 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Inference for Matching Decisions via Matrix Completion under Dependent Missingness
Oct 30, 2025This paper studies decision-making and statistical inference for two-sided matching markets via matrix completion. In contrast to the independent sampling assumed in classical matrix completion literature, the observed entries, which arise from past matching data, are constrained by matching capacity. This matching-induced dependence poses new challenges for both estimation and inference in the matrix completion framework. We propose a non-convex algorithm based on Grassmannian gradient descent and establish near-optimal entrywise convergence rates for three canonical mechanisms, i.e., one-to-one matching, one-to-many matching with one-sided random arrival, and two-sided random arrival. To facilitate valid uncertainty quantification and hypothesis testing on matching decisions, we further develop a general debiasing and projection framework for arbitrary linear forms of the reward matrix, deriving asymptotic normality with finite-sample guarantees under matching-induced dependent sampling. Our empirical experiments demonstrate that the proposed approach provides accurate estimation, valid confidence intervals, and efficient evaluation of matching policies.
Regret Minimization and Statistical Inference in Online Decision Making with High-dimensional Covariates
Nov 10, 2024



This paper investigates regret minimization, statistical inference, and their interplay in high-dimensional online decision-making based on the sparse linear context bandit model. We integrate the $\varepsilon$-greedy bandit algorithm for decision-making with a hard thresholding algorithm for estimating sparse bandit parameters and introduce an inference framework based on a debiasing method using inverse propensity weighting. Under a margin condition, our method achieves either $O(T^{1/2})$ regret or classical $O(T^{1/2})$-consistent inference, indicating an unavoidable trade-off between exploration and exploitation. If a diverse covariate condition holds, we demonstrate that a pure-greedy bandit algorithm, i.e., exploration-free, combined with a debiased estimator based on average weighting can simultaneously achieve optimal $O(\log T)$ regret and $O(T^{1/2})$-consistent inference. We also show that a simple sample mean estimator can provide valid inference for the optimal policy's value. Numerical simulations and experiments on Warfarin dosing data validate the effectiveness of our methods.
Statistical Inference in Tensor Completion: Optimal Uncertainty Quantification and Statistical-Computational Gaps
Oct 15, 2024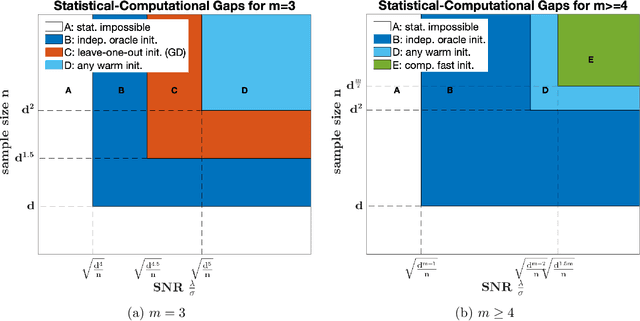


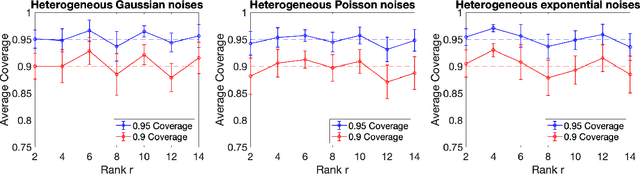
This paper presents a simple yet efficient method for statistical inference of tensor linear forms with incomplete and noisy observations. Under the Tucker low-rank tensor model, we utilize an appropriate initial estimate, along with a debiasing technique followed by a one-step power iteration, to construct an asymptotic normal test statistic. This method is suitable for various statistical inference tasks, including confidence interval prediction, inference under heteroskedastic and sub-exponential noises, and simultaneous testing. Furthermore, the approach reaches the Cram\'er-Rao lower bound for statistical estimation on Riemannian manifolds, indicating its optimality for uncertainty quantification. We comprehensively discusses the statistical-computational gaps and investigates the relationship between initialization and bias-correlation approaches. The findings demonstrate that with independent initialization, statistically optimal sample sizes and signal-to-noise ratios are sufficient for accurate inferences. Conversely, when initialization depends on the observations, computationally optimal sample sizes and signal-to-noise ratios also guarantee asymptotic normality without the need for data-splitting. The phase transition of computational and statistical limits is presented. Numerical simulations results conform to the theoretical discoveries.
Multiple Testing of Linear Forms for Noisy Matrix Completion
Dec 01, 2023



Many important tasks of large-scale recommender systems can be naturally cast as testing multiple linear forms for noisy matrix completion. These problems, however, present unique challenges because of the subtle bias-and-variance tradeoff of and an intricate dependence among the estimated entries induced by the low-rank structure. In this paper, we develop a general approach to overcome these difficulties by introducing new statistics for individual tests with sharp asymptotics both marginally and jointly, and utilizing them to control the false discovery rate (FDR) via a data splitting and symmetric aggregation scheme. We show that valid FDR control can be achieved with guaranteed power under nearly optimal sample size requirements using the proposed methodology. Extensive numerical simulations and real data examples are also presented to further illustrate its practical merits.
High-dimensional Linear Bandits with Knapsacks
Nov 02, 2023We study the contextual bandits with knapsack (CBwK) problem under the high-dimensional setting where the dimension of the feature is large. The reward of pulling each arm equals the multiplication of a sparse high-dimensional weight vector and the feature of the current arrival, with additional random noise. In this paper, we investigate how to exploit this sparsity structure to achieve improved regret for the CBwK problem. To this end, we first develop an online variant of the hard thresholding algorithm that performs the sparse estimation in an online manner. We further combine our online estimator with a primal-dual framework, where we assign a dual variable to each knapsack constraint and utilize an online learning algorithm to update the dual variable, thereby controlling the consumption of the knapsack capacity. We show that this integrated approach allows us to achieve a sublinear regret that depends logarithmically on the feature dimension, thus improving the polynomial dependency established in the previous literature. We also apply our framework to the high-dimension contextual bandit problem without the knapsack constraint and achieve optimal regret in both the data-poor regime and the data-rich regime. We finally conduct numerical experiments to show the efficient empirical performance of our algorithms under the high dimensional setting.