 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models are Few-Shot Training Example Generators: A Case Study in Fallacy Recognition
Nov 16, 2023Recognizing fallacies is crucial for ensuring the quality and validity of arguments across various domains. However, computational fallacy recognition faces challenges due to the diverse genres, domains, and types of fallacies found in datasets. This leads to a highly multiclass, and even multi-label, setup with substantial class imbalance. In this study, we aim to enhance existing models for fallacy recognition by incorporating additional context and by leveraging large language models to generate synthetic data, thus increasing the representation of the infrequent classes. We experiment with GPT3.5 to generate synthetic examples and we examine the impact of prompt settings for this. Moreover, we explore zero-shot and few-shot scenarios to evaluate the effectiveness of using the generated examples for training smaller models within a unified fallacy recognition framework. Furthermore, we analyze the overlap between the synthetic data and existing fallacy datasets. Finally, we investigate the usefulness of providing supplementary context for detecting fallacy types that need such context, e.g., diversion fallacies. Our evaluation results demonstrate consistent improvements across fallacy types, datasets, and generators.
Multitask Instruction-based Prompting for Fallacy Recognition
Jan 24, 2023Fallacies are used as seemingly valid arguments to support a position and persuade the audience about its validity. Recognizing fallacies is an intrinsically difficult task both for humans and machines. Moreover, a big challenge for computational models lies in the fact that fallacies are formulated differently across the datasets with differences in the input format (e.g., question-answer pair, sentence with fallacy fragment), genre (e.g., social media, dialogue, news), as well as types and number of fallacies (from 5 to 18 types per dataset). To move towards solving the fallacy recognition task, we approach these differences across datasets as multiple tasks and show how instruction-based prompting in a multitask setup based on the T5 model improves the results against approaches built for a specific dataset such as T5, BERT or GPT-3. We show the ability of this multitask prompting approach to recognize 28 unique fallacies across domains and genres and study the effect of model size and prompt choice by analyzing the per-class (i.e., fallacy type) results. Finally, we analyze the effect of annotation quality on model performance, and the feasibility of complementing this approach with external knowledge.
* In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 8172 - 8187
AraStance: A Multi-Country and Multi-Domain Dataset of Arabic Stance Detection for Fact Checking
May 18, 2021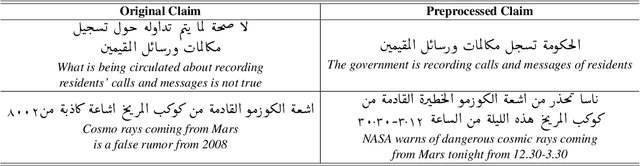

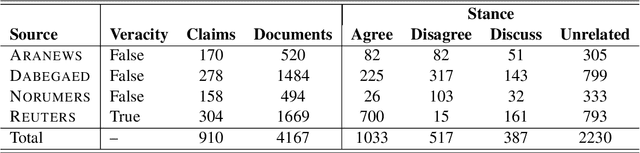
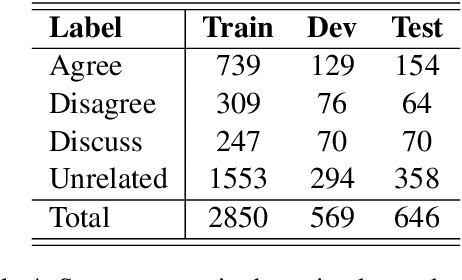
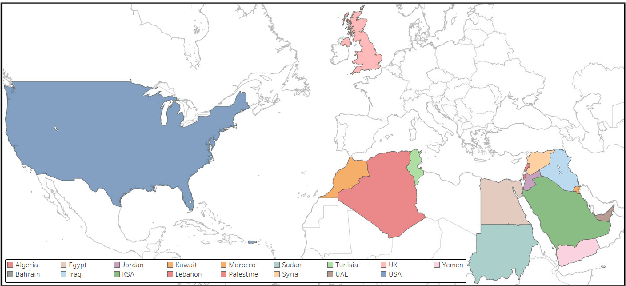
With the continuing spread of misinformation and disinformation online, it is of increasing importance to develop combating mechanisms at scale in the form of automated systems that support multiple languages. One task of interest is claim veracity prediction, which can be addressed using stance detection with respect to relevant documents retrieved online. To this end, we present our new Arabic Stance Detection dataset (AraStance) of 4,063 claim--article pairs from a diverse set of sources comprising three fact-checking websites and one news website. AraStance covers false and true claims from multiple domains (e.g., politics, sports, health) and several Arab countries, and it is well-balanced between related and unrelated documents with respect to the claims. We benchmark AraStance, along with two other stance detection datasets, using a number of BERT-based models. Our best model achieves an accuracy of 85\% and a macro F1 score of 78\%, which leaves room for improvement and reflects the challenging nature of AraStance and the task of stance detection in general.
"Sharks are not the threat humans are": Argument Component Segmentation in School Student Essays
Mar 08, 2021

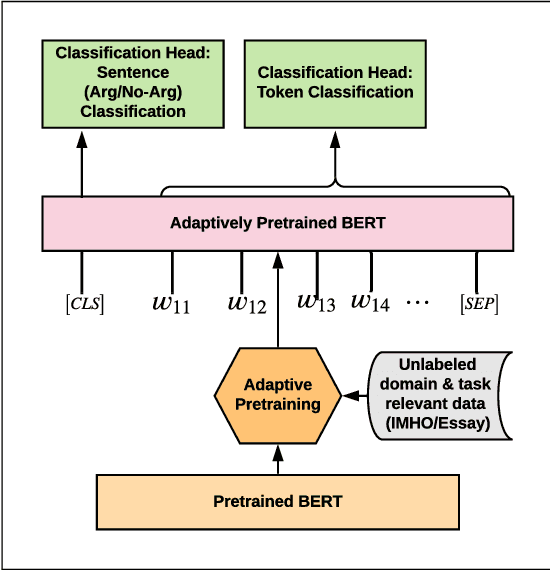
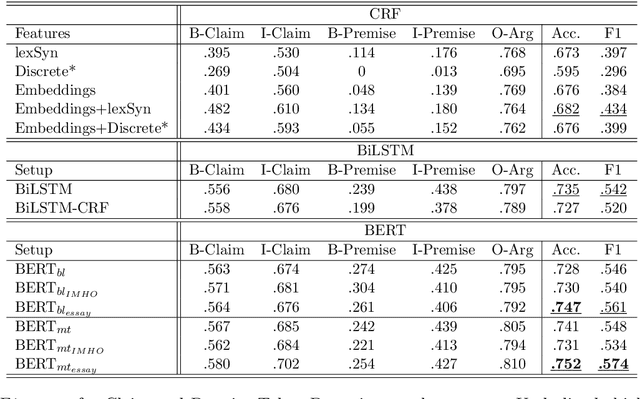
Argument mining is often addressed by a pipeline method where segmentation of text into argumentative units is conducted first and proceeded by an argument component identification task. In this research, we apply a token-level classification to identify claim and premise tokens from a new corpus of argumentative essays written by middle school students. To this end, we compare a variety of state-of-the-art models such as discrete features and deep learning architectures (e.g., BiLSTM networks and BERT-based architectures) to identify the argument components. We demonstrate that a BERT-based multi-task learning architecture (i.e., token and sentence level classification) adaptively pretrained on a relevant unlabeled dataset obtains the best results
Machine Generation and Detection of Arabic Manipulated and Fake News
Nov 05, 2020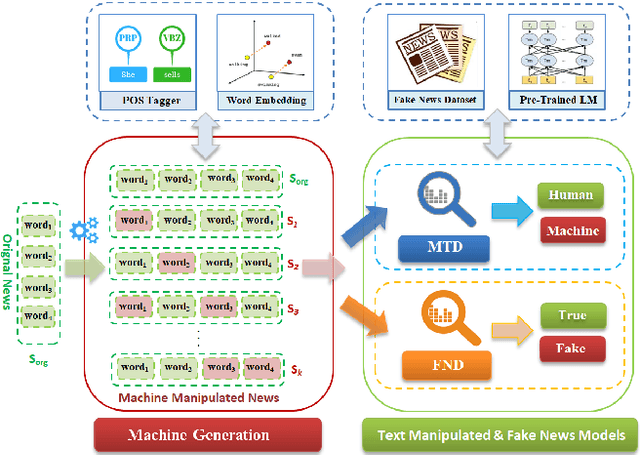
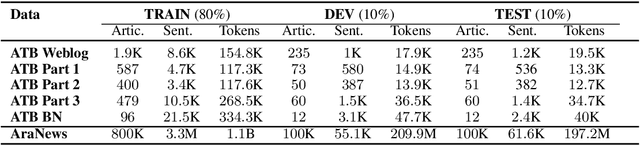
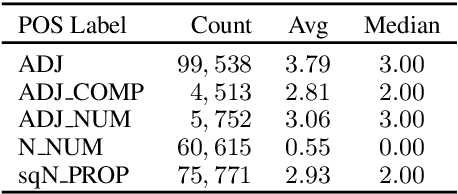
Fake news and deceptive machine-generated text are serious problems threatening modern societies, including in the Arab world. This motivates work on detecting false and manipulated stories online. However, a bottleneck for this research is lack of sufficient data to train detection models. We present a novel method for automatically generating Arabic manipulated (and potentially fake) news stories. Our method is simple and only depends on availability of true stories, which are abundant online, and a part of speech tagger (POS). To facilitate future work, we dispense with both of these requirements altogether by providing AraNews, a novel and large POS-tagged news dataset that can be used off-the-shelf. Using stories generated based on AraNews, we carry out a human annotation study that casts light on the effects of machine manipulation on text veracity. The study also measures human ability to detect Arabic machine manipulated text generated by our method. Finally, we develop the first models for detecting manipulated Arabic news and achieve state-of-the-art results on Arabic fake news detection (macro F1=70.06). Our models and data are publicly available.
DeSePtion: Dual Sequence Prediction and Adversarial Examples for Improved Fact-Checking
Apr 27, 2020
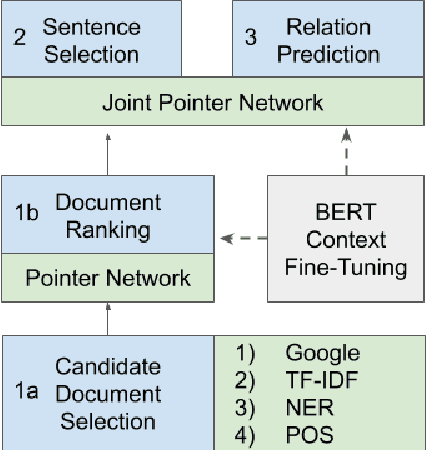
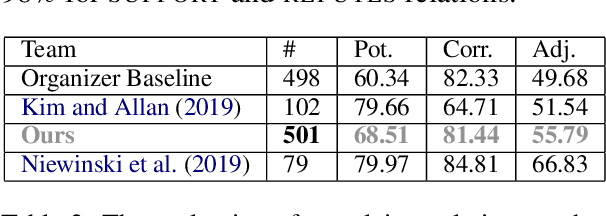
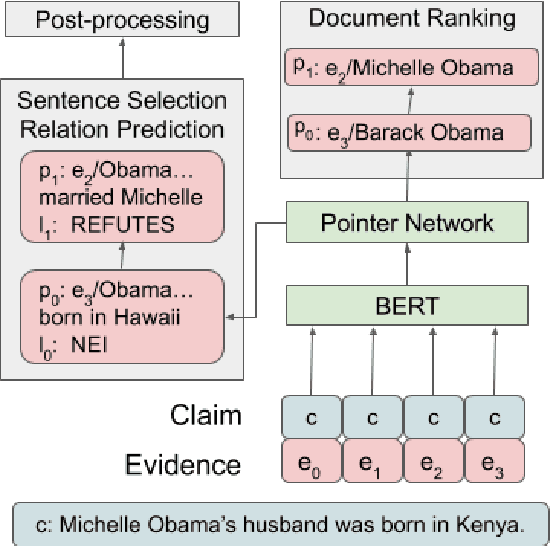
The increased focus on misinformation has spurred development of data and systems for detecting the veracity of a claim as well as retrieving authoritative evidence. The Fact Extraction and VERification (FEVER) dataset provides such a resource for evaluating end-to-end fact-checking, requiring retrieval of evidence from Wikipedia to validate a veracity prediction. We show that current systems for FEVER are vulnerable to three categories of realistic challenges for fact-checking -- multiple propositions, temporal reasoning, and ambiguity and lexical variation -- and introduce a resource with these types of claims. Then we present a system designed to be resilient to these "attacks" using multiple pointer networks for document selection and jointly modeling a sequence of evidence sentences and veracity relation predictions. We find that in handling these attacks we obtain state-of-the-art results on FEVER, largely due to improved evidence retrieval.
Fine-Tuned Neural Models for Propaganda Detection at the Sentence and Fragment levels
Oct 22, 2019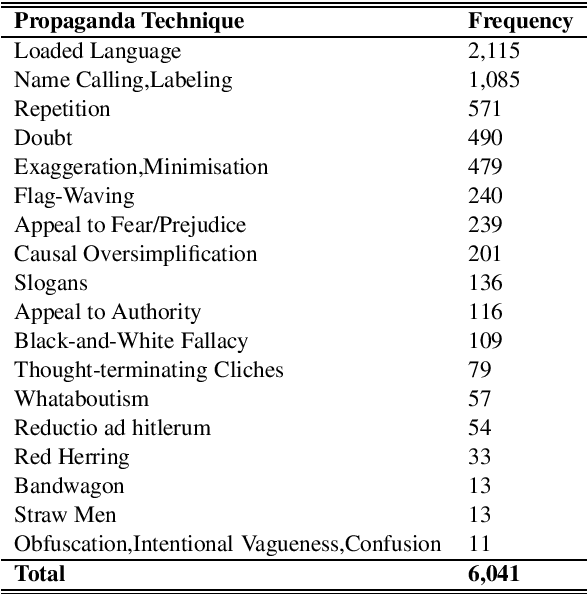
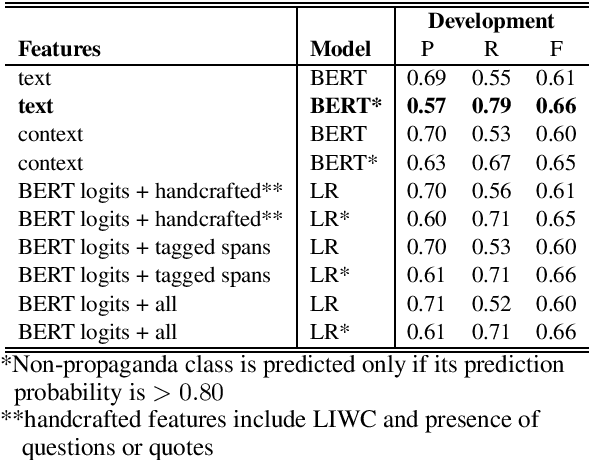
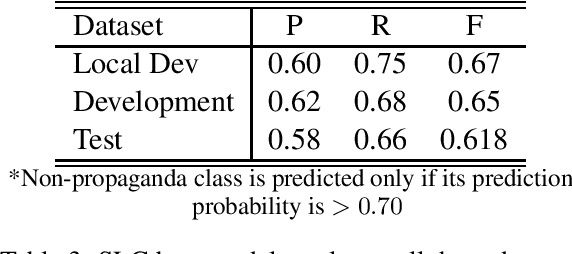
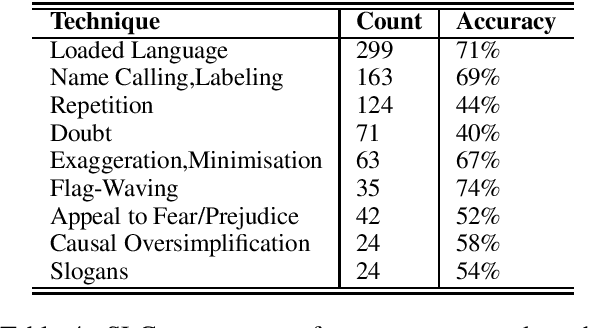
This paper presents the CUNLP submission for the NLP4IF 2019 shared-task on FineGrained Propaganda Detection. Our system finished 5th out of 26 teams on the sentence-level classification task and 5th out of 11 teams on the fragment-level classification task based on our scores on the blind test set. We present our models, a discussion of our ablation studies and experiments, and an analysis of our performance on all eighteen propaganda techniques present in the corpus of the shared task.