 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential choice in ordered bundles
Oct 29, 2024



Experience goods such as sporting and artistic events, songs, videos, news stories, podcasts, and television series, are often packaged and consumed in bundles. Many such bundles are ordered in the sense that the individual items are consumed sequentially, one at a time. We examine if an individual's decision to consume the next item in an ordered bundle can be predicted based on his/her consumption pattern for the preceding items. We evaluate several predictive models, including two custom Transformers using decoder-only and encoder-decoder architectures, fine-tuned GPT-3, a custom LSTM model, a reinforcement learning model, two Markov models, and a zero-order model. Using data from Spotify, we find that the custom Transformer with a decoder-only architecture provides the most accurate predictions, both for individual choices and aggregate demand. This model captures a general form of state dependence. Analysis of Transformer attention weights suggests that the consumption of the next item in a bundle is based on approximately equal weighting of all preceding choices. Our results indicate that the Transformer can assist in queuing the next item that an individual is likely to consume from an ordered bundle, predicting the demand for individual items, and personalizing promotions to increase demand.
Inferring gender from name: a large scale performance evaluation study
Aug 22, 2023A person's gender is a crucial piece of information when performing research across a wide range of scientific disciplines, such as medicine, sociology, political science, and economics, to name a few. However, in increasing instances, especially given the proliferation of big data, gender information is not readily available. In such cases researchers need to infer gender from readily available information, primarily from persons' names. While inferring gender from name may raise some ethical questions, the lack of viable alternatives means that researchers have to resort to such approaches when the goal justifies the means - in the majority of such studies the goal is to examine patterns and determinants of gender disparities. The necessity of name-to-gender inference has generated an ever-growing domain of algorithmic approaches and software products. These approaches have been used throughout the world in academia, industry, governmental and non-governmental organizations. Nevertheless, the existing approaches have yet to be systematically evaluated and compared, making it challenging to determine the optimal approach for future research. In this work, we conducted a large scale performance evaluation of existing approaches for name-to-gender inference. Analysis are performed using a variety of large annotated datasets of names. We further propose two new hybrid approaches that achieve better performance than any single existing approach.
Evons: A Dataset for Fake and Real News Virality Analysis and Prediction
Sep 16, 2022
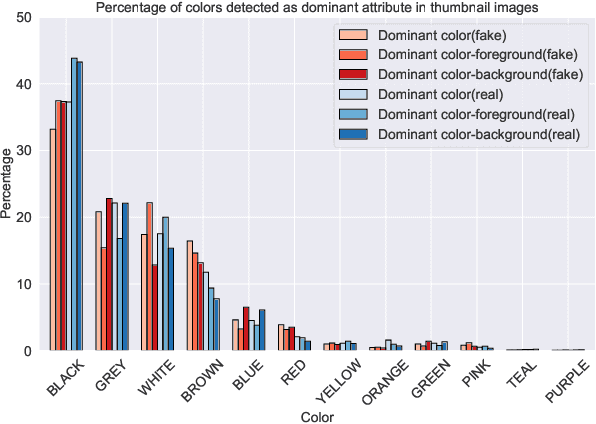

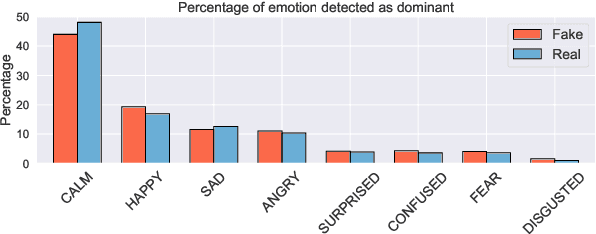
We present a novel collection of news articles originating from fake and real news media sources for the analysis and prediction of news virality. Unlike existing fake news datasets which either contain claims or news article headline and body, in this collection each article is supported with a Facebook engagement count which we consider as an indicator of the article virality. In addition we also provide the article description and thumbnail image with which the article was shared on Facebook. These images were automatically annotated with object tags and color attributes. Using cloud based vision analysis tools, thumbnail images were also analyzed for faces and detected faces were annotated with facial attributes. We empirically investigate the use of this collection on an example task of article virality prediction.
Choosing News Topics to Explain Stock Market Returns
Oct 14, 2020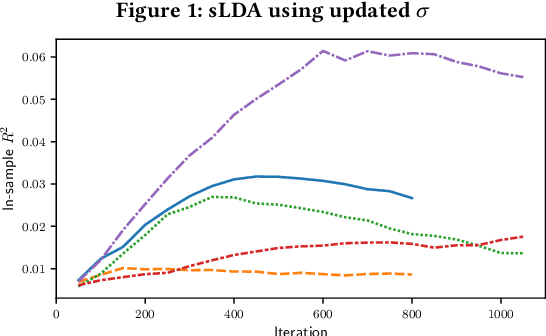
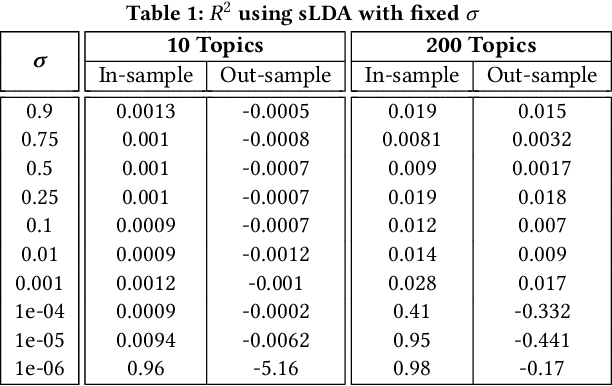
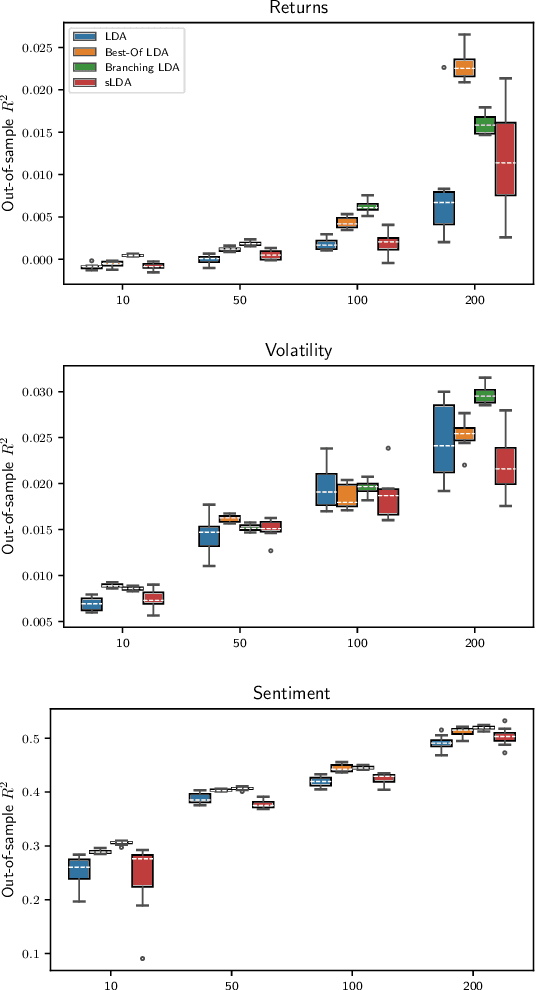
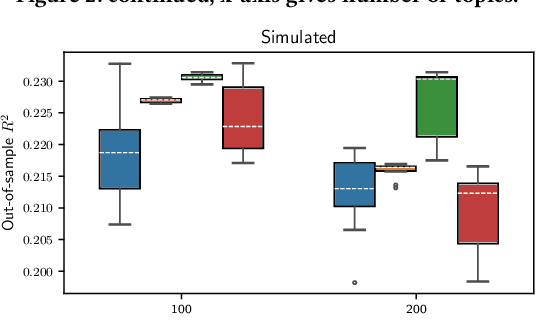
We analyze methods for selecting topics in news articles to explain stock returns. We find, through empirical and theoretical results, that supervised Latent Dirichlet Allocation (sLDA) implemented through Gibbs sampling in a stochastic EM algorithm will often overfit returns to the detriment of the topic model. We obtain better out-of-sample performance through a random search of plain LDA models. A branching procedure that reinforces effective topic assignments often performs best. We test methods on an archive of over 90,000 news articles about S&P 500 firms.
DeSePtion: Dual Sequence Prediction and Adversarial Examples for Improved Fact-Checking
Apr 27, 2020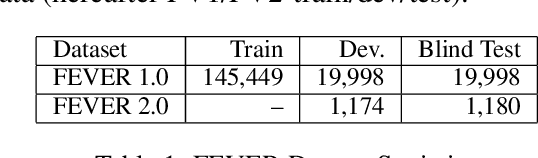
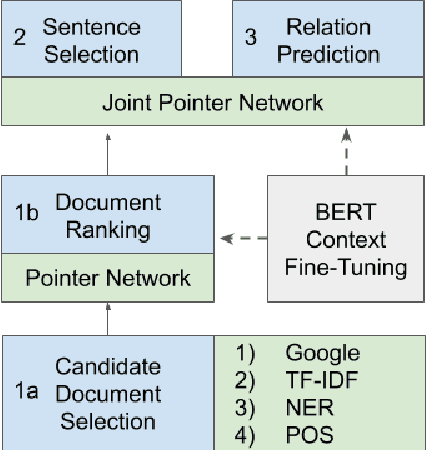
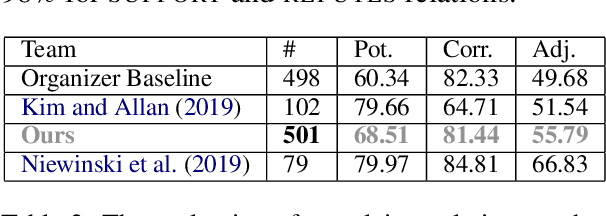
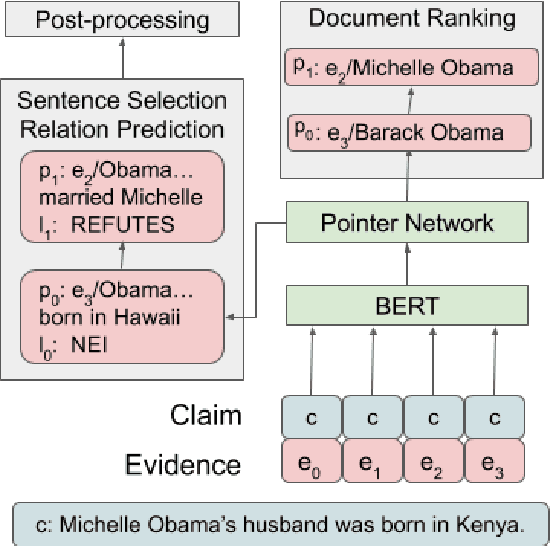
The increased focus on misinformation has spurred development of data and systems for detecting the veracity of a claim as well as retrieving authoritative evidence. The Fact Extraction and VERification (FEVER) dataset provides such a resource for evaluating end-to-end fact-checking, requiring retrieval of evidence from Wikipedia to validate a veracity prediction. We show that current systems for FEVER are vulnerable to three categories of realistic challenges for fact-checking -- multiple propositions, temporal reasoning, and ambiguity and lexical variation -- and introduce a resource with these types of claims. Then we present a system designed to be resilient to these "attacks" using multiple pointer networks for document selection and jointly modeling a sequence of evidence sentences and veracity relation predictions. We find that in handling these attacks we obtain state-of-the-art results on FEVER, largely due to improved evidence retrieval.
Equation Embeddings
Mar 24, 2018
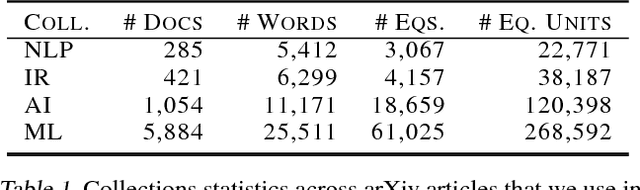
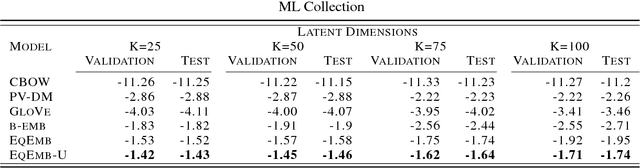
We present an unsupervised approach for discovering semantic representations of mathematical equations. Equations are challenging to analyze because each is unique, or nearly unique. Our method, which we call equation embeddings, finds good representations of equations by using the representations of their surrounding words. We used equation embeddings to analyze four collections of scientific articles from the arXiv, covering four computer science domains (NLP, IR, AI, and ML) and $\sim$98.5k equations. Quantitatively, we found that equation embeddings provide better models when compared to existing word embedding approaches. Qualitatively, we found that equation embeddings provide coherent semantic representations of equations and can capture semantic similarity to other equations and to words.
Multilingual Topic Models
Dec 18, 2017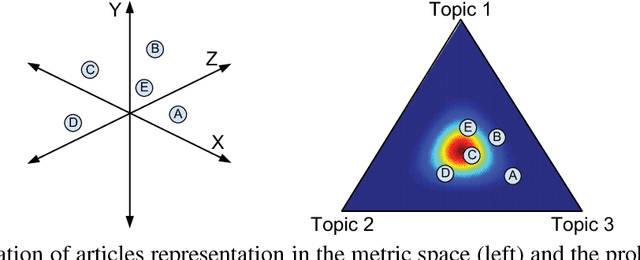
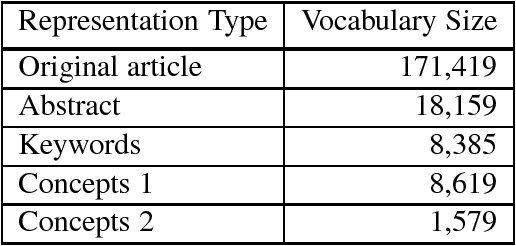
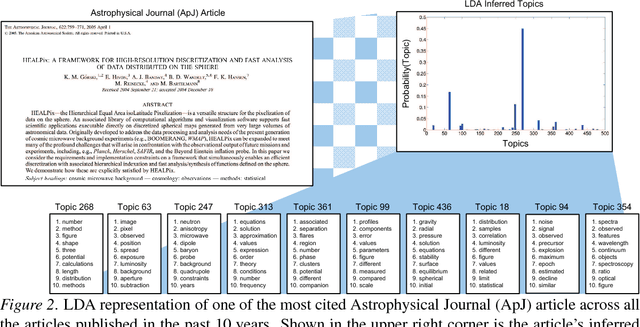
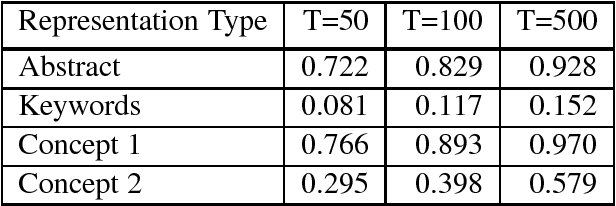
Scientific publications have evolved several features for mitigating vocabulary mismatch when indexing, retrieving, and computing similarity between articles. These mitigation strategies range from simply focusing on high-value article sections, such as titles and abstracts, to assigning keywords, often from controlled vocabularies, either manually or through automatic annotation. Various document representation schemes possess different cost-benefit tradeoffs. In this paper, we propose to model different representations of the same article as translations of each other, all generated from a common latent representation in a multilingual topic model. We start with a methodological overview on latent variable models for parallel document representations that could be used across many information science tasks. We then show how solving the inference problem of mapping diverse representations into a shared topic space allows us to evaluate representations based on how topically similar they are to the original article. In addition, our proposed approach provides means to discover where different concept vocabularies require improvement.