that accurately predicts image quality in alignment with the human visual system (HVS) by leveraging a novel perceptual degradation modelling approach to address this limitation. First, a collaborative feature refinement module employs a carefully designed wavelet transform to extract perceptually relevant features, capturing multiscale perceptual information and mimicking how the HVS analyses visual information at various scales and orientations in the spatial and frequency domains. Second, a Hausdorff distance-based distribution similarity measurement module robustly assesses the discrepancy between the feature distributions of the reference and distorted images, effectively handling outliers and variations while mimicking the ability of HVS to perceive and tolerate certain levels of distortion. The proposed method accurately captures perceptual quality differences without requiring training data or subjective quality scores. Extensive experiments on multiple benchmark datasets demonstrate superior performance compared with existing state-of-the-art approaches, highlighting its ability to correlate strongly with the HVS.\footnote{The code is available at \url{https://anonymous.4open.science/r/CVPR2025-F339}.}
Bridging the Resource Gap: Deploying Advanced Imitation Learning Models onto Affordable Embedded Platforms
Nov 18, 2024



Advanced imitation learning with structures like the transformer is increasingly demonstrating its advantages in robotics. However, deploying these large-scale models on embedded platforms remains a major challenge. In this paper, we propose a pipeline that facilitates the migration of advanced imitation learning algorithms to edge devices. The process is achieved via an efficient model compression method and a practical asynchronous parallel method Temporal Ensemble with Dropped Actions (TEDA) that enhances the smoothness of operations. To show the efficiency of the proposed pipeline, large-scale imitation learning models are trained on a server and deployed on an edge device to complete various manipulation tasks.
DynaMath: A Dynamic Visual Benchmark for Evaluating Mathematical Reasoning Robustness of Vision Language Models
Oct 29, 2024The rapid advancements in Vision-Language Models (VLMs) have shown great potential in tackling mathematical reasoning tasks that involve visual context. Unlike humans who can reliably apply solution steps to similar problems with minor modifications, we found that SOTA VLMs like GPT-4o can consistently fail in these scenarios, revealing limitations in their mathematical reasoning capabilities. In this paper, we investigate the mathematical reasoning robustness in VLMs and evaluate how well these models perform under different variants of the same question, such as changes in visual numerical values or function graphs. While several vision-based math benchmarks have been developed to assess VLMs' problem-solving capabilities, these benchmarks contain only static sets of problems and cannot easily evaluate mathematical reasoning robustness. To fill this gap, we introduce DynaMath, a dynamic visual math benchmark designed for in-depth assessment of VLMs. DynaMath includes 501 high-quality, multi-topic seed questions, each represented as a Python program. Those programs are carefully designed and annotated to enable the automatic generation of a much larger set of concrete questions, including many different types of visual and textual variations. DynaMath allows us to evaluate the generalization ability of VLMs, by assessing their performance under varying input conditions of a seed question. We evaluated 14 SOTA VLMs with 5,010 generated concrete questions. Our results show that the worst-case model accuracy, defined as the percentage of correctly answered seed questions in all 10 variants, is significantly lower than the average-case accuracy. Our analysis emphasizes the need to study the robustness of VLMs' reasoning abilities, and DynaMath provides valuable insights to guide the development of more reliable models for mathematical reasoning.
An Improved Finite-time Analysis of Temporal Difference Learning with Deep Neural Networks
May 07, 2024Temporal difference (TD) learning algorithms with neural network function parameterization have well-established empirical success in many practical large-scale reinforcement learning tasks. However, theoretical understanding of these algorithms remains challenging due to the nonlinearity of the action-value approximation. In this paper, we develop an improved non-asymptotic analysis of the neural TD method with a general $L$-layer neural network. New proof techniques are developed and an improved new $\tilde{\mathcal{O}}(\epsilon^{-1})$ sample complexity is derived. To our best knowledge, this is the first finite-time analysis of neural TD that achieves an $\tilde{\mathcal{O}}(\epsilon^{-1})$ complexity under the Markovian sampling, as opposed to the best known $\tilde{\mathcal{O}}(\epsilon^{-2})$ complexity in the existing literature.