 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Reinforcement Learning Agents Using World Models
May 12, 2025Explainable AI (XAI) systems have been proposed to help people understand how AI systems produce outputs and behaviors. Explainable Reinforcement Learning (XRL) has an added complexity due to the temporal nature of sequential decision-making. Further, non-AI experts do not necessarily have the ability to alter an agent or its policy. We introduce a technique for using World Models to generate explanations for Model-Based Deep RL agents. World Models predict how the world will change when actions are performed, allowing for the generation of counterfactual trajectories. However, identifying what a user wanted the agent to do is not enough to understand why the agent did something else. We augment Model-Based RL agents with a Reverse World Model, which predicts what the state of the world should have been for the agent to prefer a given counterfactual action. We show that explanations that show users what the world should have been like significantly increase their understanding of the agent policy. We hypothesize that our explanations can help users learn how to control the agents execution through by manipulating the environment.
Experiential Explanations for Reinforcement Learning
Oct 10, 2022
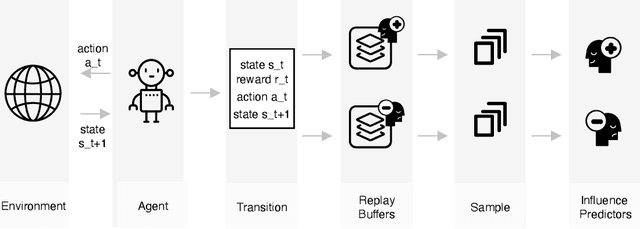

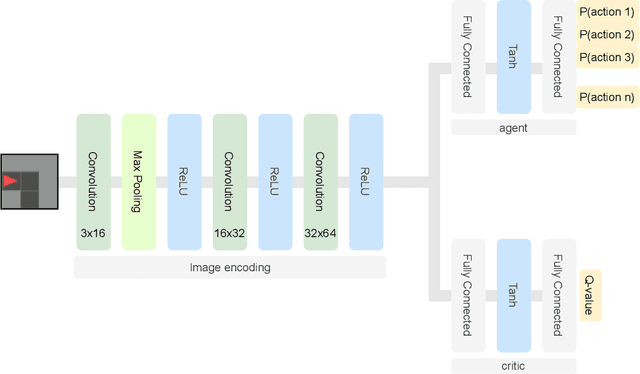
Reinforcement Learning (RL) approaches are becoming increasingly popular in various key disciplines, including robotics and healthcare. However, many of these systems are complex and non-interpretable, making it challenging for non-AI experts to understand or intervene. One of the challenges of explaining RL agent behavior is that, when learning to predict future expected reward, agents discard contextual information about their experiences when training in an environment and rely solely on expected utility. We propose a technique, Experiential Explanations, for generating local counterfactual explanations that can answer users' why-not questions by explaining qualitatively the effects of the various environmental rewards on the agent's behavior. We achieve this by training additional modules alongside the policy. These models, called influence predictors, model how different reward sources influence the agent's policy, thus restoring lost contextual information about how the policy reflects the environment. To generate explanations, we use these models in addition to the policy to contrast between the agent's intended behavior trajectory and a counterfactual trajectory suggested by the user.
Guiding Neural Story Generation with Reader Models
Dec 16, 2021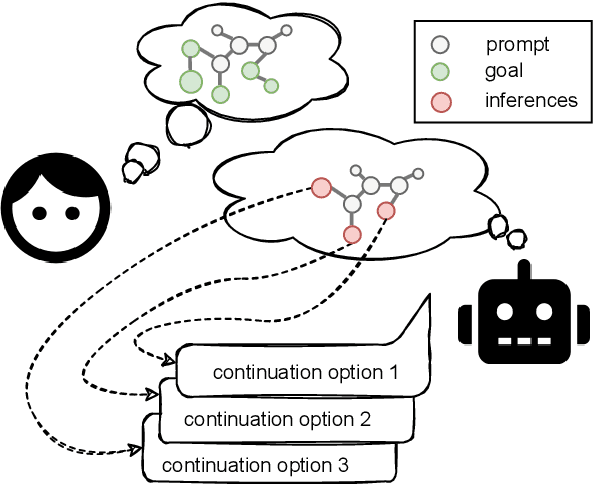

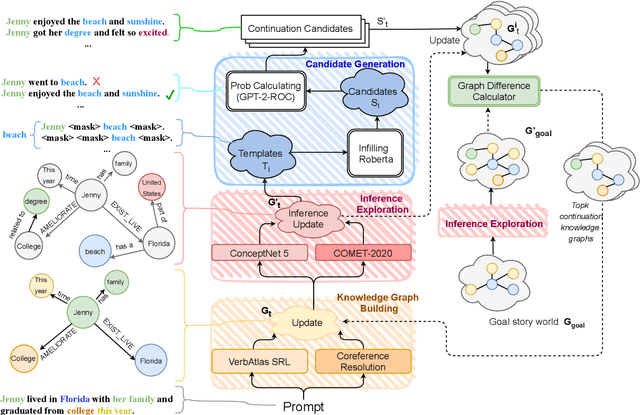

Automated storytelling has long captured the attention of researchers for the ubiquity of narratives in everyday life. However, it is challenging to maintain coherence and stay on-topic toward a specific ending when generating narratives with neural language models. In this paper, we introduce Story generation with Reader Models (StoRM), a framework in which a reader model is used to reason about the story should progress. A reader model infers what a human reader believes about the concepts, entities, and relations about the fictional story world. We show how an explicit reader model represented as a knowledge graph affords story coherence and provides controllability in the form of achieving a given story world state goal. Experiments show that our model produces significantly more coherent and on-topic stories, outperforming baselines in dimensions including plot plausibility and staying on topic. Our system also outperforms outline-guided story generation baselines in composing given concepts without ordering.
Goal-Directed Story Generation: Augmenting Generative Language Models with Reinforcement Learning
Dec 16, 2021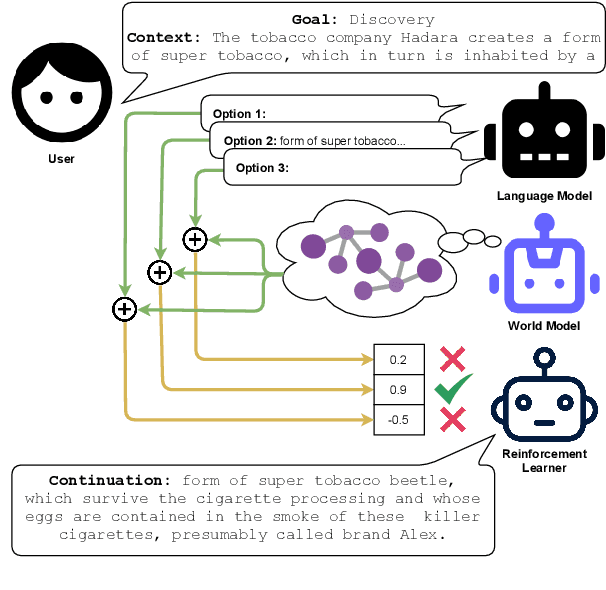
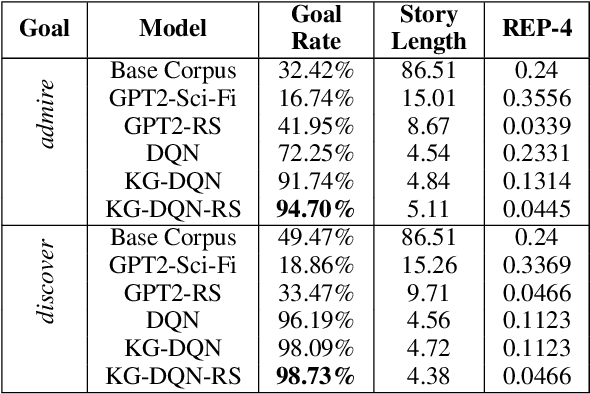
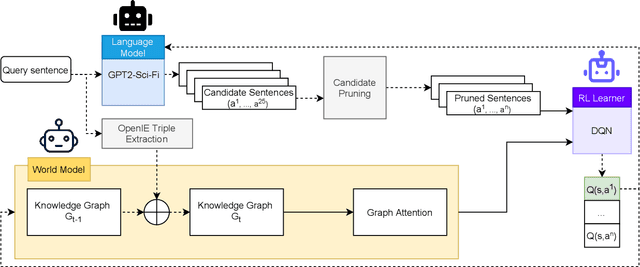
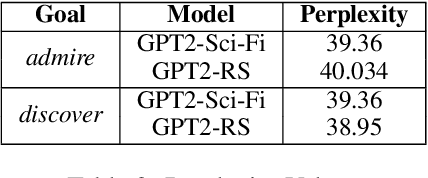
The advent of large pre-trained generative language models has provided a common framework for AI story generation via sampling the model to create sequences that continue the story. However, sampling alone is insufficient for story generation. In particular, it is hard to direct a language model to create stories to reach a specific goal event. We present two automated techniques grounded in deep reinforcement learning and reward shaping to control the plot of computer-generated stories. The first utilizes proximal policy optimization to fine-tune an existing transformer-based language model to generate text continuations but also be goal-seeking. The second extracts a knowledge graph from the unfolding story, which is used by a policy network with graph attention to select a candidate continuation generated by a language model. We report on automated metrics pertaining to how often stories achieve a given goal event as well as human participant rankings of coherence and overall story quality compared to baselines and ablations.
AraStance: A Multi-Country and Multi-Domain Dataset of Arabic Stance Detection for Fact Checking
May 18, 2021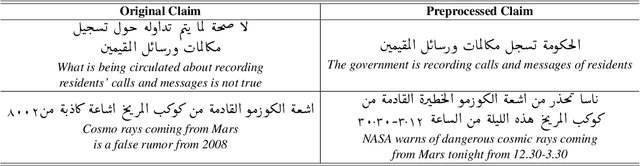

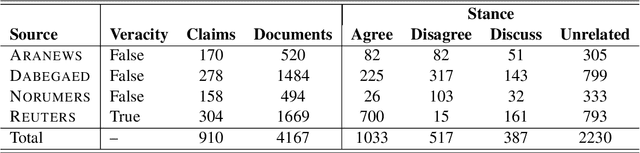
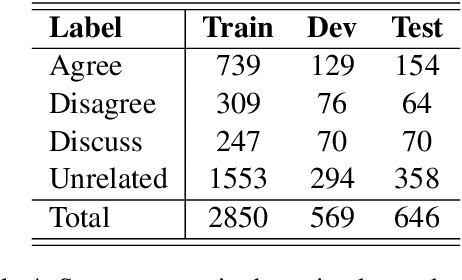
With the continuing spread of misinformation and disinformation online, it is of increasing importance to develop combating mechanisms at scale in the form of automated systems that support multiple languages. One task of interest is claim veracity prediction, which can be addressed using stance detection with respect to relevant documents retrieved online. To this end, we present our new Arabic Stance Detection dataset (AraStance) of 4,063 claim--article pairs from a diverse set of sources comprising three fact-checking websites and one news website. AraStance covers false and true claims from multiple domains (e.g., politics, sports, health) and several Arab countries, and it is well-balanced between related and unrelated documents with respect to the claims. We benchmark AraStance, along with two other stance detection datasets, using a number of BERT-based models. Our best model achieves an accuracy of 85\% and a macro F1 score of 78\%, which leaves room for improvement and reflects the challenging nature of AraStance and the task of stance detection in general.
Automatic Story Generation: Challenges and Attempts
Feb 25, 2021
The scope of this survey paper is to explore the challenges in automatic story generation. We hope to contribute in the following ways: 1. Explore how previous research in story generation addressed those challenges. 2. Discuss future research directions and new technologies that may aid more advancements. 3. Shed light on emerging and often overlooked challenges such as creativity and discourse.