 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Epoch Adaptive Rollout Optimization for RL Post-Training
Jun 04, 2026LLM post-training often relies on reinforcement learning methods that sample multiple rollouts per prompt, yet most existing approaches use a fixed rollout budget for every prompt, despite large differences in the training signal different prompts provide. In this paper, we study adaptive rollout allocation under a fixed global budget and formulate the problem as online resource allocation with prompt-level diminishing returns. Our method, CERO, maintains a Beta posterior over each prompt's success probability and uses the posterior expected Bernoulli variance as a Bayesian estimate of the value of additional rollouts. We use this estimate to construct a concave, saturating utility over cumulative allocations, yielding an objective in which decisions across prompts and epochs are coupled by the global budget. Since the resulting objective is temporally nonseparable, we derive a Fenchel-dual reformulation and update both prompt-level and budget-level dual variables via projected online gradient descent. Under fixed prompt utilities, we prove an $O(\sqrt{K})$ regret bound against the offline allocation benchmark. Experiments on mathematical-reasoning problems show that CERO consistently outperforms GRPO across multiple open-weight LLMs and benchmarks, demonstrating that adaptive rollout budgeting can improve sample efficiency.
Resource-Constrained Adaptive Inference for Sequential Pricing
Jun 02, 2026Resource-constrained pricing controllers can make fixed-price inference impossible: the controller's resource state may remove the target price neighborhood from the feasible set, even when every realized action has a known positive density. We formalize this support-exclusion failure through a local non-identification result and a realized information clock. We then design a target-aware pricing controller that certifies feasible target bands and logs continuous local densities. Localized debiasing gives studentized intervals whose width is governed by this clock. The resulting regret--information accounting, stated up to pilot re-solving error, shows that cheap exploration can be insufficient for inference: polynomial target mass gives polynomial rates, while a pure $1/t$ target branch does not yield shrinking fixed-target intervals without additional local movement. Experiments show calibration in certified bands and diagnostic abstention when the resource state collapses target support.
The Value of Information in Resource-Constrained Pricing
Mar 26, 2026Firms that price perishable resources -- airline seats, hotel rooms, seasonal inventory -- now routinely use demand predictions, but these predictions vary widely in quality. Under hard capacity constraints, acting on an inaccurate prediction can irreversibly deplete inventory needed for future periods. We study how prediction uncertainty propagates into dynamic pricing decisions with linear demand, stochastic noise, and finite capacity. A certified demand forecast with known error bound~$ε^0$ specifies where the system should operate: it shifts regret from $O(\sqrt{T})$ to $O(\log T)$ when $ε^0 \lesssim T^{-1/4}$, and we prove this threshold is tight. A misspecified surrogate model -- biased but correlated with true demand -- cannot set prices directly but reduces learning variance by a factor of $(1-ρ^2)$ through control variates. The two mechanisms compose: the forecast determines the regret regime; the surrogate tightens estimation within it. All algorithms rest on a boundary attraction mechanism that stabilizes pricing near degenerate capacity boundaries without requiring non-degeneracy assumptions. Experiments confirm the phase transition threshold, the variance reduction from surrogates, and robustness across problem instances.
Online Semi-infinite Linear Programming: Efficient Algorithms via Function Approximation
Mar 17, 2026We consider the dynamic resource allocation problem where the decision space is finite-dimensional, yet the solution must satisfy a large or even infinite number of constraints revealed via streaming data or oracle feedback. We model this challenge as an Online Semi-infinite Linear Programming (OSILP) problem and develop a novel LP formulation to solve it approximately. Specifically, we employ function approximation to reduce the number of constraints to a constant $q$. This addresses a key limitation of traditional online LP algorithms, whose regret bounds typically depend on the number of constraints, leading to poor performance in this setting. We propose a dual-based algorithm to solve our new formulation, which offers broad applicability through the selection of appropriate potential functions. We analyze this algorithm under two classical input models-stochastic input and random permutation-establishing regret bounds of $O(q\sqrt{T})$ and $O\left(\left(q+q\log{T})\sqrt{T}\right)\right)$ respectively. Note that both regret bounds are independent of the number of constraints, which demonstrates the potential of our approach to handle a large or infinite number of constraints. Furthermore, we investigate the potential to improve upon the $O(q\sqrt{T})$ regret and propose a two-stage algorithm, achieving $O(q\log{T} + q/ε)$ regret under more stringent assumptions. We also extend our algorithms to the general function setting. A series of experiments validates that our algorithms outperform existing methods when confronted with a large number of constraints.
Ask, Clarify, Optimize: Human-LLM Agent Collaboration for Smarter Inventory Control
Dec 31, 2025Inventory management remains a challenge for many small and medium-sized businesses that lack the expertise to deploy advanced optimization methods. This paper investigates whether Large Language Models (LLMs) can help bridge this gap. We show that employing LLMs as direct, end-to-end solvers incurs a significant "hallucination tax": a performance gap arising from the model's inability to perform grounded stochastic reasoning. To address this, we propose a hybrid agentic framework that strictly decouples semantic reasoning from mathematical calculation. In this architecture, the LLM functions as an intelligent interface, eliciting parameters from natural language and interpreting results while automatically calling rigorous algorithms to build the optimization engine. To evaluate this interactive system against the ambiguity and inconsistency of real-world managerial dialogue, we introduce the Human Imitator, a fine-tuned "digital twin" of a boundedly rational manager that enables scalable, reproducible stress-testing. Our empirical analysis reveals that the hybrid agentic framework reduces total inventory costs by 32.1% relative to an interactive baseline using GPT-4o as an end-to-end solver. Moreover, we find that providing perfect ground-truth information alone is insufficient to improve GPT-4o's performance, confirming that the bottleneck is fundamentally computational rather than informational. Our results position LLMs not as replacements for operations research, but as natural-language interfaces that make rigorous, solver-based policies accessible to non-experts.
A Lyapunov Drift-Plus-Penalty Method Tailored for Reinforcement Learning with Queue Stability
Jun 04, 2025With the proliferation of Internet of Things (IoT) devices, the demand for addressing complex optimization challenges has intensified. The Lyapunov Drift-Plus-Penalty algorithm is a widely adopted approach for ensuring queue stability, and some research has preliminarily explored its integration with reinforcement learning (RL). In this paper, we investigate the adaptation of the Lyapunov Drift-Plus-Penalty algorithm for RL applications, deriving an effective method for combining Lyapunov Drift-Plus-Penalty with RL under a set of common and reasonable conditions through rigorous theoretical analysis. Unlike existing approaches that directly merge the two frameworks, our proposed algorithm, termed Lyapunov drift-plus-penalty method tailored for reinforcement learning with queue stability (LDPTRLQ) algorithm, offers theoretical superiority by effectively balancing the greedy optimization of Lyapunov Drift-Plus-Penalty with the long-term perspective of RL. Simulation results for multiple problems demonstrate that LDPTRLQ outperforms the baseline methods using the Lyapunov drift-plus-penalty method and RL, corroborating the validity of our theoretical derivations. The results also demonstrate that our proposed algorithm outperforms other benchmarks in terms of compatibility and stability.
Adaptive Resolving Methods for Reinforcement Learning with Function Approximations
May 17, 2025


Reinforcement learning (RL) problems are fundamental in online decision-making and have been instrumental in finding an optimal policy for Markov decision processes (MDPs). Function approximations are usually deployed to handle large or infinite state-action space. In our work, we consider the RL problems with function approximation and we develop a new algorithm to solve it efficiently. Our algorithm is based on the linear programming (LP) reformulation and it resolves the LP at each iteration improved with new data arrival. Such a resolving scheme enables our algorithm to achieve an instance-dependent sample complexity guarantee, more precisely, when we have $N$ data, the output of our algorithm enjoys an instance-dependent $\tilde{O}(1/N)$ suboptimality gap. In comparison to the $O(1/\sqrt{N})$ worst-case guarantee established in the previous literature, our instance-dependent guarantee is tighter when the underlying instance is favorable, and the numerical experiments also reveal the efficient empirical performances of our algorithms.
Adaptive Bidding Policies for First-Price Auctions with Budget Constraints under Non-stationarity
May 05, 2025We study how a budget-constrained bidder should learn to adaptively bid in repeated first-price auctions to maximize her cumulative payoff. This problem arose due to an industry-wide shift from second-price auctions to first-price auctions in display advertising recently, which renders truthful bidding (i.e., always bidding one's private value) no longer optimal. We propose a simple dual-gradient-descent-based bidding policy that maintains a dual variable for budget constraint as the bidder consumes her budget. In analysis, we consider two settings regarding the bidder's knowledge of her private values in the future: (i) an uninformative setting where all the distributional knowledge (can be non-stationary) is entirely unknown to the bidder, and (ii) an informative setting where a prediction of the budget allocation in advance. We characterize the performance loss (or regret) relative to an optimal policy with complete information on the stochasticity. For uninformative setting, We show that the regret is \tilde{O}(\sqrt{T}) plus a variation term that reflects the non-stationarity of the value distributions, and this is of optimal order. We then show that we can get rid of the variation term with the help of the prediction; specifically, the regret is \tilde{O}(\sqrt{T}) plus the prediction error term in the informative setting.
Efficiently Solving Discounted MDPs with Predictions on Transition Matrices
Feb 21, 2025


We study infinite-horizon Discounted Markov Decision Processes (DMDPs) under a generative model. Motivated by the Algorithm with Advice framework Mitzenmacher and Vassilvitskii 2022, we propose a novel framework to investigate how a prediction on the transition matrix can enhance the sample efficiency in solving DMDPs and improve sample complexity bounds. We focus on the DMDPs with $N$ state-action pairs and discounted factor $\gamma$. Firstly, we provide an impossibility result that, without prior knowledge of the prediction accuracy, no sampling policy can compute an $\epsilon$-optimal policy with a sample complexity bound better than $\tilde{O}((1-\gamma)^{-3} N\epsilon^{-2})$, which matches the state-of-the-art minimax sample complexity bound with no prediction. In complement, we propose an algorithm based on minimax optimization techniques that leverages the prediction on the transition matrix. Our algorithm achieves a sample complexity bound depending on the prediction error, and the bound is uniformly better than $\tilde{O}((1-\gamma)^{-4} N \epsilon^{-2})$, the previous best result derived from convex optimization methods. These theoretical findings are further supported by our numerical experiments.
Online Scheduling for LLM Inference with KV Cache Constraints
Feb 10, 2025
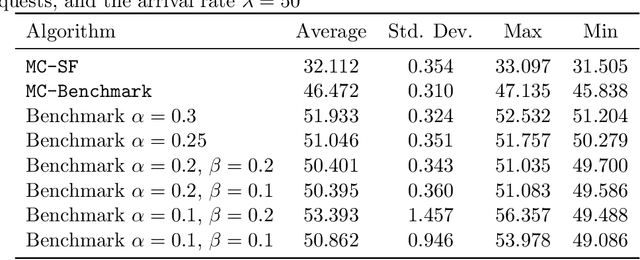
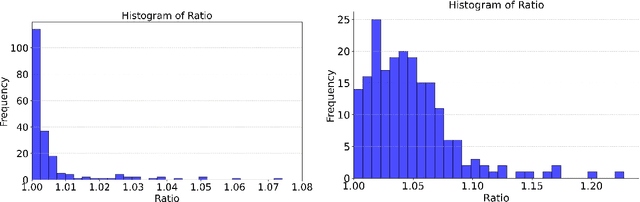
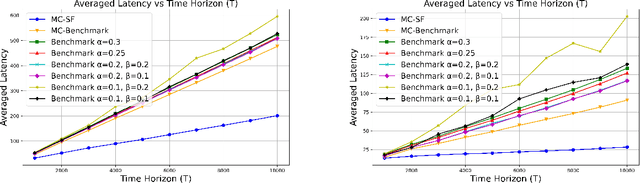
Large Language Model (LLM) inference, where a trained model generates text one word at a time in response to user prompts, is a computationally intensive process requiring efficient scheduling to optimize latency and resource utilization. A key challenge in LLM inference is the management of the Key-Value (KV) cache, which reduces redundant computations but introduces memory constraints. In this work, we model LLM inference with KV cache constraints theoretically and propose novel batching and scheduling algorithms that minimize inference latency while effectively managing the KV cache's memory. We analyze both semi-online and fully online scheduling models, and our results are threefold. First, we provide a polynomial-time algorithm that achieves exact optimality in terms of average latency in the semi-online prompt arrival model. Second, in the fully online case with a stochastic prompt arrival, we introduce an efficient online scheduling algorithm with constant regret. Third, we prove that no algorithm (deterministic or randomized) can achieve a constant competitive ratio in fully online adversarial settings. Our empirical evaluations on a public LLM inference dataset, using the Llama-70B model on A100 GPUs, show that our approach significantly outperforms benchmark algorithms used currently in practice, achieving lower latency while reducing energy consumption. Overall, our results offer a path toward more sustainable and cost-effective LLM deployment.