 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Device Crack Segmentation for Edge Structural Health Monitoring
May 12, 2025Crack segmentation can play a critical role in Structural Health Monitoring (SHM) by enabling accurate identification of crack size and location, which allows to monitor structural damages over time. However, deploying deep learning models for crack segmentation on resource-constrained microcontrollers presents significant challenges due to limited memory, computational power, and energy resources. To address these challenges, this study explores lightweight U-Net architectures tailored for TinyML applications, focusing on three optimization strategies: filter number reduction, network depth reduction, and the use of Depthwise Separable Convolutions (DWConv2D). Our results demonstrate that reducing convolution kernels and network depth significantly reduces RAM and Flash requirement, and inference times, albeit with some accuracy trade-offs. Specifically, by reducing the filer number to 25%, the network depth to four blocks, and utilizing depthwise convolutions, a good compromise between segmentation performance and resource consumption is achieved. This makes the network particularly suitable for low-power TinyML applications. This study not only advances TinyML-based crack segmentation but also provides the possibility for energy-autonomous edge SHM systems.
SynerMix: Synergistic Mixup Solution for Enhanced Intra-Class Cohesion and Inter-Class Separability in Image Classification
Mar 24, 2024



To address the issues of MixUp and its variants (e.g., Manifold MixUp) in image classification tasks-namely, their neglect of mixing within the same class (intra-class mixup) and their inadequacy in enhancing intra-class cohesion through their mixing operations-we propose a novel mixup method named SynerMix-Intra and, building upon this, introduce a synergistic mixup solution named SynerMix. SynerMix-Intra specifically targets intra-class mixup to bolster intra-class cohesion, a feature not addressed by current mixup methods. For each mini-batch, it leverages feature representations of unaugmented original images from each class to generate a synthesized feature representation through random linear interpolation. All synthesized representations are then fed into the classification and loss layers to calculate an average classification loss that significantly enhances intra-class cohesion. Furthermore, SynerMix combines SynerMix-Intra with an existing mixup approach (e.g., MixUp, Manifold MixUp), which primarily focuses on inter-class mixup and has the benefit of enhancing inter-class separability. In doing so, it integrates both inter- and intra-class mixup in a balanced way while concurrently improving intra-class cohesion and inter-class separability. Experimental results on six datasets show that SynerMix achieves a 0.1% to 3.43% higher accuracy than the best of either MixUp or SynerMix-Intra alone, averaging a 1.16% gain. It also surpasses the top-performer of either Manifold MixUp or SynerMix-Intra by 0.12% to 5.16%, with an average gain of 1.11%. Given that SynerMix is model-agnostic, it holds significant potential for application in other domains where mixup methods have shown promise, such as speech and text classification. Our code is publicly available at: https://github.com/wxitxy/synermix.git.
Inferring gender from name: a large scale performance evaluation study
Aug 22, 2023A person's gender is a crucial piece of information when performing research across a wide range of scientific disciplines, such as medicine, sociology, political science, and economics, to name a few. However, in increasing instances, especially given the proliferation of big data, gender information is not readily available. In such cases researchers need to infer gender from readily available information, primarily from persons' names. While inferring gender from name may raise some ethical questions, the lack of viable alternatives means that researchers have to resort to such approaches when the goal justifies the means - in the majority of such studies the goal is to examine patterns and determinants of gender disparities. The necessity of name-to-gender inference has generated an ever-growing domain of algorithmic approaches and software products. These approaches have been used throughout the world in academia, industry, governmental and non-governmental organizations. Nevertheless, the existing approaches have yet to be systematically evaluated and compared, making it challenging to determine the optimal approach for future research. In this work, we conducted a large scale performance evaluation of existing approaches for name-to-gender inference. Analysis are performed using a variety of large annotated datasets of names. We further propose two new hybrid approaches that achieve better performance than any single existing approach.
Providing Actionable Feedback in Hiring Marketplaces using Generative Adversarial Networks
Oct 06, 2020

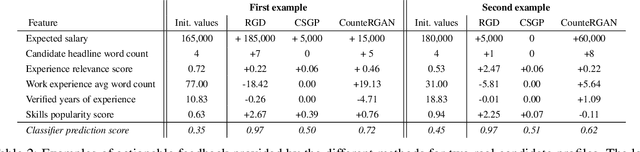
Machine learning predictors have been increasingly applied in production settings, including in one of the world's largest hiring platforms, Hired, to provide a better candidate and recruiter experience. The ability to provide actionable feedback is desirable for candidates to improve their chances of achieving success in the marketplace. Until recently, however, methods aimed at providing actionable feedback have been limited in terms of realism and latency. In this work, we demonstrate how, by applying a newly introduced method based on Generative Adversarial Networks (GANs), we are able to overcome these limitations and provide actionable feedback in real-time to candidates in production settings. Our experimental results highlight the significant benefits of utilizing a GAN-based approach on our dataset relative to two other state-of-the-art approaches (including over 1000x latency gains). We also illustrate the potential impact of this approach in detail on two real candidate profile examples.
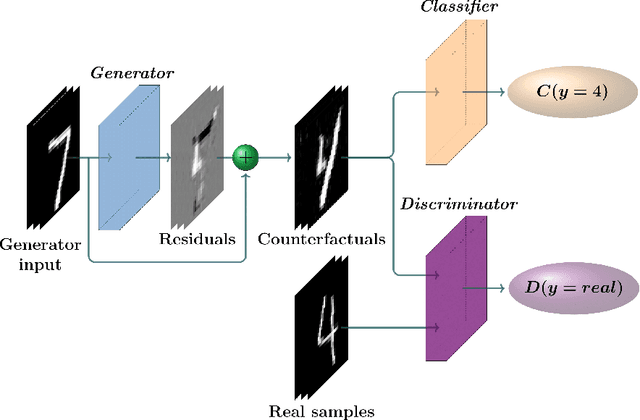
CounteRGAN: Generating Realistic Counterfactuals with Residual Generative Adversarial Nets
Sep 11, 2020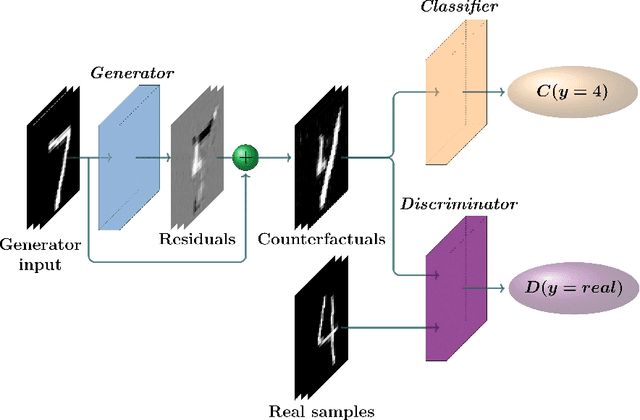
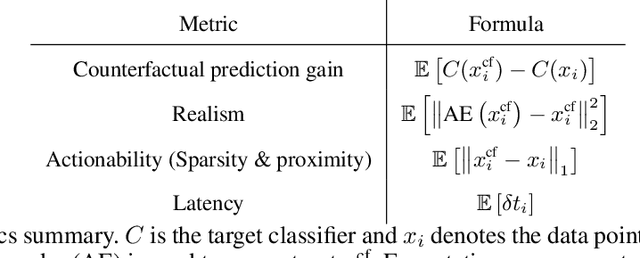
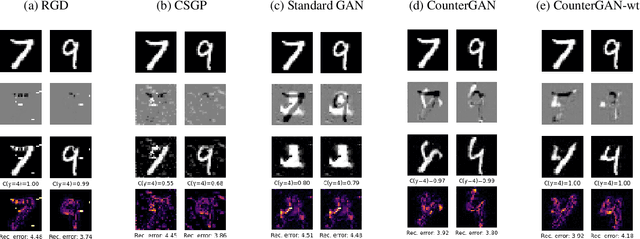
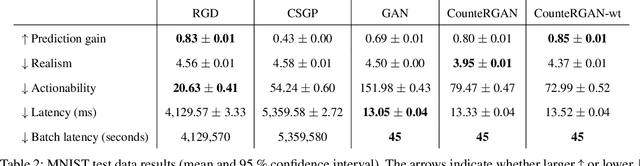
The prevalence of machine learning models in various industries has led to growing demands for model interpretability and for the ability to provide meaningful recourse to users. For example, patients hoping to improve their diagnoses or loan applicants seeking to increase their chances of approval. Counterfactuals can help in this regard by identifying input perturbations that would result in more desirable prediction outcomes. Meaningful counterfactuals should be able to achieve the desired outcome, but also be realistic, actionable, and efficient to compute. Current approaches achieve desired outcomes with moderate actionability but are severely limited in terms of realism and latency. To tackle these limitations, we apply Generative Adversarial Nets (GANs) toward counterfactual search. We also introduce a novel Residual GAN (RGAN) that helps to improve counterfactual realism and actionability compared to regular GANs. The proposed CounteRGAN method utilizes an RGAN and a target classifier to produce counterfactuals capable of providing meaningful recourse. Evaluations on two popular datasets highlight how the CounteRGAN is able to overcome the limitations of existing methods, including latency improvements of >50x to >90,000x, making meaningful recourse available in real-time and applicable to a wide range of domains.
Search by Ideal Candidates: Next Generation of Talent Search at LinkedIn
Feb 26, 2016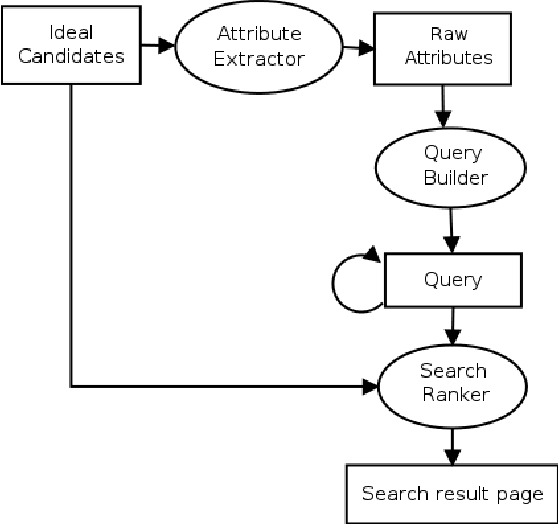
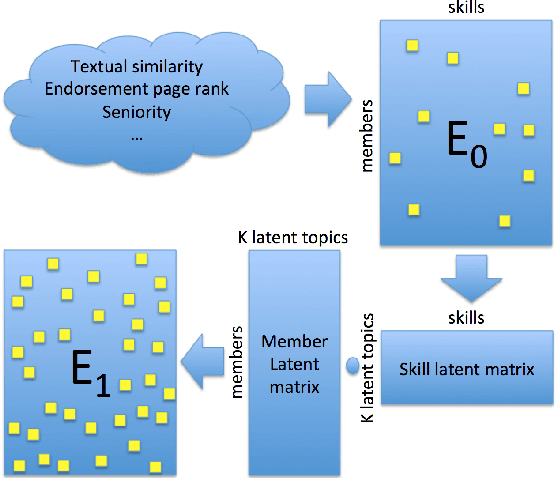
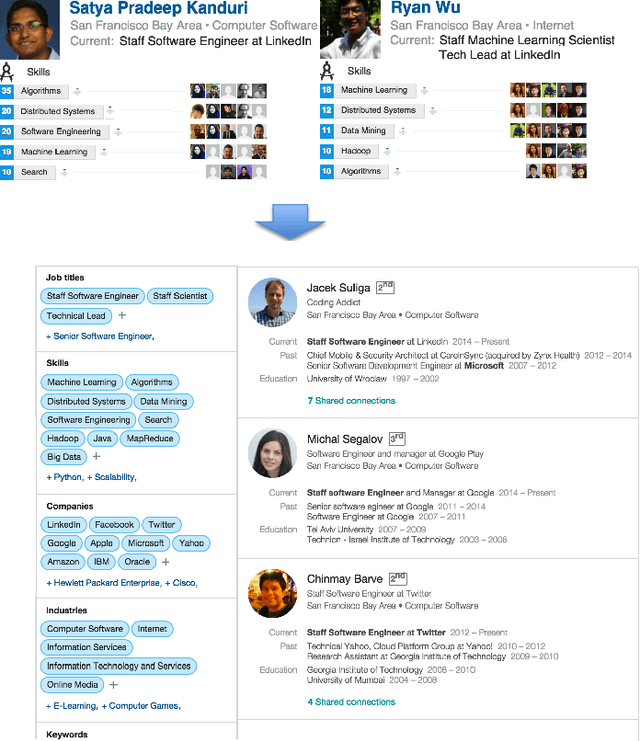
One key challenge in talent search is how to translate complex criteria of a hiring position into a search query. This typically requires deep knowledge on which skills are typically needed for the position, what are their alternatives, which companies are likely to have such candidates, etc. However, listing examples of suitable candidates for a given position is a relatively easy job. Therefore, in order to help searchers overcome this challenge, we design a next generation of talent search paradigm at LinkedIn: Search by Ideal Candidates. This new system only needs the searcher to input one or several examples of suitable candidates for the position. The system will generate a query based on the input candidates and then retrieve and rank results based on the query as well as the input candidates. The query is also shown to the searcher to make the system transparent and to allow the searcher to interact with it. As the searcher modifies the initial query and makes it deviate from the ideal candidates, the search ranking function dynamically adjusts an refreshes the ranking results balancing between the roles of query and ideal candidates. As of writing this paper, the new system is being launched to our customers.