 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-OptBench: A Solver-Grounded Benchmark for Multimodal Optimization Modeling
May 12, 2026Optimization modeling translates real decision-making problems into mathematical optimization models and solver-executable implementations. Although language models are increasingly used to generate optimization formulations and solver code, existing benchmarks are almost entirely text-only. This omits many optimization-modeling tasks that arise in operational practice, where requirements are described in text but instance information is conveyed through visual artifacts such as tables, graphs, maps, schedules, and dashboards. We introduce multimodal optimization modeling, a benchmark setting in which models must construct both a mathematical formulation and executable solver code from a text-and-visual problem specification. To evaluate this setting, we develop a solver-grounded framework that generates structured optimization instances, verifies each with an exact solver, and builds both the model-facing inputs and hidden reference files from the same verified source. We instantiate the framework as MM-OptBench, a benchmark of 780 solver-verified instances spanning 6 optimization families, 26 subcategories, and 3 structural difficulty levels. We evaluate 9 multimodal large language models (MLLMs), including 6 frontier general-purpose models and 3 math-specialized models, with aggregate, family-level, difficulty-level, and failure-mode analyses. The results show that the task remains far from solved: the best two models reach 52.1% and 51.3% pass@1, while on average across the six general-purpose MLLMs, pass@1 is 43.4% on easy instances and 15.9% on hard instances. All three math-specialized MLLMs solve 0/780 instances. Failure attribution shows that errors arise both when extracting instance data from text and visuals and when turning extracted data into solver-correct formulations and code. MM-OptBench provides a testbed for solver-grounded, decision-oriented multimodal intelligence.
OptProver: Bridging Olympiad and Optimization through Continual Training in Formal Theorem Proving
Apr 28, 2026Recent advances in formal theorem proving have focused on Olympiad-level mathematics, leaving undergraduate domains largely unexplored. Optimization, fundamental to machine learning, operations research, and scientific computing, remains underserved by existing provers. Its reliance on domain-specific formalisms (convexity, optimality conditions, and algorithmic analysis) creates significant distribution shift, making naive domain transfer ineffective. We present OptProver, a trained model that achieves robust transfer from Olympiad to undergraduate optimization. Starting from a strong Olympiad-level prover, our pipeline mitigates distribution shift through two key innovations. First, we employ large-scale optimization-focused data curation via expert iteration. Second, we introduce a specialized preference learning objective that integrates perplexity-weighted optimization with a mechanism to penalize valid but non-progressing proof steps. This not only addresses distribution shifts but also guides the search toward efficient trajectories. To enable rigorous evaluation, we construct a novel benchmark in Lean 4 focused on optimization. On this benchmark, OptProver achieves state-of-the-art Pass@1 and Pass@32 among comparably sized models while maintaining competitive performance on general theorem-proving tasks, demonstrating effective domain transfer without catastrophic forgetting.
Learning to Solve the Quadratic Assignment Problem with Warm-Started MCMC Finetuning
Apr 22, 2026The quadratic assignment problem (QAP) is a fundamental NP-hard task that poses significant challenges for both traditional heuristics and modern learning-based solvers. Existing QAP solvers still struggle to achieve consistently competitive performance across structurally diverse real-world instances. To bridge this performance gap, we propose PLMA, an innovative permutation learning framework. PLMA features an efficient warm-started MCMC finetuning procedure to enhance deployment-time performance, leveraging short Markov chains to anchor the adaptation to the promising regions previously explored. For rapid exploration via MCMC over the permutation space, we design an additive energy-based model (EBM) that enables an $O(1)$-time 2-swap Metropolis-Hastings sampling step. Moreover, the neural network used to parameterize the EBM incorporates a scalable and flexible cross-graph attention mechanism to model interactions between facilities and locations in the QAP. Extensive experiments demonstrate that PLMA consistently outperforms state-of-the-art baselines across various benchmarks. In particular, PLMA achieves a near-zero average optimality gap on QAPLIB, exhibits remarkably superior robustness on the notoriously difficult Taixxeyy instances, and also serves as an effective QAP solver in bandwidth minimization.
A Learning Method with Gap-Aware Generation for Heterogeneous DAG Scheduling
Mar 24, 2026Efficient scheduling of directed acyclic graphs (DAGs) in heterogeneous environments is challenging due to resource capacities and dependencies. In practice, the need for adaptability across environments with varying resource pools and task types, alongside rapid schedule generation, complicates these challenges. We propose WeCAN, an end-to-end reinforcement learning framework for heterogeneous DAG scheduling that addresses task--pool compatibility coefficients and generation-induced optimality gaps. It adopts a two-stage single-pass design: a single forward pass produces task--pool scores and global parameters, followed by a generation map that constructs schedules without repeated network calls. Its weighted cross-attention encoder models task--pool interactions gated by compatibility coefficients, and is size-agnostic to environment fluctuations. Moreover, widely used list-scheduling maps can incur generation-induced optimality gaps from restricted reachability. We introduce an order-space analysis that characterizes the reachable set of generation maps via feasible schedule orders, explains the mechanism behind generation-induced gaps, and yields sufficient conditions for gap elimination. Guided by these conditions, we design a skip-extended realization with an analytically parameterized decreasing skip rule, which enlarges the reachable order set while preserving single-pass efficiency. Experiments on computation graphs and real-world TPC-H DAGs demonstrate improved makespan over strong baselines, with inference time comparable to classical heuristics and faster than multi-round neural schedulers.
Accelerating LLM Pre-Training through Flat-Direction Dynamics Enhancement
Feb 26, 2026Pre-training Large Language Models requires immense computational resources, making optimizer efficiency essential. The optimization landscape is highly anisotropic, with loss reduction driven predominantly by progress along flat directions. While matrix-based optimizers such as Muon and SOAP leverage fine-grained curvature information to outperform AdamW, their updates tend toward isotropy -- relatively conservative along flat directions yet potentially aggressive along sharp ones. To address this limitation, we first establish a unified Riemannian Ordinary Differential Equation (ODE) framework that elucidates how common adaptive algorithms operate synergistically: the preconditioner induces a Riemannian geometry that mitigates ill-conditioning, while momentum serves as a Riemannian damping term that promotes convergence. Guided by these insights, we propose LITE, a generalized acceleration strategy that enhances training dynamics by applying larger Hessian damping coefficients and learning rates along flat trajectories. Extensive experiments demonstrate that LITE significantly accelerates both Muon and SOAP across diverse architectures (Dense, MoE), parameter scales (130M--1.3B), datasets (C4, Pile), and learning-rate schedules (cosine, warmup-stable-decay). Theoretical analysis confirms that LITE facilitates faster convergence along flat directions in anisotropic landscapes, providing a principled approach to efficient LLM pre-training. The code is available at https://github.com/SHUCHENZHU/LITE.
M2F: Automated Formalization of Mathematical Literature at Scale
Feb 19, 2026Automated formalization of mathematics enables mechanical verification but remains limited to isolated theorems and short snippets. Scaling to textbooks and research papers is largely unaddressed, as it requires managing cross-file dependencies, resolving imports, and ensuring that entire projects compile end-to-end. We present M2F (Math-to-Formal), the first agentic framework for end-to-end, project-scale autoformalization in Lean. The framework operates in two stages. The statement compilation stage splits the document into atomic blocks, orders them via inferred dependencies, and repairs declaration skeletons until the project compiles, allowing placeholders in proofs. The proof repair stage closes these holes under fixed signatures using goal-conditioned local edits. Throughout both stages, M2F keeps the verifier in the loop, committing edits only when toolchain feedback confirms improvement. In approximately three weeks, M2F converts long-form mathematical sources into a project-scale Lean library of 153,853 lines from 479 pages textbooks on real analysis and convex analysis, fully formalized as Lean declarations with accompanying proofs. This represents textbook-scale formalization at a pace that would typically require months or years of expert effort. On FATE-H, we achieve $96\%$ proof success (vs.\ $80\%$ for a strong baseline). Together, these results demonstrate that practical, large-scale automated formalization of mathematical literature is within reach. The full generated Lean code from our runs is available at https://github.com/optsuite/ReasBook.git.
Constructing Industrial-Scale Optimization Modeling Benchmark
Feb 11, 2026Optimization modeling underpins decision-making in logistics, manufacturing, energy, and finance, yet translating natural-language requirements into correct optimization formulations and solver-executable code remains labor-intensive. Although large language models (LLMs) have been explored for this task, evaluation is still dominated by toy-sized or synthetic benchmarks, masking the difficulty of industrial problems with $10^{3}$--$10^{6}$ (or more) variables and constraints. A key bottleneck is the lack of benchmarks that align natural-language specifications with reference formulations/solver code grounded in real optimization models. To fill in this gap, we introduce MIPLIB-NL, built via a structure-aware reverse construction methodology from real mixed-integer linear programs in MIPLIB~2017. Our pipeline (i) recovers compact, reusable model structure from flat solver formulations, (ii) reverse-generates natural-language specifications explicitly tied to this recovered structure under a unified model--data separation format, and (iii) performs iterative semantic validation through expert review and human--LLM interaction with independent reconstruction checks. This yields 223 one-to-one reconstructions that preserve the mathematical content of the original instances while enabling realistic natural-language-to-optimization evaluation. Experiments show substantial performance degradation on MIPLIB-NL for systems that perform strongly on existing benchmarks, exposing failure modes invisible at toy scale.
Non-Asymptotic Global Convergence of PPO-Clip
Dec 18, 2025
Reinforcement learning (RL) has gained attention for aligning large language models (LLMs) via reinforcement learning from human feedback (RLHF). The actor-only variants of Proximal Policy Optimization (PPO) are widely applied for their efficiency. These algorithms incorporate a clipping mechanism to improve stability. Besides, a regularization term, such as the reverse KL-divergence or a more general \(f\)-divergence, is introduced to prevent policy drift. Despite their empirical success, a rigorous theoretical understanding of the problem and the algorithm's properties is limited. This paper advances the theoretical foundations of the PPO-Clip algorithm by analyzing a deterministic actor-only PPO algorithm within the general RL setting with \(f\)-divergence regularization under the softmax policy parameterization. We derive a non-uniform Lipschitz smoothness condition and a Łojasiewicz inequality for the considered problem. Based on these, a non-asymptotic linear convergence rate to the globally optimal policy is established for the forward KL-regularizer. Furthermore, stationary convergence and local linear convergence are derived for the reverse KL-regularizer.
Translating Informal Proofs into Formal Proofs Using a Chain of States
Dec 12, 2025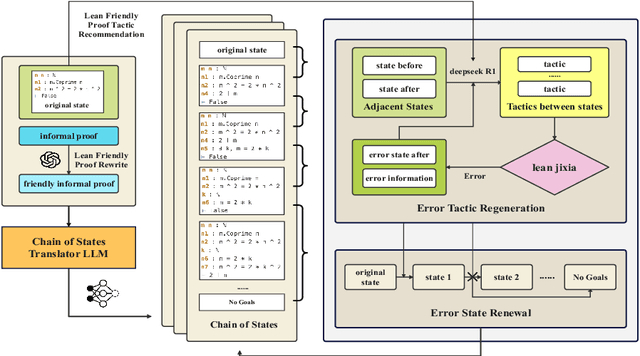
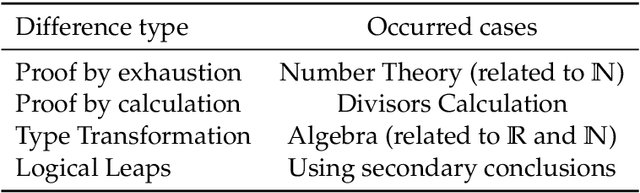

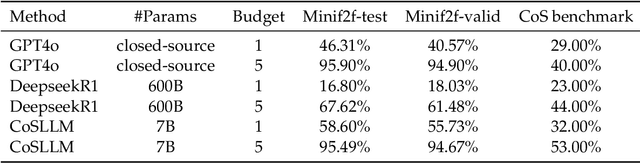
We address the problem of translating informal mathematical proofs expressed in natural language into formal proofs in Lean4 under a constrained computational budget. Our approach is grounded in two key insights. First, informal proofs tend to proceed via a sequence of logical transitions - often implications or equivalences - without explicitly specifying intermediate results or auxiliary lemmas. In contrast, formal systems like Lean require an explicit representation of each proof state and the tactics that connect them. Second, each informal reasoning step can be viewed as an abstract transformation between proof states, but identifying the corresponding formal tactics often requires nontrivial domain knowledge and precise control over proof context. To bridge this gap, we propose a two stage framework. Rather than generating formal tactics directly, we first extract a Chain of States (CoS), a sequence of intermediate formal proof states aligned with the logical structure of the informal argument. We then generate tactics to transition between adjacent states in the CoS, thereby constructing the full formal proof. This intermediate representation significantly reduces the complexity of tactic generation and improves alignment with informal reasoning patterns. We build dedicated datasets and benchmarks for training and evaluation, and introduce an interactive framework to support tactic generation from formal states. Empirical results show that our method substantially outperforms existing baselines, achieving higher proof success rates.
Advancing Mathematical Research via Human-AI Interactive Theorem Proving
Dec 11, 2025We investigate how large language models can be used as research tools in scientific computing while preserving mathematical rigor. We propose a human-in-the-loop workflow for interactive theorem proving and discovery with LLMs. Human experts retain control over problem formulation and admissible assumptions, while the model searches for proofs or contradictions, proposes candidate properties and theorems, and helps construct structures and parameters that satisfy explicit constraints, supported by numerical experiments and simple verification checks. Experts treat these outputs as raw material, further refine them, and organize the results into precise statements and rigorous proofs. We instantiate this workflow in a case study on the connection between manifold optimization and Grover's quantum search algorithm, where the pipeline helps identify invariant subspaces, explore Grover-compatible retractions, and obtain convergence guarantees for the retraction-based gradient method. The framework provides a practical template for integrating large language models into frontier mathematical research, enabling faster exploration of proof space and algorithm design while maintaining transparent reasoning responsibilities. Although illustrated on manifold optimization problems in quantum computing, the principles extend to other core areas of scientific computing.