 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAR: Query-Guided Confidence-Aware Reranking for Retrieval-Augmented Generation
May 06, 2026Retrieval-Augmented Generation (RAG) depends on document ranking to provide useful evidence for generation, but conventional reranking methods mainly optimize query-document relevance rather than generation usefulness. A relevant document may still introduce noise, while a lower-ranked document may better reduce the generator's uncertainty. We propose CAR (Confidence-Aware Reranking), a query-guided, training-free, and plug-and-play reranking framework that uses generator confidence change as a document usefulness signal. CAR estimates confidence through the semantic consistency of multiple sampled answers under query-only and query-document conditions. Documents that significantly increase confidence are promoted, those that decrease confidence are demoted, and uncertain cases preserve the baseline order, while a query-level gate avoids unnecessary intervention on already confident queries. Experiments on four BEIR datasets show that CAR consistently improves NDCG@5 across sparse and dense retrievers, LLM-based and supervised rerankers, and four LLM backbones. Notably, CAR improves the YesNo reranker by 25.4 percent on average under Contriever retrieval, and its ranking gains strongly correlate with downstream generation F1 improvements, achieving Spearman rho = 0.964.
LLM-Confidence Reranker: A Training-Free Approach for Enhancing Retrieval-Augmented Generation Systems
Feb 14, 2026Large language models (LLMs) have revolutionized natural language processing, yet hallucinations in knowledge-intensive tasks remain a critical challenge. Retrieval-augmented generation (RAG) addresses this by integrating external knowledge, but its efficacy depends on accurate document retrieval and ranking. Although existing rerankers demonstrate effectiveness, they frequently necessitate specialized training, impose substantial computational expenses, and fail to fully exploit the semantic capabilities of LLMs, particularly their inherent confidence signals. We propose the LLM-Confidence Reranker (LCR), a training-free, plug-and-play algorithm that enhances reranking in RAG systems by leveraging black-box LLM confidence derived from Maximum Semantic Cluster Proportion (MSCP). LCR employs a two-stage process: confidence assessment via multinomial sampling and clustering, followed by binning and multi-level sorting based on query and document confidence thresholds. This approach prioritizes relevant documents while preserving original rankings for high-confidence queries, ensuring robustness. Evaluated on BEIR and TREC benchmarks with BM25 and Contriever retrievers, LCR--using only 7--9B-parameter pre-trained LLMs--consistently improves NDCG@5 by up to 20.6% across pre-trained LLM and fine-tuned Transformer rerankers, without degradation. Ablation studies validate the hypothesis that LLM confidence positively correlates with document relevance, elucidating LCR's mechanism. LCR offers computational efficiency, parallelism for scalability, and broad compatibility, mitigating hallucinations in applications like medical diagnosis.
* Published by ESWA
Less is More for RAG: Information Gain Pruning for Generator-Aligned Reranking and Evidence Selection
Jan 24, 2026Retrieval-augmented generation (RAG) grounds large language models with external evidence, but under a limited context budget, the key challenge is deciding which retrieved passages should be injected. We show that retrieval relevance metrics (e.g., NDCG) correlate weakly with end-to-end QA quality and can even become negatively correlated under multi-passage injection, where redundancy and mild conflicts destabilize generation. We propose \textbf{Information Gain Pruning (IGP)}, a deployment-friendly reranking-and-pruning module that selects evidence using a generator-aligned utility signal and filters weak or harmful passages before truncation, without changing existing budget interfaces. Across five open-domain QA benchmarks and multiple retrievers and generators, IGP consistently improves the quality--cost trade-off. In a representative multi-evidence setting, IGP delivers about +12--20% relative improvement in average F1 while reducing final-stage input tokens by roughly 76--79% compared to retriever-only baselines.
Structure-Aware Automatic Channel Pruning by Searching with Graph Embedding
Jun 13, 2025Channel pruning is a powerful technique to reduce the computational overhead of deep neural networks, enabling efficient deployment on resource-constrained devices. However, existing pruning methods often rely on local heuristics or weight-based criteria that fail to capture global structural dependencies within the network, leading to suboptimal pruning decisions and degraded model performance. To address these limitations, we propose a novel structure-aware automatic channel pruning (SACP) framework that utilizes graph convolutional networks (GCNs) to model the network topology and learn the global importance of each channel. By encoding structural relationships within the network, our approach implements topology-aware pruning and this pruning is fully automated, reducing the need for human intervention. We restrict the pruning rate combinations to a specific space, where the number of combinations can be dynamically adjusted, and use a search-based approach to determine the optimal pruning rate combinations. Extensive experiments on benchmark datasets (CIFAR-10, ImageNet) with various models (ResNet, VGG16) demonstrate that SACP outperforms state-of-the-art pruning methods on compression efficiency and competitive on accuracy retention.
KGTrust: Evaluating Trustworthiness of SIoT via Knowledge Enhanced Graph Neural Networks
Feb 22, 2023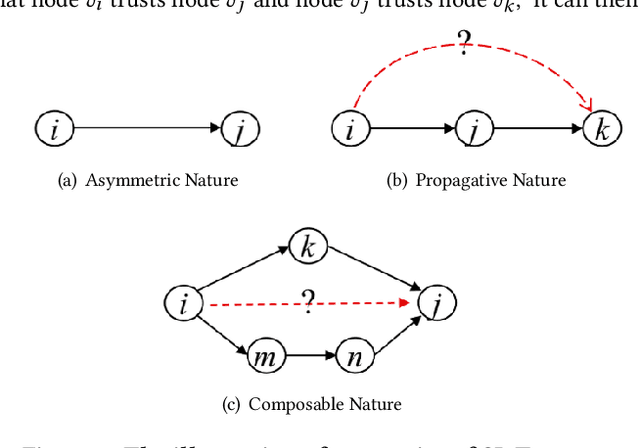
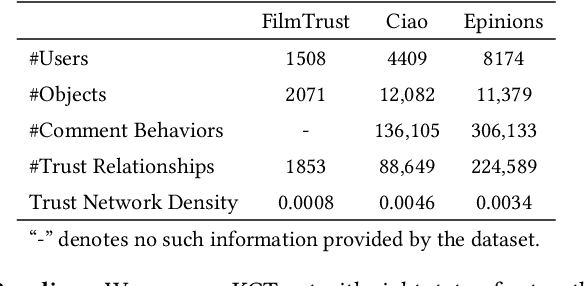
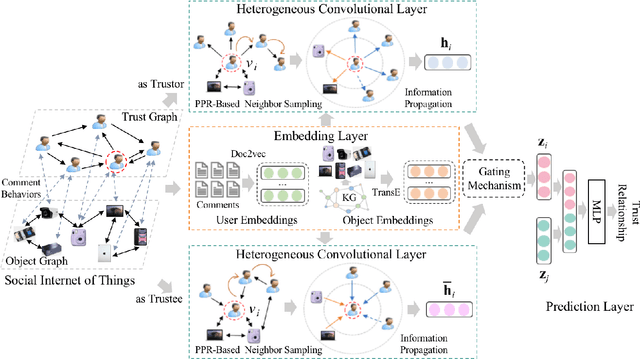
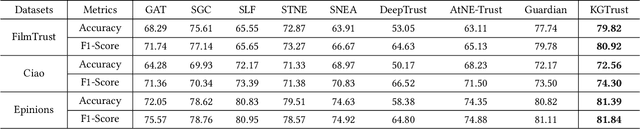
Social Internet of Things (SIoT), a promising and emerging paradigm that injects the notion of social networking into smart objects (i.e., things), paving the way for the next generation of Internet of Things. However, due to the risks and uncertainty, a crucial and urgent problem to be settled is establishing reliable relationships within SIoT, that is, trust evaluation. Graph neural networks for trust evaluation typically adopt a straightforward way such as one-hot or node2vec to comprehend node characteristics, which ignores the valuable semantic knowledge attached to nodes. Moreover, the underlying structure of SIoT is usually complex, including both the heterogeneous graph structure and pairwise trust relationships, which renders hard to preserve the properties of SIoT trust during information propagation. To address these aforementioned problems, we propose a novel knowledge-enhanced graph neural network (KGTrust) for better trust evaluation in SIoT. Specifically, we first extract useful knowledge from users' comment behaviors and external structured triples related to object descriptions, in order to gain a deeper insight into the semantics of users and objects. Furthermore, we introduce a discriminative convolutional layer that utilizes heterogeneous graph structure, node semantics, and augmented trust relationships to learn node embeddings from the perspective of a user as a trustor or a trustee, effectively capturing multi-aspect properties of SIoT trust during information propagation. Finally, a trust prediction layer is developed to estimate the trust relationships between pairwise nodes. Extensive experiments on three public datasets illustrate the superior performance of KGTrust over state-of-the-art methods.
One-shot Network Pruning at Initialization with Discriminative Image Patches
Sep 13, 2022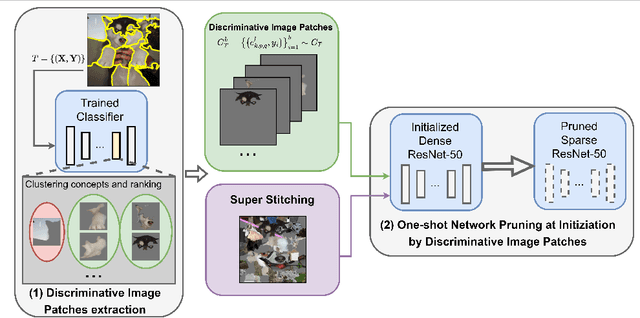
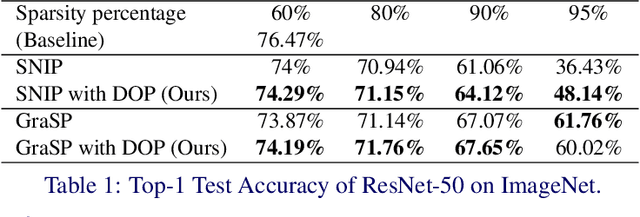


One-shot Network Pruning at Initialization (OPaI) is an effective method to decrease network pruning costs. Recently, there is a growing belief that data is unnecessary in OPaI. However, we obtain an opposite conclusion by ablation experiments in two representative OPaI methods, SNIP and GraSP. Specifically, we find that informative data is crucial to enhancing pruning performance. In this paper, we propose two novel methods, Discriminative One-shot Network Pruning (DOP) and Super Stitching, to prune the network by high-level visual discriminative image patches. Our contributions are as follows. (1) Extensive experiments reveal that OPaI is data-dependent. (2) Super Stitching performs significantly better than the original OPaI method on benchmark ImageNet, especially in a highly compressed model.
NodeTrans: A Graph Transfer Learning Approach for Traffic Prediction
Jul 04, 2022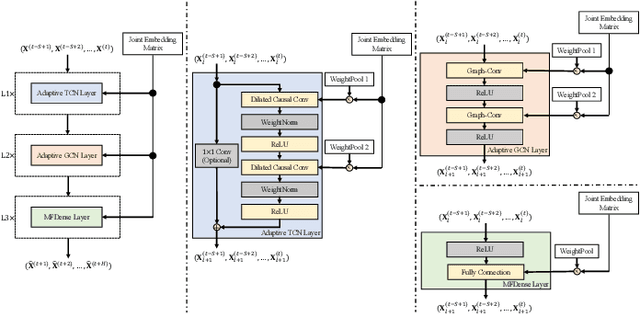
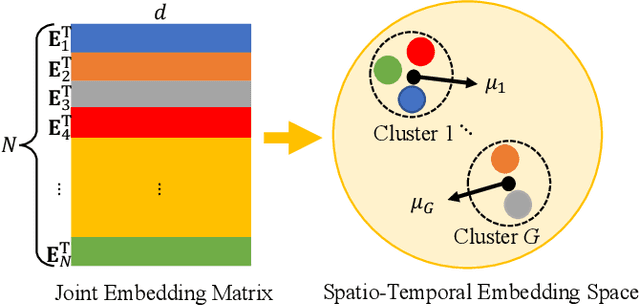
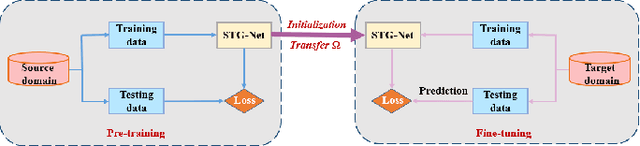
Recently, deep learning methods have made great progress in traffic prediction, but their performance depends on a large amount of historical data. In reality, we may face the data scarcity issue. In this case, deep learning models fail to obtain satisfactory performance. Transfer learning is a promising approach to solve the data scarcity issue. However, existing transfer learning approaches in traffic prediction are mainly based on regular grid data, which is not suitable for the inherent graph data in the traffic network. Moreover, existing graph-based models can only capture shared traffic patterns in the road network, and how to learn node-specific patterns is also a challenge. In this paper, we propose a novel transfer learning approach to solve the traffic prediction with few data, which can transfer the knowledge learned from a data-rich source domain to a data-scarce target domain. First, a spatial-temporal graph neural network is proposed, which can capture the node-specific spatial-temporal traffic patterns of different road networks. Then, to improve the robustness of transfer, we design a pattern-based transfer strategy, where we leverage a clustering-based mechanism to distill common spatial-temporal patterns in the source domain, and use these knowledge to further improve the prediction performance of the target domain. Experiments on real-world datasets verify the effectiveness of our approach.
Soft-mask: Adaptive Substructure Extractions for Graph Neural Networks
Jun 11, 2022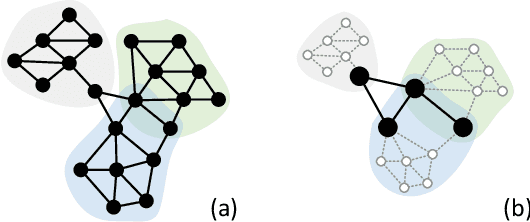
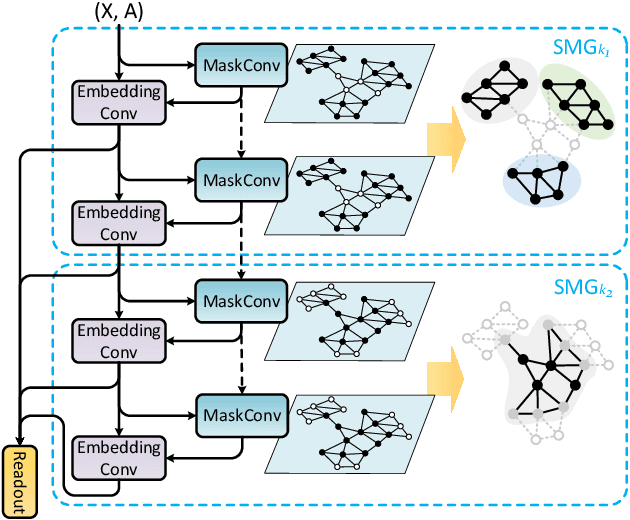

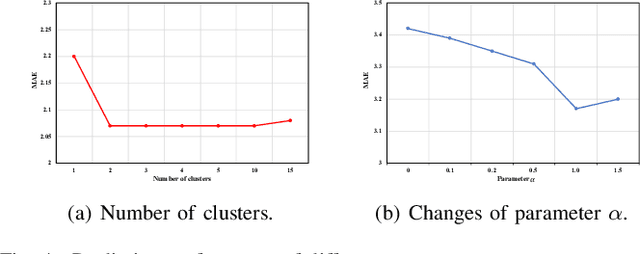
For learning graph representations, not all detailed structures within a graph are relevant to the given graph tasks. Task-relevant structures can be $localized$ or $sparse$ which are only involved in subgraphs or characterized by the interactions of subgraphs (a hierarchical perspective). A graph neural network should be able to efficiently extract task-relevant structures and be invariant to irrelevant parts, which is challenging for general message passing GNNs. In this work, we propose to learn graph representations from a sequence of subgraphs of the original graph to better capture task-relevant substructures or hierarchical structures and skip $noisy$ parts. To this end, we design soft-mask GNN layer to extract desired subgraphs through the mask mechanism. The soft-mask is defined in a continuous space to maintain the differentiability and characterize the weights of different parts. Compared with existing subgraph or hierarchical representation learning methods and graph pooling operations, the soft-mask GNN layer is not limited by the fixed sample or drop ratio, and therefore is more flexible to extract subgraphs with arbitrary sizes. Extensive experiments on public graph benchmarks show that soft-mask mechanism brings performance improvements. And it also provides interpretability where visualizing the values of masks in each layer allows us to have an insight into the structures learned by the model.
Improving Spectral Graph Convolution for Learning Graph-level Representation
Dec 14, 2021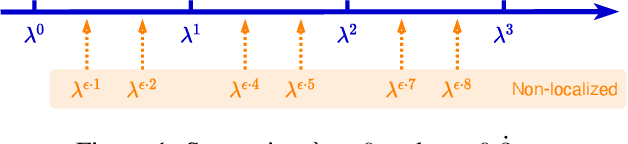
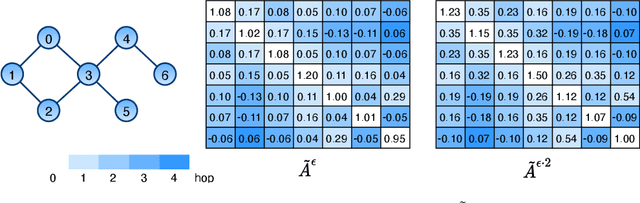
From the original theoretically well-defined spectral graph convolution to the subsequent spatial bassed message-passing model, spatial locality (in vertex domain) acts as a fundamental principle of most graph neural networks (GNNs). In the spectral graph convolution, the filter is approximated by polynomials, where a $k$-order polynomial covers $k$-hop neighbors. In the message-passing, various definitions of neighbors used in aggregations are actually an extensive exploration of the spatial locality information. For learning node representations, the topological distance seems necessary since it characterizes the basic relations between nodes. However, for learning representations of the entire graphs, is it still necessary to hold? In this work, we show that such a principle is not necessary, it hinders most existing GNNs from efficiently encoding graph structures. By removing it, as well as the limitation of polynomial filters, the resulting new architecture significantly boosts performance on learning graph representations. We also study the effects of graph spectrum on signals and interpret various existing improvements as different spectrum smoothing techniques. It serves as a spatial understanding that quantitatively measures the effects of the spectrum to input signals in comparison to the well-known spectral understanding as high/low-pass filters. More importantly, it sheds the light on developing powerful graph representation models.
Federated Unlearning via Class-Discriminative Pruning
Oct 22, 2021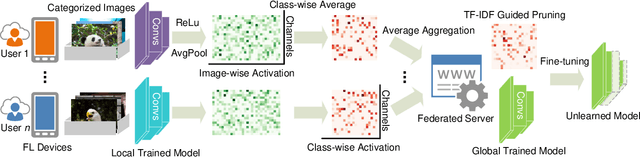



We explore the problem of selectively forgetting categories from trained CNN classification models in the federated learning (FL). Given that the data used for training cannot be accessed globally in FL, our insights probe deep into the internal influence of each channel. Through the visualization of feature maps activated by different channels, we observe that different channels have a varying contribution to different categories in image classification. Inspired by this, we propose a method for scrubbing the model clean of information about particular categories. The method does not require retraining from scratch, nor global access to the data used for training. Instead, we introduce the concept of Term Frequency Inverse Document Frequency (TF-IDF) to quantize the class discrimination of channels. Channels with high TF-IDF scores have more discrimination on the target categories and thus need to be pruned to unlearn. The channel pruning is followed by a fine-tuning process to recover the performance of the pruned model. Evaluated on CIFAR10 dataset, our method accelerates the speed of unlearning by 8.9x for the ResNet model, and 7.9x for the VGG model under no degradation in accuracy, compared to retraining from scratch. For CIFAR100 dataset, the speedups are 9.9x and 8.4x, respectively. We envision this work as a complementary block for FL towards compliance with legal and ethical criteria.