 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment Whack-a-Mole : Finetuning Activates Verbatim Recall of Copyrighted Books in Large Language Models
Mar 21, 2026Frontier LLM companies have repeatedly assured courts and regulators that their models do not store copies of training data. They further rely on safety alignment strategies via RLHF, system prompts, and output filters to block verbatim regurgitation of copyrighted works, and have cited the efficacy of these measures in their legal defenses against copyright infringement claims. We show that finetuning bypasses these protections: by training models to expand plot summaries into full text, a task naturally suited for commercial writing assistants, we cause GPT-4o, Gemini-2.5-Pro, and DeepSeek-V3.1 to reproduce up to 85-90% of held-out copyrighted books, with single verbatim spans exceeding 460 words, using only semantic descriptions as prompts and no actual book text. This extraction generalizes across authors: finetuning exclusively on Haruki Murakami's novels unlocks verbatim recall of copyrighted books from over 30 unrelated authors. The effect is not specific to any training author or corpus: random author pairs and public-domain finetuning data produce comparable extraction, while finetuning on synthetic text yields near-zero extraction, indicating that finetuning on individual authors' works reactivates latent memorization from pretraining. Three models from different providers memorize the same books in the same regions ($r \ge 0.90$), pointing to an industry-wide vulnerability. Our findings offer compelling evidence that model weights store copies of copyrighted works and that the security failures that manifest after finetuning on individual authors' works undermine a key premise of recent fair use rulings, where courts have conditioned favorable outcomes on the adequacy of measures preventing reproduction of protected expression.
Can Good Writing Be Generative? Expert-Level AI Writing Emerges through Fine-Tuning on High-Quality Books
Jan 26, 2026Creative writing has long been considered a uniquely human endeavor, requiring voice and style that machines could not replicate. This assumption is challenged by Generative AI that can emulate thousands of author styles in seconds with negligible marginal labor. To understand this better, we conducted a behavioral experiment where 28 MFA writers (experts) competed against three LLMs in emulating 50 critically acclaimed authors. Based on blind pairwise comparisons by 28 expert judges and 131 lay judges, we find that experts preferred human writing in 82.7% of cases under the in-context prompting condition but this reversed to 62% preference for AI after fine-tuning on authors' complete works. Lay judges, however, consistently preferred AI writing. Debrief interviews with expert writers revealed that their preference for AI writing triggered an identity crisis, eroding aesthetic confidence and questioning what constitutes "good writing." These findings challenge discourse about AI's creative limitations and raise fundamental questions about the future of creative labor.
Death of the Novel(ty): Beyond n-Gram Novelty as a Metric for Textual Creativity
Sep 26, 2025



N-gram novelty is widely used to evaluate language models' ability to generate text outside of their training data. More recently, it has also been adopted as a metric for measuring textual creativity. However, theoretical work on creativity suggests that this approach may be inadequate, as it does not account for creativity's dual nature: novelty (how original the text is) and appropriateness (how sensical and pragmatic it is). We investigate the relationship between this notion of creativity and n-gram novelty through 7542 expert writer annotations (n=26) of novelty, pragmaticality, and sensicality via close reading of human and AI-generated text. We find that while n-gram novelty is positively associated with expert writer-judged creativity, ~91% of top-quartile expressions by n-gram novelty are not judged as creative, cautioning against relying on n-gram novelty alone. Furthermore, unlike human-written text, higher n-gram novelty in open-source LLMs correlates with lower pragmaticality. In an exploratory study with frontier close-source models, we additionally confirm that they are less likely to produce creative expressions than humans. Using our dataset, we test whether zero-shot, few-shot, and finetuned models are able to identify creative expressions (a positive aspect of writing) and non-pragmatic ones (a negative aspect). Overall, frontier LLMs exhibit performance much higher than random but leave room for improvement, especially struggling to identify non-pragmatic expressions. We further find that LLM-as-a-Judge novelty scores from the best-performing model were predictive of expert writer preferences.
Facilitating Longitudinal Interaction Studies of AI Systems
Aug 14, 2025UIST researchers develop tools to address user challenges. However, user interactions with AI evolve over time through learning, adaptation, and repurposing, making one time evaluations insufficient. Capturing these dynamics requires longer-term studies, but challenges in deployment, evaluation design, and data collection have made such longitudinal research difficult to implement. Our workshop aims to tackle these challenges and prepare researchers with practical strategies for longitudinal studies. The workshop includes a keynote, panel discussions, and interactive breakout groups for discussion and hands-on protocol design and tool prototyping sessions. We seek to foster a community around longitudinal system research and promote it as a more embraced method for designing, building, and evaluating UIST tools.
AI Safety Should Prioritize the Future of Work
Apr 16, 2025Current efforts in AI safety prioritize filtering harmful content, preventing manipulation of human behavior, and eliminating existential risks in cybersecurity or biosecurity. While pressing, this narrow focus overlooks critical human-centric considerations that shape the long-term trajectory of a society. In this position paper, we identify the risks of overlooking the impact of AI on the future of work and recommend comprehensive transition support towards the evolution of meaningful labor with human agency. Through the lens of economic theories, we highlight the intertemporal impacts of AI on human livelihood and the structural changes in labor markets that exacerbate income inequality. Additionally, the closed-source approach of major stakeholders in AI development resembles rent-seeking behavior through exploiting resources, breeding mediocrity in creative labor, and monopolizing innovation. To address this, we argue in favor of a robust international copyright anatomy supported by implementing collective licensing that ensures fair compensation mechanisms for using data to train AI models. We strongly recommend a pro-worker framework of global AI governance to enhance shared prosperity and economic justice while reducing technical debt.
AI-Slop to AI-Polish? Aligning Language Models through Edit-Based Writing Rewards and Test-time Computation
Apr 10, 2025AI-generated text is proliferating across domains, from creative writing and journalism to marketing content and scientific articles. Models can follow user-provided instructions to generate coherent and grammatically correct outputs but in this work, we study a more fundamental question: how do we evaluate and improve the writing quality of AI-generated text? Writing quality assessment has received less attention from the community, in part because it is fundamentally subjective and requires expertise. We first introduce the Writing Quality Benchmark (WQ) by consolidating five writing-preference datasets into 4,729 writing quality judgments. Our experiments show that competitive baselines, including state-of-the-art LLMs that excel at reasoning tasks, barely outperform random baselines on WQ. We then train specialized Writing Quality Reward Models (WQRM) of various sizes for writing quality assessment that demonstrate strong generalization on four out-of-distribution test sets and 74% accuracy on the WQ benchmark. To further show WQRM's practical benefits during inference, we leverage additional test-time compute to generate and rank multiple candidate revisions, allowing us to select higher-quality outputs from an initial draft. Human evaluation with 9 experienced writers confirm that WQRM-based selection produces writing samples preferred by experts 66% overall, and 72.2% when the reward gap is larger than 1 point. We release our datasets and models to encourage community engagement with writing quality assessment and development of AI writing systems better aligned with human preferences.
How do Humans and Language Models Reason About Creativity? A Comparative Analysis
Feb 05, 2025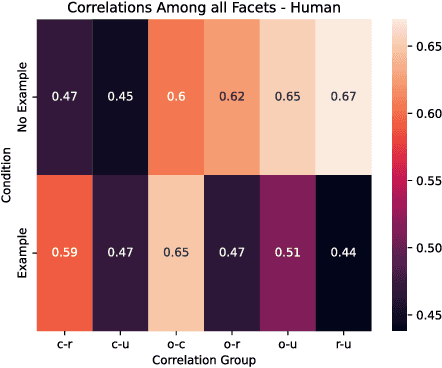
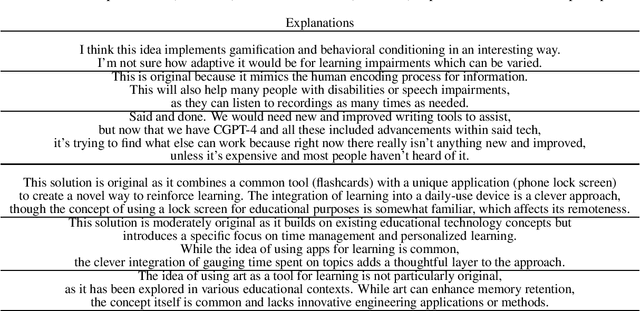
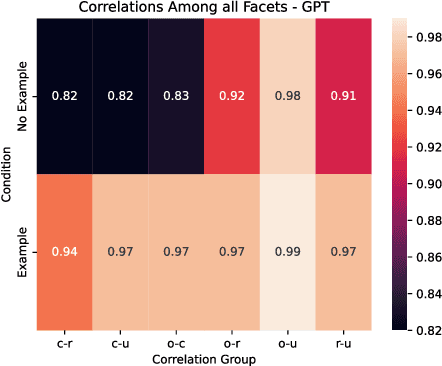
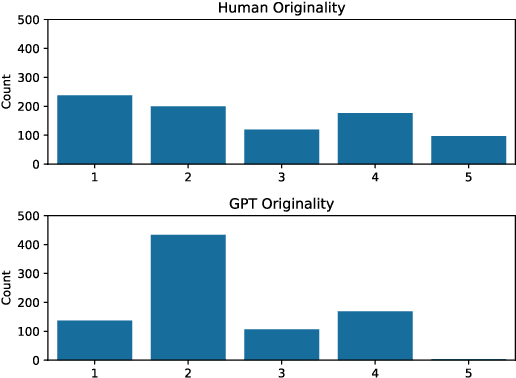
Creativity assessment in science and engineering is increasingly based on both human and AI judgment, but the cognitive processes and biases behind these evaluations remain poorly understood. We conducted two experiments examining how including example solutions with ratings impact creativity evaluation, using a finegrained annotation protocol where raters were tasked with explaining their originality scores and rating for the facets of remoteness (whether the response is "far" from everyday ideas), uncommonness (whether the response is rare), and cleverness. In Study 1, we analyzed creativity ratings from 72 experts with formal science or engineering training, comparing those who received example solutions with ratings (example) to those who did not (no example). Computational text analysis revealed that, compared to experts with examples, no-example experts used more comparative language (e.g., "better/worse") and emphasized solution uncommonness, suggesting they may have relied more on memory retrieval for comparisons. In Study 2, parallel analyses with state-of-the-art LLMs revealed that models prioritized uncommonness and remoteness of ideas when rating originality, suggesting an evaluative process rooted around the semantic similarity of ideas. In the example condition, while LLM accuracy in predicting the true originality scores improved, the correlations of remoteness, uncommonness, and cleverness with originality also increased substantially - to upwards of 0.99 - suggesting a homogenization in the LLMs evaluation of the individual facets. These findings highlight important implications for how humans and AI reason about creativity and suggest diverging preferences for what different populations prioritize when rating.
Can AI writing be salvaged? Mitigating Idiosyncrasies and Improving Human-AI Alignment in the Writing Process through Edits
Sep 26, 2024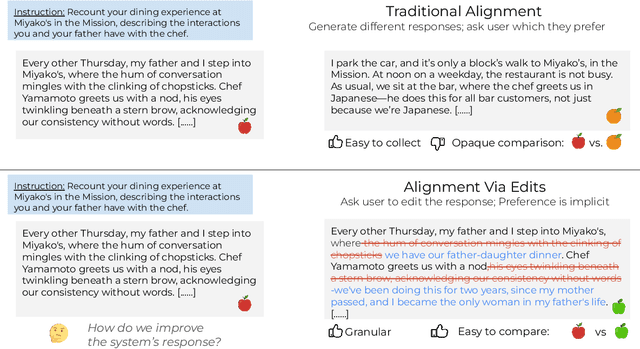
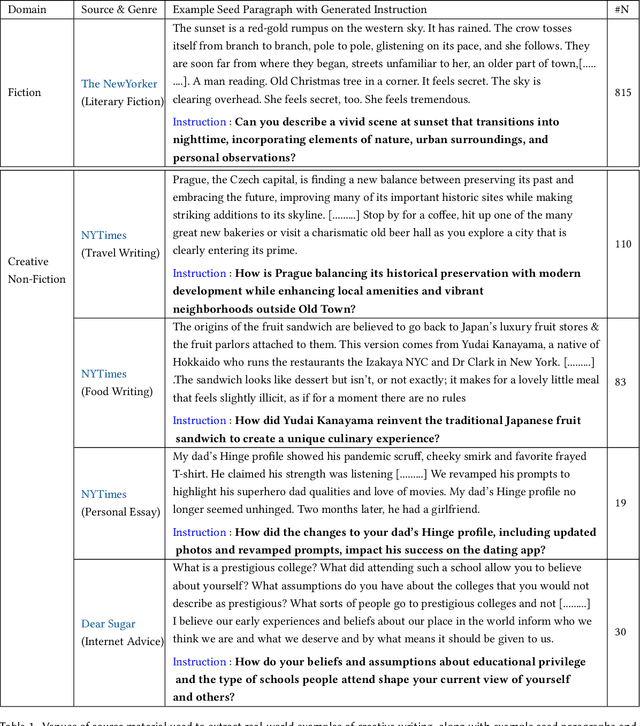
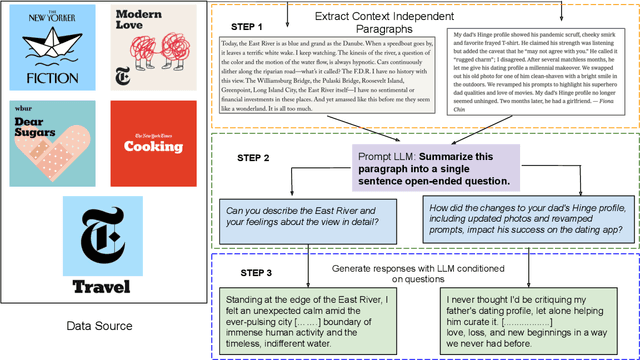
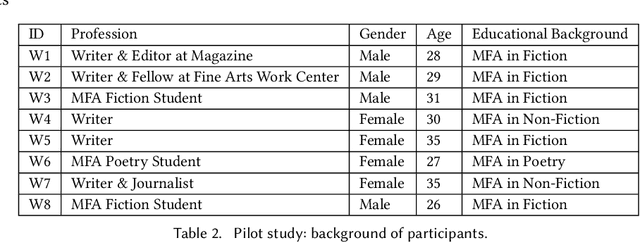
LLM-based applications are helping people write, and LLM-generated text is making its way into social media, journalism, and our classrooms. However, the differences between LLM-generated and human-written text remain unclear. To explore this, we hired professional writers to edit paragraphs in several creative domains. We first found these writers agree on undesirable idiosyncrasies in LLM-generated text, formalizing it into a seven-category taxonomy (e.g. cliches, unnecessary exposition). Second, we curated the LAMP corpus: 1,057 LLM-generated paragraphs edited by professional writers according to our taxonomy. Analysis of LAMP reveals that none of the LLMs used in our study (GPT4o, Claude-3.5-Sonnet, Llama-3.1-70b) outperform each other in terms of writing quality, revealing common limitations across model families. Third, we explored automatic editing methods to improve LLM-generated text. A large-scale preference annotation confirms that although experts largely prefer text edited by other experts, automatic editing methods show promise in improving alignment between LLM-generated and human-written text.
Connecting the Dots: Evaluating Abstract Reasoning Capabilities of LLMs Using the New York Times Connections Word Game
Jun 18, 2024The New York Times Connections game has emerged as a popular and challenging pursuit for word puzzle enthusiasts. We collect 200 Connections games to evaluate the performance of state-of-the-art large language models (LLMs) against expert and novice human players. Our results show that even the best-performing LLM, GPT-4o, which has otherwise shown impressive reasoning abilities on a wide variety of benchmarks, can only fully solve 8% of the games. Compared to GPT-4o, novice and expert players perform better, with expert human players significantly outperforming GPT-4o. To deepen our understanding we create a taxonomy of the knowledge types required to successfully categorize words in the Connections game, revealing that LLMs struggle with associative, encyclopedic, and linguistic knowledge. Our findings establish the New York Times Connections game as a challenging benchmark for evaluating abstract reasoning capabilities in humans and AI systems.
V-FLUTE: Visual Figurative Language Understanding with Textual Explanations
May 02, 2024Large Vision-Language models (VLMs) have demonstrated strong reasoning capabilities in tasks requiring a fine-grained understanding of literal images and text, such as visual question-answering or visual entailment. However, there has been little exploration of these models' capabilities when presented with images and captions containing figurative phenomena such as metaphors or humor, the meaning of which is often implicit. To close this gap, we propose a new task and a high-quality dataset: Visual Figurative Language Understanding with Textual Explanations (V-FLUTE). We frame the visual figurative language understanding problem as an explainable visual entailment task, where the model has to predict whether the image (premise) entails a claim (hypothesis) and justify the predicted label with a textual explanation. Using a human-AI collaboration framework, we build a high-quality dataset, V-FLUTE, that contains 6,027 <image, claim, label, explanation> instances spanning five diverse multimodal figurative phenomena: metaphors, similes, idioms, sarcasm, and humor. The figurative phenomena can be present either in the image, the caption, or both. We further conduct both automatic and human evaluations to assess current VLMs' capabilities in understanding figurative phenomena.