 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid second-order gradient histogram based global low-rank sparse regression for robust face recognition
Nov 15, 2025Low-rank sparse regression models have been widely adopted in face recognition due to their robustness against occlusion and illumination variations. However, existing methods often suffer from insufficient feature representation and limited modeling of structured corruption across samples. To address these issues, this paper proposes a Hybrid second-order gradient Histogram based Global Low-Rank Sparse Regression (H2H-GLRSR) model. First, we propose the Histogram of Oriented Hessian (HOH) to capture second-order geometric characteristics such as curvature and ridge patterns. By fusing HOH and first-order gradient histograms, we construct a unified local descriptor, termed the Hybrid second-order gradient Histogram (H2H), which enhances structural discriminability under challenging conditions. Subsequently, the H2H features are incorporated into an extended version of the Sparse Regularized Nuclear Norm based Matrix Regression (SR\_NMR) model, where a global low-rank constraint is imposed on the residual matrix to exploit cross-sample correlations in structured noise. The resulting H2H-GLRSR model achieves superior discrimination and robustness. Experimental results on benchmark datasets demonstrate that the proposed method significantly outperforms state-of-the-art regression-based classifiers in both recognition accuracy and computational efficiency.
SynerMix: Synergistic Mixup Solution for Enhanced Intra-Class Cohesion and Inter-Class Separability in Image Classification
Mar 24, 2024



To address the issues of MixUp and its variants (e.g., Manifold MixUp) in image classification tasks-namely, their neglect of mixing within the same class (intra-class mixup) and their inadequacy in enhancing intra-class cohesion through their mixing operations-we propose a novel mixup method named SynerMix-Intra and, building upon this, introduce a synergistic mixup solution named SynerMix. SynerMix-Intra specifically targets intra-class mixup to bolster intra-class cohesion, a feature not addressed by current mixup methods. For each mini-batch, it leverages feature representations of unaugmented original images from each class to generate a synthesized feature representation through random linear interpolation. All synthesized representations are then fed into the classification and loss layers to calculate an average classification loss that significantly enhances intra-class cohesion. Furthermore, SynerMix combines SynerMix-Intra with an existing mixup approach (e.g., MixUp, Manifold MixUp), which primarily focuses on inter-class mixup and has the benefit of enhancing inter-class separability. In doing so, it integrates both inter- and intra-class mixup in a balanced way while concurrently improving intra-class cohesion and inter-class separability. Experimental results on six datasets show that SynerMix achieves a 0.1% to 3.43% higher accuracy than the best of either MixUp or SynerMix-Intra alone, averaging a 1.16% gain. It also surpasses the top-performer of either Manifold MixUp or SynerMix-Intra by 0.12% to 5.16%, with an average gain of 1.11%. Given that SynerMix is model-agnostic, it holds significant potential for application in other domains where mixup methods have shown promise, such as speech and text classification. Our code is publicly available at: https://github.com/wxitxy/synermix.git.
Adaptive Fusion of Radiomics and Deep Features for Lung Adenocarcinoma Subtype Recognition
Aug 27, 2023The most common type of lung cancer, lung adenocarcinoma (LUAD), has been increasingly detected since the advent of low-dose computed tomography screening technology. In clinical practice, pre-invasive LUAD (Pre-IAs) should only require regular follow-up care, while invasive LUAD (IAs) should receive immediate treatment with appropriate lung cancer resection, based on the cancer subtype. However, prior research on diagnosing LUAD has mainly focused on classifying Pre-IAs/IAs, as techniques for distinguishing different subtypes of IAs have been lacking. In this study, we proposed a multi-head attentional feature fusion (MHA-FF) model for not only distinguishing IAs from Pre-IAs, but also for distinguishing the different subtypes of IAs. To predict the subtype of each nodule accurately, we leveraged both radiomics and deep features extracted from computed tomography images. Furthermore, those features were aggregated through an adaptive fusion module that can learn attention-based discriminative features. The utility of our proposed method is demonstrated here by means of real-world data collected from a multi-center cohort.
High-risk Factor Prediction in Lung Cancer Using Thin CT Scans: An Attention-Enhanced Graph Convolutional Network Approach
Aug 27, 2023



Lung cancer, particularly in its advanced stages, remains a leading cause of death globally. Though early detection via low-dose computed tomography (CT) is promising, the identification of high-risk factors crucial for surgical mode selection remains a challenge. Addressing this, our study introduces an Attention-Enhanced Graph Convolutional Network (AE-GCN) model to classify whether there are high-risk factors in stage I lung cancer based on the preoperative CT images. This will aid surgeons in determining the optimal surgical method before the operation. Unlike previous studies that relied on 3D patch techniques to represent nodule spatial features, our method employs a GCN model to capture the spatial characteristics of pulmonary nodules. Specifically, we regard each slice of the nodule as a graph vertex, and the inherent spatial relationships between slices form the edges. Then, to enhance the expression of nodule features, we integrated both channel and spatial attention mechanisms with a pre-trained VGG model for adaptive feature extraction from pulmonary nodules. Lastly, the effectiveness of the proposed method is demonstrated using real-world data collected from the hospitals, thereby emphasizing its potential utility in the clinical practice.
One-shot Network Pruning at Initialization with Discriminative Image Patches
Sep 13, 2022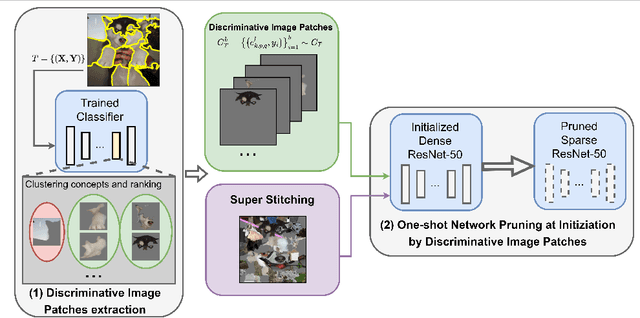
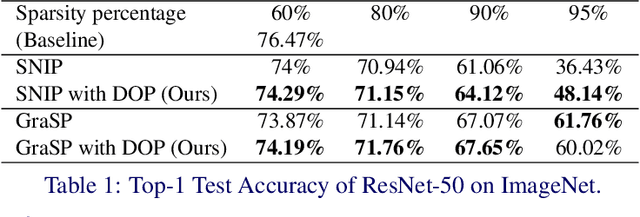


One-shot Network Pruning at Initialization (OPaI) is an effective method to decrease network pruning costs. Recently, there is a growing belief that data is unnecessary in OPaI. However, we obtain an opposite conclusion by ablation experiments in two representative OPaI methods, SNIP and GraSP. Specifically, we find that informative data is crucial to enhancing pruning performance. In this paper, we propose two novel methods, Discriminative One-shot Network Pruning (DOP) and Super Stitching, to prune the network by high-level visual discriminative image patches. Our contributions are as follows. (1) Extensive experiments reveal that OPaI is data-dependent. (2) Super Stitching performs significantly better than the original OPaI method on benchmark ImageNet, especially in a highly compressed model.
Spatial-temporal Concept based Explanation of 3D ConvNets
Jun 09, 2022
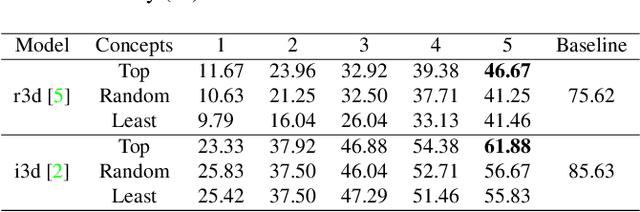
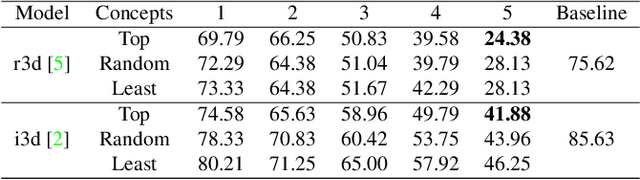
Recent studies have achieved outstanding success in explaining 2D image recognition ConvNets. On the other hand, due to the computation cost and complexity of video data, the explanation of 3D video recognition ConvNets is relatively less studied. In this paper, we present a 3D ACE (Automatic Concept-based Explanation) framework for interpreting 3D ConvNets. In our approach: (1) videos are represented using high-level supervoxels, which is straightforward for human to understand; and (2) the interpreting framework estimates a score for each voxel, which reflects its importance in the decision procedure. Experiments show that our method can discover spatial-temporal concepts of different importance-levels, and thus can explore the influence of the concepts on a target task, such as action classification, in-depth. The codes are publicly available.