 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAS: Enhancing Reward-Cost Balance of Generative Model-assisted Offline Safe RL
Feb 05, 2026Offline Safe Reinforcement Learning (OSRL) aims to learn a policy to achieve high performance in sequential decision-making while satisfying constraints, using only pre-collected datasets. Recent works, inspired by the strong capabilities of Generative Models (GMs), reformulate decision-making in OSRL as a conditional generative process, where GMs generate desirable actions conditioned on predefined reward and cost values. However, GM-assisted methods face two major challenges in OSRL: (1) lacking the ability to "stitch" optimal transitions from suboptimal trajectories within the dataset, and (2) struggling to balance reward targets with cost targets, particularly when they are conflict. To address these issues, we propose Goal-Assisted Stitching (GAS), a novel algorithm designed to enhance stitching capabilities while effectively balancing reward maximization and constraint satisfaction. To enhance the stitching ability, GAS first augments and relabels the dataset at the transition level, enabling the construction of high-quality trajectories from suboptimal ones. GAS also introduces novel goal functions, which estimate the optimal achievable reward and cost goals from the dataset. These goal functions, trained using expectile regression on the relabeled and augmented dataset, allow GAS to accommodate a broader range of reward-cost return pairs and achieve a better tradeoff between reward maximization and constraint satisfaction compared to human-specified values. The estimated goals then guide policy training, ensuring robust performance under constrained settings. Furthermore, to improve training stability and efficiency, we reshape the dataset to achieve a more uniform reward-cost return distribution. Empirical results validate the effectiveness of GAS, demonstrating superior performance in balancing reward maximization and constraint satisfaction compared to existing methods.
SIT-Graph: State Integrated Tool Graph for Multi-Turn Agents
Dec 08, 2025Despite impressive advances in agent systems, multi-turn tool-use scenarios remain challenging. It is mainly because intent is clarified progressively and the environment evolves with each tool call. While reusing past experience is natural, current LLM agents either treat entire trajectories or pre-defined subtasks as indivisible units, or solely exploit tool-to-tool dependencies, hindering adaptation as states and information evolve across turns. In this paper, we propose a State Integrated Tool Graph (SIT-Graph), which enhances multi-turn tool use by exploiting partially overlapping experience. Inspired by human decision-making that integrates episodic and procedural memory, SIT-Graph captures both compact state representations (episodic-like fragments) and tool-to-tool dependencies (procedural-like routines) from historical trajectories. Specifically, we first build a tool graph from accumulated tool-use sequences, and then augment each edge with a compact state summary of the dialog and tool history that may shape the next action. At inference time, SIT-Graph enables a human-like balance between episodic recall and procedural execution: when the next decision requires recalling prior context, the agent retrieves the state summaries stored on relevant edges and uses them to guide its next action; when the step is routine, it follows high-confidence tool dependencies without explicit recall. Experiments across multiple stateful multi-turn tool-use benchmarks show that SIT-Graph consistently outperforms strong memory- and graph-based baselines, delivering more robust tool selection and more effective experience transfer.
Structure-Aware Automatic Channel Pruning by Searching with Graph Embedding
Jun 13, 2025Channel pruning is a powerful technique to reduce the computational overhead of deep neural networks, enabling efficient deployment on resource-constrained devices. However, existing pruning methods often rely on local heuristics or weight-based criteria that fail to capture global structural dependencies within the network, leading to suboptimal pruning decisions and degraded model performance. To address these limitations, we propose a novel structure-aware automatic channel pruning (SACP) framework that utilizes graph convolutional networks (GCNs) to model the network topology and learn the global importance of each channel. By encoding structural relationships within the network, our approach implements topology-aware pruning and this pruning is fully automated, reducing the need for human intervention. We restrict the pruning rate combinations to a specific space, where the number of combinations can be dynamically adjusted, and use a search-based approach to determine the optimal pruning rate combinations. Extensive experiments on benchmark datasets (CIFAR-10, ImageNet) with various models (ResNet, VGG16) demonstrate that SACP outperforms state-of-the-art pruning methods on compression efficiency and competitive on accuracy retention.
ECLAIR: Enhanced Clarification for Interactive Responses
Mar 19, 2025



We present ECLAIR (Enhanced CLArification for Interactive Responses), a novel unified and end-to-end framework for interactive disambiguation in enterprise AI assistants. ECLAIR generates clarification questions for ambiguous user queries and resolves ambiguity based on the user's response.We introduce a generalized architecture capable of integrating ambiguity information from multiple downstream agents, enhancing context-awareness in resolving ambiguities and allowing enterprise specific definition of agents. We further define agents within our system that provide domain-specific grounding information. We conduct experiments comparing ECLAIR to few-shot prompting techniques and demonstrate ECLAIR's superior performance in clarification question generation and ambiguity resolution.
TSDS: Data Selection for Task-Specific Model Finetuning
Oct 23, 2024



Finetuning foundation models for specific tasks is an emerging paradigm in modern machine learning. The efficacy of task-specific finetuning largely depends on the selection of appropriate training data. We present TSDS (Task-Specific Data Selection), a framework to select data for task-specific model finetuning, guided by a small but representative set of examples from the target task. To do so, we formulate data selection for task-specific finetuning as an optimization problem with a distribution alignment loss based on optimal transport to capture the discrepancy between the selected data and the target distribution. In addition, we add a regularizer to encourage the diversity of the selected data and incorporate kernel density estimation into the regularizer to reduce the negative effects of near-duplicates among the candidate data. We connect our optimization problem to nearest neighbor search and design efficient algorithms to compute the optimal solution based on approximate nearest neighbor search techniques. We evaluate our method on data selection for both continued pretraining and instruction tuning of language models. We show that instruction tuning using data selected by our method with a 1% selection ratio often outperforms using the full dataset and beats the baseline selection methods by 1.5 points in F1 score on average.
Data Selection for Task-Specific Model Finetuning
Oct 15, 2024Finetuning foundation models for specific tasks is an emerging paradigm in modern machine learning. The efficacy of task-specific finetuning largely depends on the selection of appropriate training data. We present a framework to select data for task-specific model finetuning, guided by a small but representative set of examples from the target task. To do so, we formulate data selection for task-specific finetuning as an optimization problem with a distribution alignment loss based on optimal transport to capture the discrepancy between the selected data and the target distribution. In addition, we add a regularizer to encourage the diversity of the selected data and incorporate kernel density estimation into the regularizer to reduce the negative effects of near-duplicates among the candidate data. We connect our optimization problem to nearest neighbor search and design efficient algorithms to compute the optimal solution based on approximate nearest neighbor search techniques. We evaluate our method on data selection for both continued pretraining and instruction tuning of language models. We show that instruction tuning using data selected by our method with a 1% selection ratio often outperforms using the full dataset and beats the baseline selection methods by 1.5 points in F1 score on average.
Reinforcement Learning with Intrinsically Motivated Feedback Graph for Lost-sales Inventory Control
Jun 26, 2024
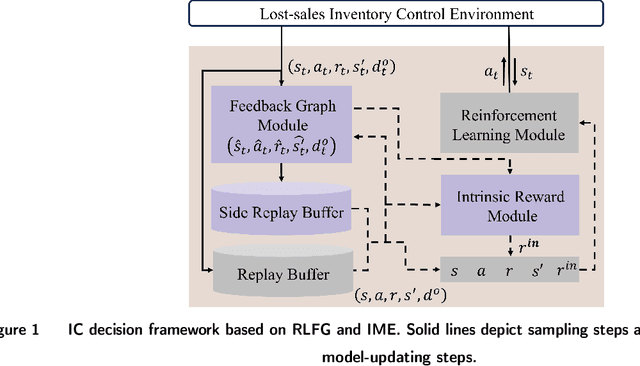

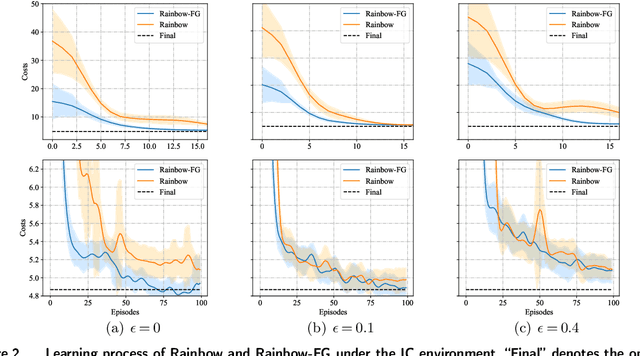
Reinforcement learning (RL) has proven to be well-performed and general-purpose in the inventory control (IC). However, further improvement of RL algorithms in the IC domain is impeded due to two limitations of online experience. First, online experience is expensive to acquire in real-world applications. With the low sample efficiency nature of RL algorithms, it would take extensive time to train the RL policy to convergence. Second, online experience may not reflect the true demand due to the lost sales phenomenon typical in IC, which makes the learning process more challenging. To address the above challenges, we propose a decision framework that combines reinforcement learning with feedback graph (RLFG) and intrinsically motivated exploration (IME) to boost sample efficiency. In particular, we first take advantage of the inherent properties of lost-sales IC problems and design the feedback graph (FG) specially for lost-sales IC problems to generate abundant side experiences aid RL updates. Then we conduct a rigorous theoretical analysis of how the designed FG reduces the sample complexity of RL methods. Based on the theoretical insights, we design an intrinsic reward to direct the RL agent to explore to the state-action space with more side experiences, further exploiting FG's power. Experimental results demonstrate that our method greatly improves the sample efficiency of applying RL in IC. Our code is available at https://anonymous.4open.science/r/RLIMFG4IC-811D/
Individual Contributions as Intrinsic Exploration Scaffolds for Multi-agent Reinforcement Learning
May 28, 2024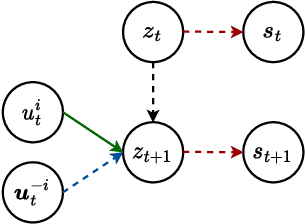

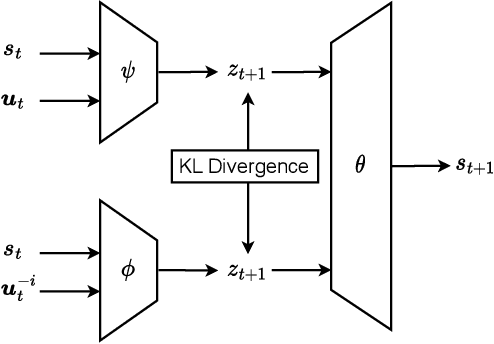

In multi-agent reinforcement learning (MARL), effective exploration is critical, especially in sparse reward environments. Although introducing global intrinsic rewards can foster exploration in such settings, it often complicates credit assignment among agents. To address this difficulty, we propose Individual Contributions as intrinsic Exploration Scaffolds (ICES), a novel approach to motivate exploration by assessing each agent's contribution from a global view. In particular, ICES constructs exploration scaffolds with Bayesian surprise, leveraging global transition information during centralized training. These scaffolds, used only in training, help to guide individual agents towards actions that significantly impact the global latent state transitions. Additionally, ICES separates exploration policies from exploitation policies, enabling the former to utilize privileged global information during training. Extensive experiments on cooperative benchmark tasks with sparse rewards, including Google Research Football (GRF) and StarCraft Multi-agent Challenge (SMAC), demonstrate that ICES exhibits superior exploration capabilities compared with baselines. The code is publicly available at https://github.com/LXXXXR/ICES.
AutoSlicer: Scalable Automated Data Slicing for ML Model Analysis
Dec 18, 2022Automated slicing aims to identify subsets of evaluation data where a trained model performs anomalously. This is an important problem for machine learning pipelines in production since it plays a key role in model debugging and comparison, as well as the diagnosis of fairness issues. Scalability has become a critical requirement for any automated slicing system due to the large search space of possible slices and the growing scale of data. We present Autoslicer, a scalable system that searches for problematic slices through distributed metric computation and hypothesis testing. We develop an efficient strategy that reduces the search space through pruning and prioritization. In the experiments, we show that our search strategy finds most of the anomalous slices by inspecting a small portion of the search space.
Picket: Self-supervised Data Diagnostics for ML Pipelines
Jun 08, 2020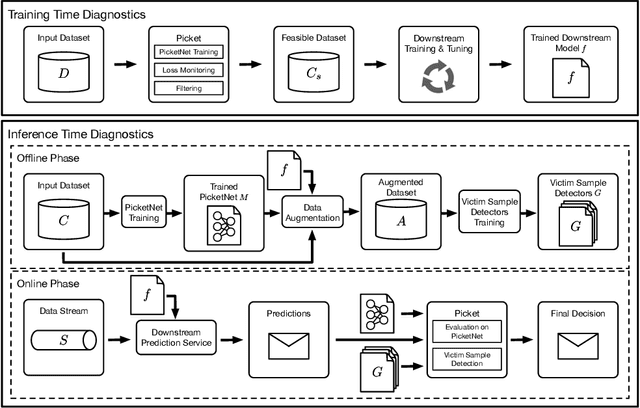
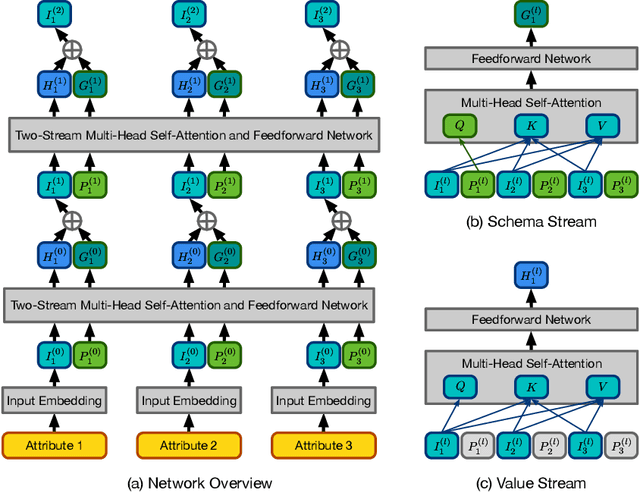
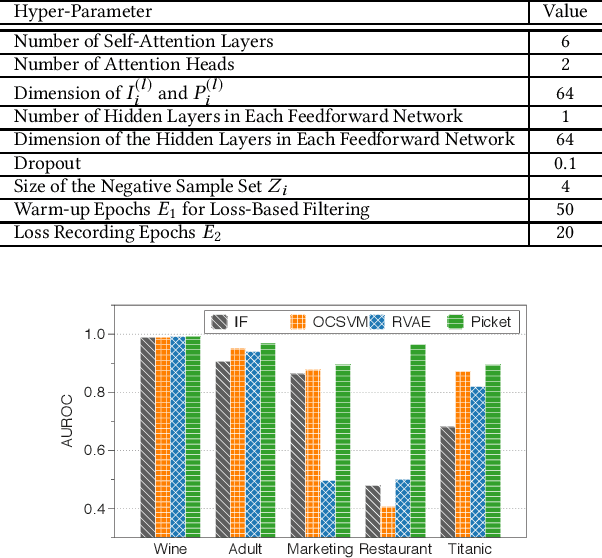
Data corruption is an impediment to modern machine learning deployments. Corrupted data can severely bias the learned model and can also lead to invalid inference. We present, Picket, a first-of-its-kind system that enables data diagnostics for machine learning pipelines over tabular data. Picket can safeguard against data corruptions that lead to degradation either during training or deployment. For the training stage, Picket identifies erroneous training examples that can result in a biased model, while for the deployment stage, Picket flags corrupted query points to a trained machine learning model that due to noise will result to incorrect predictions. Picket is built around a novel self-supervised deep learning model for mixed-type tabular data. Learning this model is fully unsupervised to minimize the burden of deployment, and Picket is designed as a plugin that can increase the robustness of any machine learning pipeline. We evaluate Picket on a diverse array of real-world data considering different corruption models that include systematic and adversarial noise. We show that Picket offers consistently accurate diagnostics during both training and deployment of various models ranging from SVMs to neural networks, beating competing methods of data quality validation in machine learning pipelines.