 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Extremely Lightweight Distracted Driver Recognition With Distillation-Based Neural Architecture Search and Knowledge Transfer
Feb 09, 2023The number of traffic accidents has been continuously increasing in recent years worldwide. Many accidents are caused by distracted drivers, who take their attention away from driving. Motivated by the success of Convolutional Neural Networks (CNNs) in computer vision, many researchers developed CNN-based algorithms to recognize distracted driving from a dashcam and warn the driver against unsafe behaviors. However, current models have too many parameters, which is unfeasible for vehicle-mounted computing. This work proposes a novel knowledge-distillation-based framework to solve this problem. The proposed framework first constructs a high-performance teacher network by progressively strengthening the robustness to illumination changes from shallow to deep layers of a CNN. Then, the teacher network is used to guide the architecture searching process of a student network through knowledge distillation. After that, we use the teacher network again to transfer knowledge to the student network by knowledge distillation. Experimental results on the Statefarm Distracted Driver Detection Dataset and AUC Distracted Driver Dataset show that the proposed approach is highly effective for recognizing distracted driving behaviors from photos: (1) the teacher network's accuracy surpasses the previous best accuracy; (2) the student network achieves very high accuracy with only 0.42M parameters (around 55% of the previous most lightweight model). Furthermore, the student network architecture can be extended to a spatial-temporal 3D CNN for recognizing distracted driving from video clips. The 3D student network largely surpasses the previous best accuracy with only 2.03M parameters on the Drive&Act Dataset. The source code is available at https://github.com/Dichao-Liu/Lightweight_Distracted_Driver_Recognition_with_Distillation-Based_NAS_and_Knowledge_Transfer.
One-shot Network Pruning at Initialization with Discriminative Image Patches
Sep 13, 2022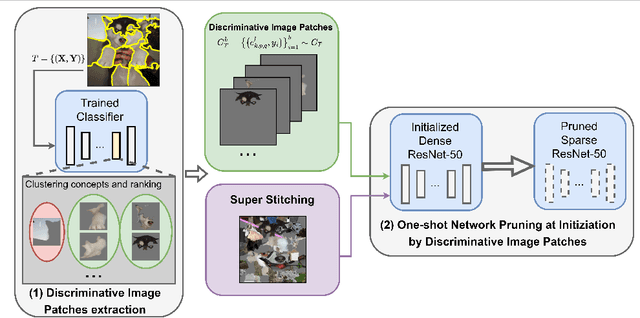
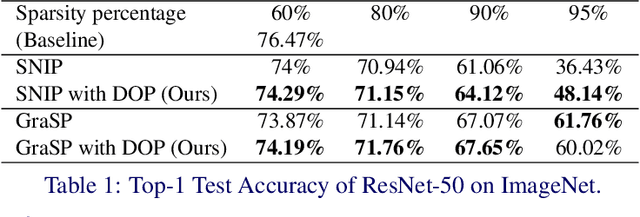


One-shot Network Pruning at Initialization (OPaI) is an effective method to decrease network pruning costs. Recently, there is a growing belief that data is unnecessary in OPaI. However, we obtain an opposite conclusion by ablation experiments in two representative OPaI methods, SNIP and GraSP. Specifically, we find that informative data is crucial to enhancing pruning performance. In this paper, we propose two novel methods, Discriminative One-shot Network Pruning (DOP) and Super Stitching, to prune the network by high-level visual discriminative image patches. Our contributions are as follows. (1) Extensive experiments reveal that OPaI is data-dependent. (2) Super Stitching performs significantly better than the original OPaI method on benchmark ImageNet, especially in a highly compressed model.
Spatial-temporal Concept based Explanation of 3D ConvNets
Jun 09, 2022
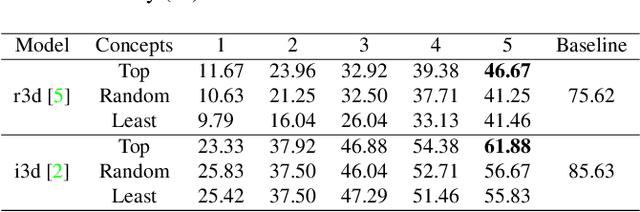
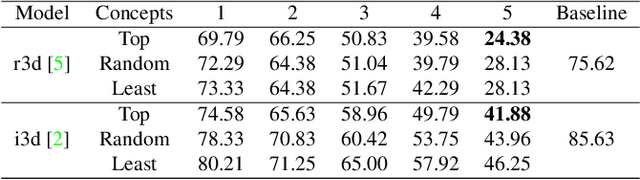
Recent studies have achieved outstanding success in explaining 2D image recognition ConvNets. On the other hand, due to the computation cost and complexity of video data, the explanation of 3D video recognition ConvNets is relatively less studied. In this paper, we present a 3D ACE (Automatic Concept-based Explanation) framework for interpreting 3D ConvNets. In our approach: (1) videos are represented using high-level supervoxels, which is straightforward for human to understand; and (2) the interpreting framework estimates a score for each voxel, which reflects its importance in the decision procedure. Experiments show that our method can discover spatial-temporal concepts of different importance-levels, and thus can explore the influence of the concepts on a target task, such as action classification, in-depth. The codes are publicly available.