 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePure Exploration for a Good Policy in Reinforcement Learning with Bandit Feedback
May 22, 2026Pure exploration in episodic Reinforcement Learning has primarily focused on Best Policy Identification (BPI), which seeks to identify a (near)-optimal policy with high confidence. Motivated by practical settings where a ``good enough'' policy suffices, we study an alternate objective of Good Policy Identification (GPI). For a given reward threshold $μ_0$, GPI only requires identifying a policy with expected reward in an episode at least $μ_0$ if such a policy exists (positive instance), or declaring None if no such policy exists (negative instance). We formalize GPI under the fixed-confidence setting. We require the output to be correct with probability $\geq 1-δ$, and seek to minimize the expected sample complexity, which is the expected number of episodes explored for the output. We propose a novel algorithm BEE-GPI, and derive theoretically-grounded upper bounds on its sample complexity for positive and negative instances. Notably, for positive instances, the coefficient of $\log 1/δ$ in our upper bound is $O(H^2/(V^* - μ_0)^2)$, where $H$ is the episode length and $V^*$ is the optimal expected reward in an episode. The coefficient does not depend on the action and state space sizes otherwise, in sharp contrast to the sample complexity in BPI. We further establish lower bound results to show the near-optimality of BEE-GPI and the necessity of the $1/(V^* -μ)^2$ term. Numerical experiments further validate the efficiency of our approach.
Learning with a Budget: Identifying the Best Arm with Resource Constraints
Feb 27, 2026In many applications, evaluating the effectiveness of different alternatives comes with varying costs or resource usage. Motivated by such heterogeneity, we study the Best Arm Identification with Resource Constraints (BAIwRC) problem, where an agent seeks to identify the best alternative (aka arm) in the presence of resource constraints. Each arm pull consumes one or more types of limited resources. We make two key contributions. First, we propose the Successive Halving with Resource Rationing (SH-RR) algorithm, which integrates resource-aware allocation into the classical successive halving framework on best arm identification. The SH-RR algorithm unifies the theoretical analysis for both the stochastic and deterministic consumption settings, with a new \textit{effective consumption measure
Closing the Gap on the Sample Complexity of 1-Identification
Jan 22, 20261-identification is a fundamental multi-armed bandit formulation on pure exploration. An agent aims to determine whether there exists a qualified arm whose mean reward is not less than a known threshold $μ_0$, or to output \textsf{None} if it believes such an arm does not exist. The agent needs to guarantee its output is correct with probability at least $1-δ$, while making expected total pulling times $\mathbb{E}τ$ as small as possible. We work on 1-identification with two main contributions. (1) We utilize an optimization formulation to derive a new lower bound of $\mathbb{E}τ$, when there is at least one qualified arm. (2) We design a new algorithm, deriving tight upper bounds whose gap to lower bounds are up to a polynomial of logarithm factor across all problem instance. Our result complements the analysis of $\mathbb{E}τ$ when there are multiple qualified arms, which is an open problem left by history literature.
Episodic Contextual Bandits with Knapsacks under Conversion Models
Jul 09, 2025We study an online setting, where a decision maker (DM) interacts with contextual bandit-with-knapsack (BwK) instances in repeated episodes. These episodes start with different resource amounts, and the contexts' probability distributions are non-stationary in an episode. All episodes share the same latent conversion model, which governs the random outcome contingent upon a request's context and an allocation decision. Our model captures applications such as dynamic pricing on perishable resources with episodic replenishment, and first price auctions in repeated episodes with different starting budgets. We design an online algorithm that achieves a regret sub-linear in $T$, the number of episodes, assuming access to a \emph{confidence bound oracle} that achieves an $o(T)$-regret. Such an oracle is readily available from existing contextual bandit literature. We overcome the technical challenge with arbitrarily many possible contexts, which leads to a reinforcement learning problem with an unbounded state space. Our framework provides improved regret bounds in certain settings when the DM is provided with unlabeled feature data, which is novel to the contextual BwK literature.
Near Optimal Non-asymptotic Sample Complexity of 1-Identification
Jun 08, 2025Motivated by an open direction in existing literature, we study the 1-identification problem, a fundamental multi-armed bandit formulation on pure exploration. The goal is to determine whether there exists an arm whose mean reward is at least a known threshold $\mu_0$, or to output None if it believes such an arm does not exist. The agent needs to guarantee its output is correct with probability at least $1-\delta$. Degenne & Koolen 2019 has established the asymptotically tight sample complexity for the 1-identification problem, but they commented that the non-asymptotic analysis remains unclear. We design a new algorithm Sequential-Exploration-Exploitation (SEE), and conduct theoretical analysis from the non-asymptotic perspective. Novel to the literature, we achieve near optimality, in the sense of matching upper and lower bounds on the pulling complexity. The gap between the upper and lower bounds is up to a polynomial logarithmic factor. The numerical result also indicates the effectiveness of our algorithm, compared to existing benchmarks.
Best Arm Identification with Possibly Biased Offline Data
May 29, 2025We study the best arm identification (BAI) problem with potentially biased offline data in the fixed confidence setting, which commonly arises in real-world scenarios such as clinical trials. We prove an impossibility result for adaptive algorithms without prior knowledge of the bias bound between online and offline distributions. To address this, we propose the LUCB-H algorithm, which introduces adaptive confidence bounds by incorporating an auxiliary bias correction to balance offline and online data within the LUCB framework. Theoretical analysis shows that LUCB-H matches the sample complexity of standard LUCB when offline data is misleading and significantly outperforms it when offline data is helpful. We also derive an instance-dependent lower bound that matches the upper bound of LUCB-H in certain scenarios. Numerical experiments further demonstrate the robustness and adaptability of LUCB-H in effectively incorporating offline data.
Efficiently Solving Discounted MDPs with Predictions on Transition Matrices
Feb 21, 2025


We study infinite-horizon Discounted Markov Decision Processes (DMDPs) under a generative model. Motivated by the Algorithm with Advice framework Mitzenmacher and Vassilvitskii 2022, we propose a novel framework to investigate how a prediction on the transition matrix can enhance the sample efficiency in solving DMDPs and improve sample complexity bounds. We focus on the DMDPs with $N$ state-action pairs and discounted factor $\gamma$. Firstly, we provide an impossibility result that, without prior knowledge of the prediction accuracy, no sampling policy can compute an $\epsilon$-optimal policy with a sample complexity bound better than $\tilde{O}((1-\gamma)^{-3} N\epsilon^{-2})$, which matches the state-of-the-art minimax sample complexity bound with no prediction. In complement, we propose an algorithm based on minimax optimization techniques that leverages the prediction on the transition matrix. Our algorithm achieves a sample complexity bound depending on the prediction error, and the bound is uniformly better than $\tilde{O}((1-\gamma)^{-4} N \epsilon^{-2})$, the previous best result derived from convex optimization methods. These theoretical findings are further supported by our numerical experiments.
Leveraging (Biased) Information: Multi-armed Bandits with Offline Data
May 04, 2024We leverage offline data to facilitate online learning in stochastic multi-armed bandits. The probability distributions that govern the offline data and the online rewards can be different. Without any non-trivial upper bound on their difference, we show that no non-anticipatory policy can outperform the UCB policy by (Auer et al. 2002), even in the presence of offline data. In complement, we propose an online policy MIN-UCB, which outperforms UCB when a non-trivial upper bound is given. MIN-UCB adaptively chooses to utilize the offline data when they are deemed informative, and to ignore them otherwise. MIN-UCB is shown to be tight in terms of both instance independent and dependent regret bounds. Finally, we corroborate the theoretical results with numerical experiments.
Best Arm Identification with Resource Constraints
Feb 29, 2024


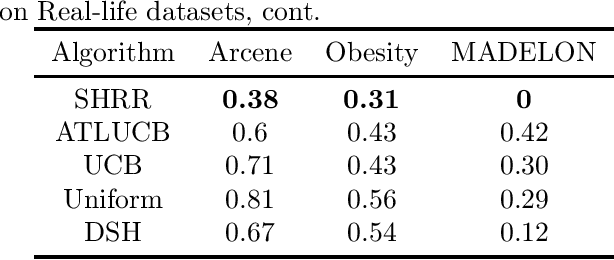
Motivated by the cost heterogeneity in experimentation across different alternatives, we study the Best Arm Identification with Resource Constraints (BAIwRC) problem. The agent aims to identify the best arm under resource constraints, where resources are consumed for each arm pull. We make two novel contributions. We design and analyze the Successive Halving with Resource Rationing algorithm (SH-RR). The SH-RR achieves a near-optimal non-asymptotic rate of convergence in terms of the probability of successively identifying an optimal arm. Interestingly, we identify a difference in convergence rates between the cases of deterministic and stochastic resource consumption.
Non-Stationary Bandits with Knapsack Problems with Advice
Feb 08, 2023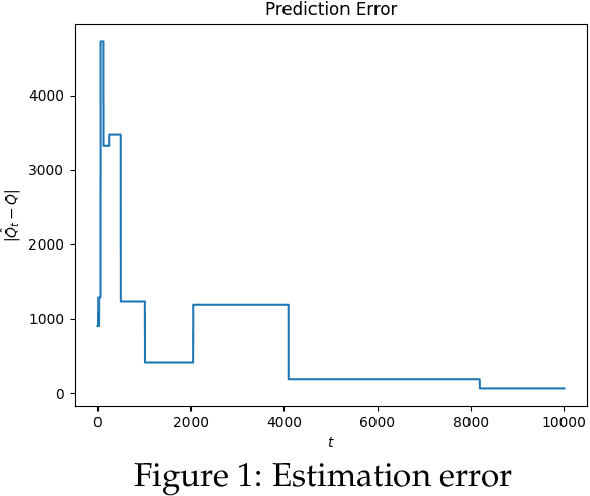
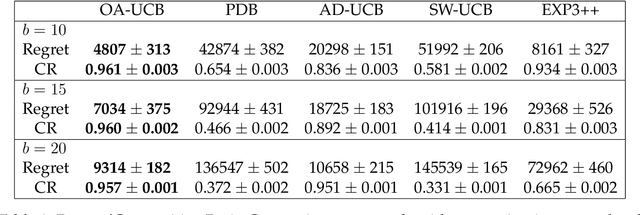
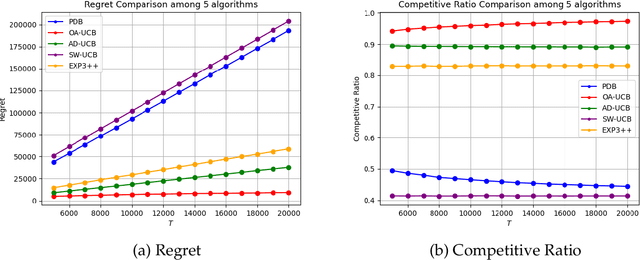
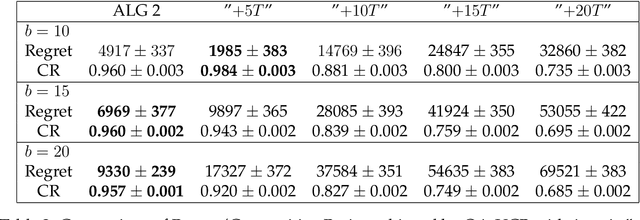
We consider a non-stationary Bandits with Knapsack problem. The outcome distribution at each time is scaled by a non-stationary quantity that signifies changing demand volumes. Instead of studying settings with limited non-stationarity, we investigate how online predictions on the total demand volume $Q$ allows us to improve our performance guarantees. We show that, without any prediction, any online algorithm incurs a linear-in-$T$ regret. In contrast, with online predictions on $Q$, we propose an online algorithm that judiciously incorporates the predictions, and achieve regret bounds that depends on the accuracy of the predictions. These bounds are shown to be tight in settings when prediction accuracy improves across time. Our theoretical results are corroborated by our numerical findings.