 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemVideo: Reconstructs What You Watch from Brain Activity via Hierarchical Semantic Guidance
Feb 25, 2026Reconstructing dynamic visual experiences from brain activity provides a compelling avenue for exploring the neural mechanisms of human visual perception. While recent progress in fMRI-based image reconstruction has been notable, extending this success to video reconstruction remains a significant challenge. Current fMRI-to-video reconstruction approaches consistently encounter two major shortcomings: (i) inconsistent visual representations of salient objects across frames, leading to appearance mismatches; (ii) poor temporal coherence, resulting in motion misalignment or abrupt frame transitions. To address these limitations, we introduce SemVideo, a novel fMRI-to-video reconstruction framework guided by hierarchical semantic information. At the core of SemVideo is SemMiner, a hierarchical guidance module that constructs three levels of semantic cues from the original video stimulus: static anchor descriptions, motion-oriented narratives, and holistic summaries. Leveraging this semantic guidance, SemVideo comprises three key components: a Semantic Alignment Decoder that aligns fMRI signals with CLIP-style embeddings derived from SemMiner, a Motion Adaptation Decoder that reconstructs dynamic motion patterns using a novel tripartite attention fusion architecture, and a Conditional Video Render that leverages hierarchical semantic guidance for video reconstruction. Experiments conducted on the CC2017 and HCP datasets demonstrate that SemVideo achieves superior performance in both semantic alignment and temporal consistency, setting a new state-of-the-art in fMRI-to-video reconstruction.
SynMind: Reducing Semantic Hallucination in fMRI-Based Image Reconstruction
Jan 25, 2026Recent advances in fMRI-based image reconstruction have achieved remarkable photo-realistic fidelity. Yet, a persistent limitation remains: while reconstructed images often appear naturalistic and holistically similar to the target stimuli, they frequently suffer from severe semantic misalignment -- salient objects are often replaced or hallucinated despite high visual quality. In this work, we address this limitation by rethinking the role of explicit semantic interpretation in fMRI decoding. We argue that existing methods rely too heavily on entangled visual embeddings which prioritize low-level appearance cues -- such as texture and global gist -- over explicit semantic identity. To overcome this, we parse fMRI signals into rich, sentence-level semantic descriptions that mirror the hierarchical and compositional nature of human visual understanding. We achieve this by leveraging grounded VLMs to generate synthetic, human-like, multi-granularity textual representations that capture object identities and spatial organization. Built upon this foundation, we propose SynMind, a framework that integrates these explicit semantic encodings with visual priors to condition a pretrained diffusion model. Extensive experiments demonstrate that SynMind outperforms state-of-the-art methods across most quantitative metrics. Notably, by offloading semantic reasoning to our text-alignment module, SynMind surpasses competing methods based on SDXL while using the much smaller Stable Diffusion 1.4 and a single consumer GPU. Large-scale human evaluations further confirm that SynMind produces reconstructions more consistent with human visual perception. Neurovisualization analyses reveal that SynMind engages broader and more semantically relevant brain regions, mitigating the over-reliance on high-level visual areas.
V-Thinker: Interactive Thinking with Images
Nov 06, 2025Empowering Large Multimodal Models (LMMs) to deeply integrate image interaction with long-horizon reasoning capabilities remains a long-standing challenge in this field. Recent advances in vision-centric reasoning explore a promising "Thinking with Images" paradigm for LMMs, marking a shift from image-assisted reasoning to image-interactive thinking. While this milestone enables models to focus on fine-grained image regions, progress remains constrained by limited visual tool spaces and task-specific workflow designs. To bridge this gap, we present V-Thinker, a general-purpose multimodal reasoning assistant that enables interactive, vision-centric thinking through end-to-end reinforcement learning. V-Thinker comprises two key components: (1) a Data Evolution Flywheel that automatically synthesizes, evolves, and verifies interactive reasoning datasets across three dimensions-diversity, quality, and difficulty; and (2) a Visual Progressive Training Curriculum that first aligns perception via point-level supervision, then integrates interactive reasoning through a two-stage reinforcement learning framework. Furthermore, we introduce VTBench, an expert-verified benchmark targeting vision-centric interactive reasoning tasks. Extensive experiments demonstrate that V-Thinker consistently outperforms strong LMM-based baselines in both general and interactive reasoning scenarios, providing valuable insights for advancing image-interactive reasoning applications.
Riemannian Natural Gradient Methods
Jul 15, 2022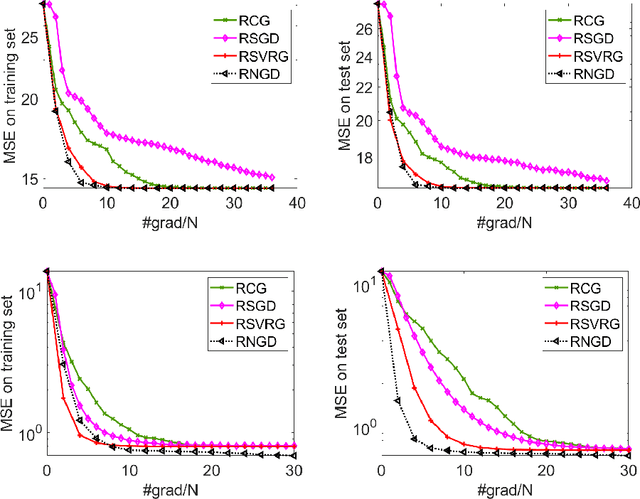
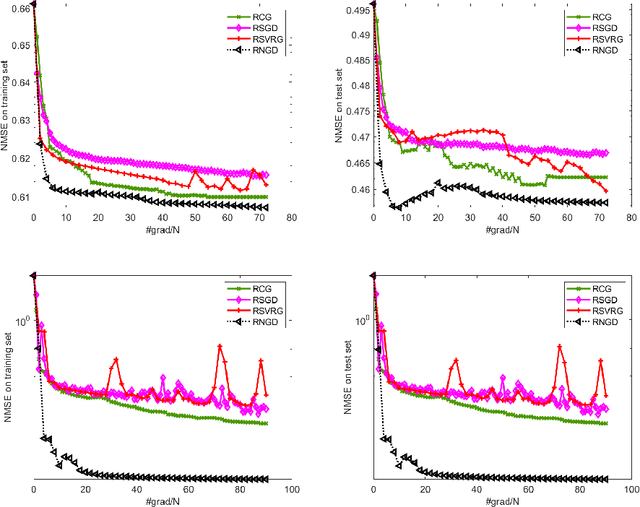
This paper studies large-scale optimization problems on Riemannian manifolds whose objective function is a finite sum of negative log-probability losses. Such problems arise in various machine learning and signal processing applications. By introducing the notion of Fisher information matrix in the manifold setting, we propose a novel Riemannian natural gradient method, which can be viewed as a natural extension of the natural gradient method from the Euclidean setting to the manifold setting. We establish the almost-sure global convergence of our proposed method under standard assumptions. Moreover, we show that if the loss function satisfies certain convexity and smoothness conditions and the input-output map satisfies a Riemannian Jacobian stability condition, then our proposed method enjoys a local linear -- or, under the Lipschitz continuity of the Riemannian Jacobian of the input-output map, even quadratic -- rate of convergence. We then prove that the Riemannian Jacobian stability condition will be satisfied by a two-layer fully connected neural network with batch normalization with high probability, provided that the width of the network is sufficiently large. This demonstrates the practical relevance of our convergence rate result. Numerical experiments on applications arising from machine learning demonstrate the advantages of the proposed method over state-of-the-art ones.
NG+ : A Multi-Step Matrix-Product Natural Gradient Method for Deep Learning
Jun 14, 2021



In this paper, a novel second-order method called NG+ is proposed. By following the rule ``the shape of the gradient equals the shape of the parameter", we define a generalized fisher information matrix (GFIM) using the products of gradients in the matrix form rather than the traditional vectorization. Then, our generalized natural gradient direction is simply the inverse of the GFIM multiplies the gradient in the matrix form. Moreover, the GFIM and its inverse keeps the same for multiple steps so that the computational cost can be controlled and is comparable with the first-order methods. A global convergence is established under some mild conditions and a regret bound is also given for the online learning setting. Numerical results on image classification with ResNet50, quantum chemistry modeling with Schnet, neural machine translation with Transformer and recommendation system with DLRM illustrate that GN+ is competitive with the state-of-the-art methods.
Structured Stochastic Quasi-Newton Methods for Large-Scale Optimization Problems
Jun 17, 2020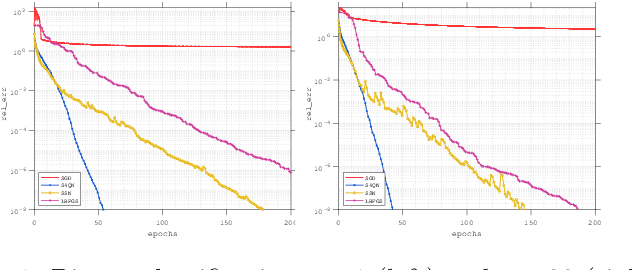

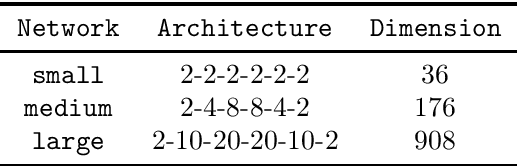
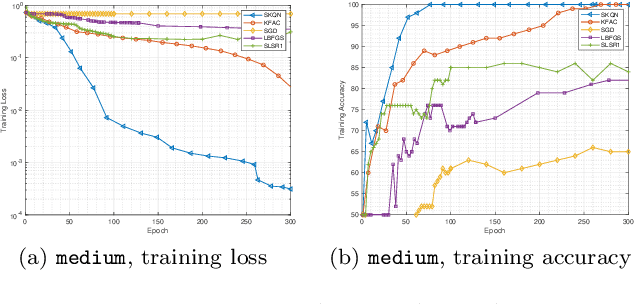
In this paper, we consider large-scale finite-sum nonconvex problems arising from machine learning. Since the Hessian is often a summation of a relative cheap and accessible part and an expensive or even inaccessible part, a stochastic quasi-Newton matrix is constructed using partial Hessian information as much as possible. By further exploiting the low-rank structures based on the Nystr\"om approximation, the computation of the quasi-Newton direction is affordable. To make full use of the gradient estimation, we also develop an extra-step strategy for this framework. Global convergence to stationary point in expectation and local suplinear convergence rate are established under some mild assumptions. Numerical experiments on logistic regression, deep autoencoder networks and deep learning problems show that the efficiency of our proposed method is at least comparable with the state-of-the-art methods.
Sketchy Empirical Natural Gradient Methods for Deep Learning
Jun 16, 2020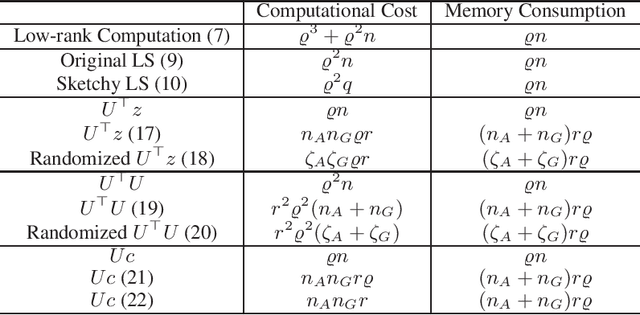
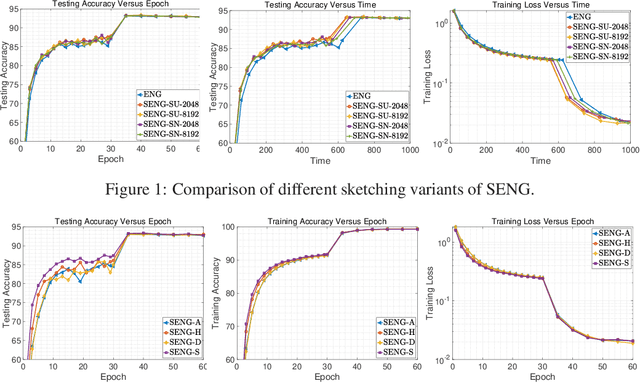
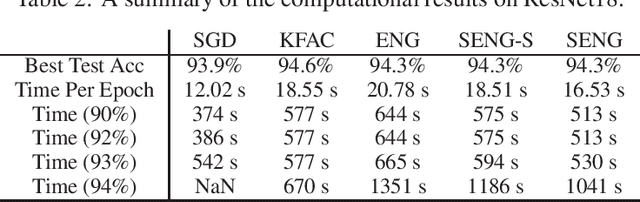
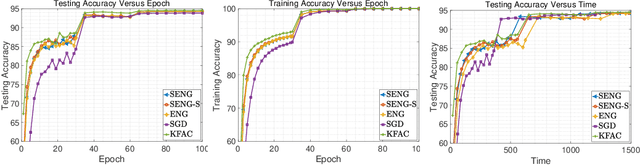
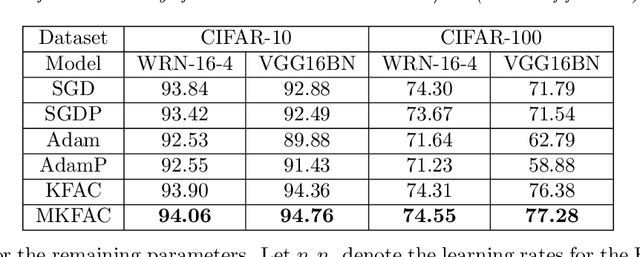
In this paper, we develop an efficient sketchy empirical natural gradient method for large-scale finite-sum optimization problems from deep learning. The empirical Fisher information matrix is usually low-rank since the sampling is only practical on a small amount of data at each iteration. Although the corresponding natural gradient direction lies in a small subspace, both the computational cost and memory requirement are still not tractable due to the curse of dimensionality. We design randomized techniques for different neural network structures to resolve these challenges. For layers with a reasonable dimension, a sketching can be performed on a regularized least squares subproblem. Otherwise, since the gradient is a vectorization of the product between two matrices, we apply sketching on low-rank approximation of these matrices to compute the most expensive parts. Global convergence to stationary point is established under some mild assumptions. Numerical results on deep convolution networks illustrate that our method is quite competitive to the state-of-the-art methods such as SGD and KFAC.
A Stochastic Extra-Step Quasi-Newton Method for Nonsmooth Nonconvex Optimization
Oct 21, 2019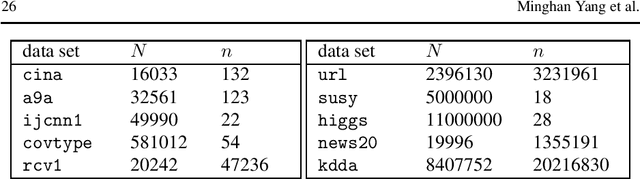
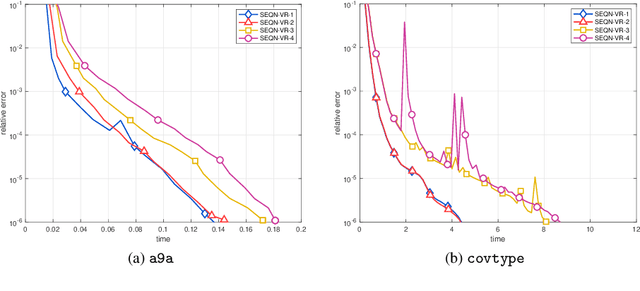
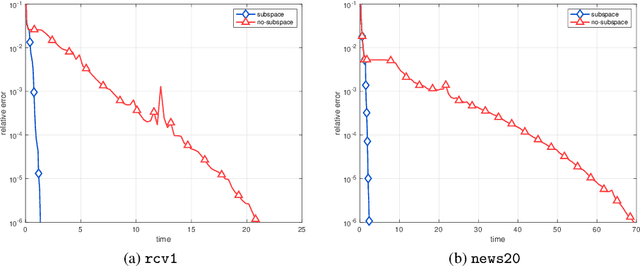
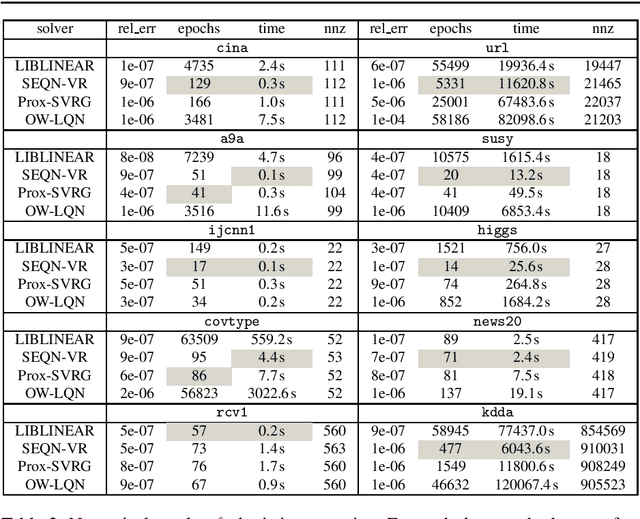
In this paper, a novel stochastic extra-step quasi-Newton method is developed to solve a class of nonsmooth nonconvex composite optimization problems. We assume that the gradient of the smooth part of the objective function can only be approximated by stochastic oracles. The proposed method combines general stochastic higher order steps derived from an underlying proximal type fixed-point equation with additional stochastic proximal gradient steps to guarantee convergence. Based on suitable bounds on the step sizes, we establish global convergence to stationary points in expectation and an extension of the approach using variance reduction techniques is discussed. Motivated by large-scale and big data applications, we investigate a stochastic coordinate-type quasi-Newton scheme that allows to generate cheap and tractable stochastic higher order directions. Finally, the proposed algorithm is tested on large-scale logistic regression and deep learning problems and it is shown that it compares favorably with other state-of-the-art methods.