 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest Arm Identification with LLM Judges and Limited Human
Jan 29, 2026We study fixed-confidence best-arm identification (BAI) where a cheap but potentially biased proxy (e.g., LLM judge) is available for every sample, while an expensive ground-truth label can only be acquired selectively when using a human for auditing. Unlike classical multi-fidelity BAI, the proxy is biased (arm- and context-dependent) and ground truth is selectively observed. Consequently, standard multi-fidelity methods can mis-select the best arm, and uniform auditing, though accurate, wastes scarce resources and is inefficient. We prove that without bias correction and propensity adjustment, mis-selection probability may not vanish (even with unlimited proxy data). We then develop an estimator for the mean of each arm that combines proxy scores with inverse-propensity-weighted residuals and form anytime-valid confidence sequences for that estimator. Based on the estimator and confidence sequence, we propose an algorithm that adaptively selects and audits arms. The algorithm concentrates audits on unreliable contexts and close arms and we prove that a plug-in Neyman rule achieves near-oracle audit efficiency. Numerical experiments confirm the theoretical guarantees and demonstrate the superior empirical performance of the proposed algorithm.
PPI-SVRG: Unifying Prediction-Powered Inference and Variance Reduction for Semi-Supervised Optimization
Jan 29, 2026We study semi-supervised stochastic optimization when labeled data is scarce but predictions from pre-trained models are available. PPI and SVRG both reduce variance through control variates -- PPI uses predictions, SVRG uses reference gradients. We show they are mathematically equivalent and develop PPI-SVRG, which combines both. Our convergence bound decomposes into the standard SVRG rate plus an error floor from prediction uncertainty. The rate depends only on loss geometry; predictions affect only the neighborhood size. When predictions are perfect, we recover SVRG exactly. When predictions degrade, convergence remains stable but reaches a larger neighborhood. Experiments confirm the theory: PPI-SVRG reduces MSE by 43--52\% under label scarcity on mean estimation benchmarks and improves test accuracy by 2.7--2.9 percentage points on MNIST with only 10\% labeled data.
Solver-in-the-Loop: MDP-Based Benchmarks for Self-Correction and Behavioral Rationality in Operations Research
Jan 28, 2026Operations Research practitioners routinely debug infeasible models through an iterative process: analyzing Irreducible Infeasible Subsystems (\IIS{}), identifying constraint conflicts, and systematically repairing formulations until feasibility is achieved. Yet existing LLM benchmarks evaluate OR as one-shot translation -- given a problem description, generate solver code -- ignoring this diagnostic loop entirely. We introduce two benchmarks that place the \textbf{solver in the evaluation loop}. \textbf{\ORDebug{}} evaluates iterative self-correction through 5,000+ problems spanning 9 error types; each repair action triggers solver re-execution and \IIS{} recomputation, providing deterministic, verifiable feedback. \textbf{\ORBias{}} evaluates behavioral rationality through 2,000 newsvendor instances (1,000 ID + 1,000 OOD), measuring systematic deviations from closed-form optimal policies. Across 26 models and 12,000+ samples, we find that domain-specific RLVR training enables an 8B model to surpass frontier APIs: 95.3\% vs 86.2\% recovery rate (+9.1\%), 62.4\% vs 47.8\% diagnostic accuracy (+14.6\%), and 2.25 vs 3.78 steps to resolution (1.7$\times$ faster). On \ORBias{}, curriculum training achieves the only negative ID$\rightarrow$OOD bias drift among models evaluated (-9.6\%), reducing systematic bias by 48\% (from 20.0\% to 10.4\%). These results demonstrate that process-level evaluation with verifiable oracles enables targeted training that outperforms scale.
Optimizing LLM Inference: Fluid-Guided Online Scheduling with Memory Constraints
Apr 15, 2025



Large Language Models (LLMs) are indispensable in today's applications, but their inference procedure -- generating responses by processing text in segments and using a memory-heavy Key-Value (KV) cache -- demands significant computational resources, particularly under memory constraints. This paper formulates LLM inference optimization as a multi-stage online scheduling problem where sequential prompt arrivals and KV cache growth render conventional scheduling ineffective. We develop a fluid dynamics approximation to provide a tractable benchmark that guides algorithm design. Building on this, we propose the Waiting for Accumulated Inference Threshold (WAIT) algorithm, which uses multiple thresholds to schedule incoming prompts optimally when output lengths are known, and extend it to Nested WAIT for cases with unknown output lengths. Theoretical analysis shows that both algorithms achieve near-optimal performance against the fluid benchmark in heavy traffic conditions, balancing throughput, latency, and Time to First Token (TTFT). Experiments with the Llama-7B model on an A100 GPU using both synthetic and real-world datasets demonstrate improved throughput and reduced latency relative to established baselines like vLLM and Sarathi. This work bridges operations research and machine learning, offering a rigorous framework for the efficient deployment of LLMs under memory constraints.
Learning to Price with Resource Constraints: From Full Information to Machine-Learned Prices
Jan 24, 2025



We study the dynamic pricing problem with knapsack, addressing the challenge of balancing exploration and exploitation under resource constraints. We introduce three algorithms tailored to different informational settings: a Boundary Attracted Re-solve Method for full information, an online learning algorithm for scenarios with no prior information, and an estimate-then-select re-solve algorithm that leverages machine-learned informed prices with known upper bound of estimation errors. The Boundary Attracted Re-solve Method achieves logarithmic regret without requiring the non-degeneracy condition, while the online learning algorithm attains an optimal $O(\sqrt{T})$ regret. Our estimate-then-select approach bridges the gap between these settings, providing improved regret bounds when reliable offline data is available. Numerical experiments validate the effectiveness and robustness of our algorithms across various scenarios. This work advances the understanding of online resource allocation and dynamic pricing, offering practical solutions adaptable to different informational structures.
Prediction-Guided Active Experiments
Nov 20, 2024In this work, we introduce a new framework for active experimentation, the Prediction-Guided Active Experiment (PGAE), which leverages predictions from an existing machine learning model to guide sampling and experimentation. Specifically, at each time step, an experimental unit is sampled according to a designated sampling distribution, and the actual outcome is observed based on an experimental probability. Otherwise, only a prediction for the outcome is available. We begin by analyzing the non-adaptive case, where full information on the joint distribution of the predictor and the actual outcome is assumed. For this scenario, we derive an optimal experimentation strategy by minimizing the semi-parametric efficiency bound for the class of regular estimators. We then introduce an estimator that meets this efficiency bound, achieving asymptotic optimality. Next, we move to the adaptive case, where the predictor is continuously updated with newly sampled data. We show that the adaptive version of the estimator remains efficient and attains the same semi-parametric bound under certain regularity assumptions. Finally, we validate PGAE's performance through simulations and a semi-synthetic experiment using data from the US Census Bureau. The results underscore the PGAE framework's effectiveness and superiority compared to other existing methods.
Online Local False Discovery Rate Control: A Resource Allocation Approach
Feb 18, 2024We consider the problem of online local false discovery rate (FDR) control where multiple tests are conducted sequentially, with the goal of maximizing the total expected number of discoveries. We formulate the problem as an online resource allocation problem with accept/reject decisions, which from a high level can be viewed as an online knapsack problem, with the additional uncertainty of random budget replenishment. We start with general arrival distributions and propose a simple policy that achieves a $O(\sqrt{T})$ regret. We complement the result by showing that such regret rate is in general not improvable. We then shift our focus to discrete arrival distributions. We find that many existing re-solving heuristics in the online resource allocation literature, albeit achieve bounded loss in canonical settings, may incur a $\Omega(\sqrt{T})$ or even a $\Omega(T)$ regret. With the observation that canonical policies tend to be too optimistic and over accept arrivals, we propose a novel policy that incorporates budget buffers. We show that small additional logarithmic buffers suffice to reduce the regret from $\Omega(\sqrt{T})$ or even $\Omega(T)$ to $O(\ln^2 T)$. Numerical experiments are conducted to validate our theoretical findings. Our formulation may have wider applications beyond the problem considered in this paper, and our results emphasize how effective policies should be designed to reach a balance between circumventing wrong accept and reducing wrong reject in online resource allocation problems with uncertain budgets.
Asynchronous Gradient Play in Zero-Sum Multi-agent Games
Nov 16, 2022


Finding equilibria via gradient play in competitive multi-agent games has been attracting a growing amount of attention in recent years, with emphasis on designing efficient strategies where the agents operate in a decentralized and symmetric manner with guaranteed convergence. While significant efforts have been made in understanding zero-sum two-player matrix games, the performance in zero-sum multi-agent games remains inadequately explored, especially in the presence of delayed feedbacks, leaving the scalability and resiliency of gradient play open to questions. In this paper, we make progress by studying asynchronous gradient plays in zero-sum polymatrix games under delayed feedbacks. We first establish that the last iterate of entropy-regularized optimistic multiplicative weight updates (OMWU) method converges linearly to the quantal response equilibrium (QRE), the solution concept under bounded rationality, in the absence of delays. While the linear convergence continues to hold even when the feedbacks are randomly delayed under mild statistical assumptions, it converges at a noticeably slower rate due to a smaller tolerable range of learning rates. Moving beyond, we demonstrate entropy-regularized OMWU -- by adopting two-timescale learning rates in a delay-aware manner -- enjoys faster last-iterate convergence under fixed delays, and continues to converge provably even when the delays are arbitrarily bounded in an average-iterate manner. Our methods also lead to finite-time guarantees to approximate the Nash equilibrium (NE) by moderating the amount of regularization. To the best of our knowledge, this work is the first that aims to understand asynchronous gradient play in zero-sum polymatrix games under a wide range of delay assumptions, highlighting the role of learning rates separation.
Riemannian Natural Gradient Methods
Jul 15, 2022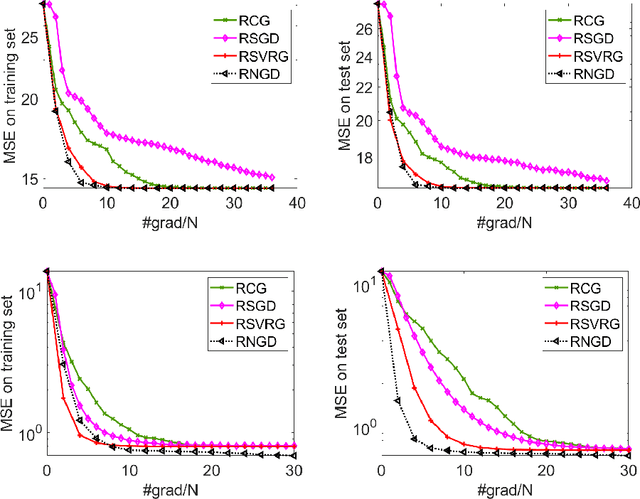
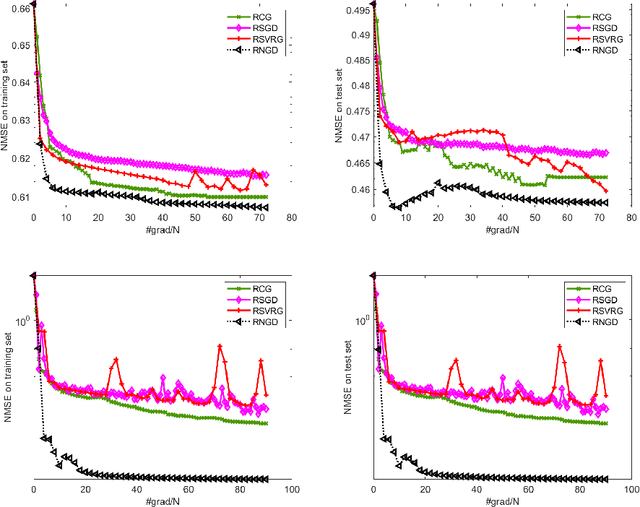
This paper studies large-scale optimization problems on Riemannian manifolds whose objective function is a finite sum of negative log-probability losses. Such problems arise in various machine learning and signal processing applications. By introducing the notion of Fisher information matrix in the manifold setting, we propose a novel Riemannian natural gradient method, which can be viewed as a natural extension of the natural gradient method from the Euclidean setting to the manifold setting. We establish the almost-sure global convergence of our proposed method under standard assumptions. Moreover, we show that if the loss function satisfies certain convexity and smoothness conditions and the input-output map satisfies a Riemannian Jacobian stability condition, then our proposed method enjoys a local linear -- or, under the Lipschitz continuity of the Riemannian Jacobian of the input-output map, even quadratic -- rate of convergence. We then prove that the Riemannian Jacobian stability condition will be satisfied by a two-layer fully connected neural network with batch normalization with high probability, provided that the width of the network is sufficiently large. This demonstrates the practical relevance of our convergence rate result. Numerical experiments on applications arising from machine learning demonstrate the advantages of the proposed method over state-of-the-art ones.