 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubleAgents: Exploring Mechanisms of Building Trust with Proactive AI
Sep 16, 2025Agentic workflows promise efficiency, but adoption hinges on whether people actually trust systems that act on their behalf. We present DoubleAgents, an agentic planning tool that embeds transparency and control through user intervention, value-reflecting policies, rich state visualizations, and uncertainty flagging for human coordination tasks. A built-in respondent simulation generates realistic scenarios, allowing users to rehearse, refine policies, and calibrate their reliance before live use. We evaluate DoubleAgents in a two-day lab study (n=10), two deployments (n=2), and a technical evaluation. Results show that participants initially hesitated to delegate but grew more reliant as they experienced transparency, control, and adaptive learning during simulated cases. Deployment results demonstrate DoubleAgents' real-world relevance and usefulness, showing that the effort required scaled appropriately with task complexity and contextual data. We contribute trust-by-design patterns and mechanisms for proactive AI -- consistency, controllability, and explainability -- along with simulation as a safe path to build and calibrate trust over time.
Facilitating Longitudinal Interaction Studies of AI Systems
Aug 14, 2025UIST researchers develop tools to address user challenges. However, user interactions with AI evolve over time through learning, adaptation, and repurposing, making one time evaluations insufficient. Capturing these dynamics requires longer-term studies, but challenges in deployment, evaluation design, and data collection have made such longitudinal research difficult to implement. Our workshop aims to tackle these challenges and prepare researchers with practical strategies for longitudinal studies. The workshop includes a keynote, panel discussions, and interactive breakout groups for discussion and hands-on protocol design and tool prototyping sessions. We seek to foster a community around longitudinal system research and promote it as a more embraced method for designing, building, and evaluating UIST tools.
FeedQUAC: Quick Unobtrusive AI-Generated Commentary
Apr 23, 2025
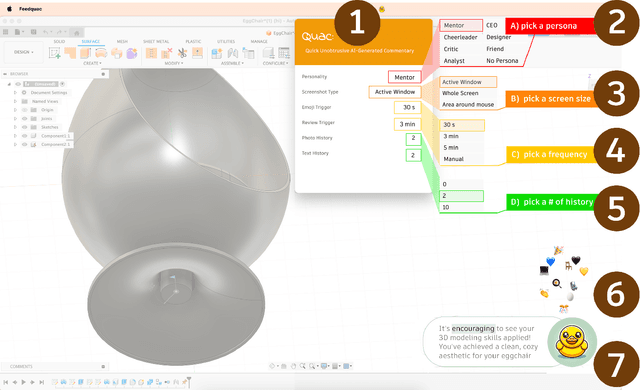


Design thrives on feedback. However, gathering constant feedback throughout the design process can be labor-intensive and disruptive. We explore how AI can bridge this gap by providing effortless, ambient feedback. We introduce FeedQUAC, a design companion that delivers real-time AI-generated commentary from a variety of perspectives through different personas. A design probe study with eight participants highlights how designers can leverage quick yet ambient AI feedback to enhance their creative workflows. Participants highlight benefits such as convenience, playfulness, confidence boost, and inspiration from this lightweight feedback agent, while suggesting additional features, like chat interaction and context curation. We discuss the role of AI feedback, its strengths and limitations, and how to integrate it into existing design workflows while balancing user involvement. Our findings also suggest that ambient interaction is a valuable consideration for both the design and evaluation of future creativity support systems.
Optimizing Mobile-Friendly Viewport Prediction for Live 360-Degree Video Streaming
Mar 05, 2024



Viewport prediction is the crucial task for adaptive 360-degree video streaming, as the bitrate control algorithms usually require the knowledge of the user's viewing portions of the frames. Various methods are studied and adopted for viewport prediction from less accurate statistic tools to highly calibrated deep neural networks. Conventionally, it is difficult to implement sophisticated deep learning methods on mobile devices, which have limited computation capability. In this work, we propose an advanced learning-based viewport prediction approach and carefully design it to introduce minimal transmission and computation overhead for mobile terminals. We also propose a model-agnostic meta-learning (MAML) based saliency prediction network trainer, which provides a few-sample fast training solution to obtain the prediction model by utilizing the information from the past models. We further discuss how to integrate this mobile-friendly viewport prediction (MFVP) approach into a typical 360-degree video live streaming system by formulating and solving the bitrate adaptation problem. Extensive experiment results show that our prediction approach can work in real-time for live video streaming and can achieve higher accuracies compared to other existing prediction methods on mobile end, which, together with our bitrate adaptation algorithm, significantly improves the streaming QoE from various aspects. We observe the accuracy of MFVP is 8.1$\%$ to 28.7$\%$ higher than other algorithms and achieves 3.73$\%$ to 14.96$\%$ higher average quality level and 49.6$\%$ to 74.97$\%$ less quality level change than other algorithms.
Not Just Novelty: A Longitudinal Study on Utility and Customization of AI Workflows
Feb 15, 2024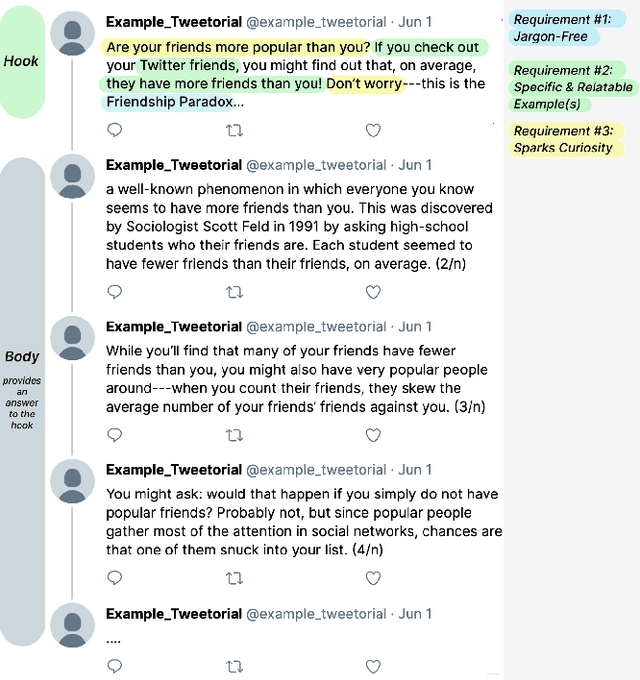
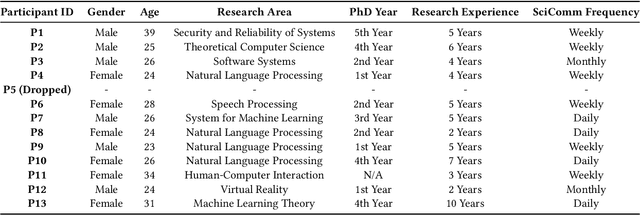

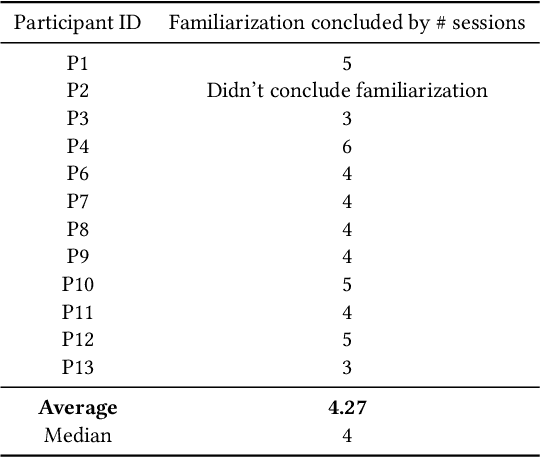
Generative AI brings novel and impressive abilities to help people in everyday tasks. There are many AI workflows that solve real and complex problems by chaining AI outputs together with human interaction. Although there is an undeniable lure of AI, it's uncertain how useful generative AI workflows are after the novelty wears off. Additionally, tools built with generative AI have the potential to be personalized and adapted quickly and easily, but do users take advantage of the potential to customize? We conducted a three-week longitudinal study with 12 users to understand the familiarization and customization of generative AI tools for science communication. Our study revealed that the familiarization phase lasts for 4.3 sessions, where users explore the capabilities of the workflow and which aspects they find useful. After familiarization, the perceived utility of the system is rated higher than before, indicating that the perceived utility of AI is not just a novelty effect. The increase in benefits mainly comes from end-users' ability to customize prompts, and thus appropriate the system to their own needs. This points to a future where generative AI systems can allow us to design for appropriation.
PortfolioMentor: Multimodal Generative AI Companion for Learning and Crafting Interactive Digital Art Portfolios
Nov 23, 2023
Digital art portfolios serve as impactful mediums for artists to convey their visions, weaving together visuals, audio, interactions, and narratives. However, without technical backgrounds, design students often find it challenging to translate creative ideas into tangible codes and designs, given the lack of tailored resources for the non-technical, academic support in art schools, and a comprehensive guiding tool throughout the mentally demanding process. Recognizing the role of companionship in code learning and leveraging generative AI models' capabilities in supporting creative tasks, we present PortfolioMentor, a coding companion chatbot for IDEs. This tool guides and collaborates with students through proactive suggestions and responsible Q&As for learning, inspiration, and support. In detail, the system starts with the understanding of the task and artist's visions, follows the co-creation of visual illustrations, audio or music suggestions and files, click-scroll effects for interactions, and creative vision conceptualization, and finally synthesizes these facets into a polished interactive digital portfolio.
Challenges and Opportunities for the Design of Smart Speakers
Jun 09, 2023



Advances in voice technology and voice user interfaces (VUIs) -- such as Alexa, Siri, and Google Home -- have opened up the potential for many new types of interaction. However, despite the potential of these devices reflected by the growing market and body of VUI research, there is a lingering sense that the technology is still underused. In this paper, we conducted a systematic literature review of 35 papers to identify and synthesize 127 VUI design guidelines into five themes. Additionally, we conducted semi-structured interviews with 15 smart speaker users to understand their use and non-use of the technology. From the interviews, we distill four design challenges that contribute the most to non-use. Based on their (non-)use, we identify four opportunity spaces for designers to explore such as focusing on information support while multitasking (cooking, driving, childcare, etc), incorporating users' mental models for smart speakers, and integrating calm design principles.
Tweetorial Hooks: Generative AI Tools to Motivate Science on Social Media
May 20, 2023Communicating science and technology is essential for the public to understand and engage in a rapidly changing world. Tweetorials are an emerging phenomenon where experts explain STEM topics on social media in creative and engaging ways. However, STEM experts struggle to write an engaging "hook" in the first tweet that captures the reader's attention. We propose methods to use large language models (LLMs) to help users scaffold their process of writing a relatable hook for complex scientific topics. We demonstrate that LLMs can help writers find everyday experiences that are relatable and interesting to the public, avoid jargon, and spark curiosity. Our evaluation shows that the system reduces cognitive load and helps people write better hooks. Lastly, we discuss the importance of interactivity with LLMs to preserve the correctness, effectiveness, and authenticity of the writing.
ReelFramer: Co-creating News Reels on Social Media with Generative AI
Apr 19, 2023



Short videos on social media are a prime way many young people find and consume content. News outlets would like to reach audiences through news reels, but currently struggle to translate traditional journalistic formats into the short, entertaining videos that match the style of the platform. There are many ways to frame a reel-style narrative around a news story, and selecting one is a challenge. Different news stories call for different framings, and require a different trade-off between entertainment and information. We present a system called ReelFramer that uses text and image generation to help journalists explore multiple narrative framings for a story, then generate scripts, character boards and storyboards they can edit and iterate on. A user study of five graduate students in journalism-related fields found the system greatly eased the burden of transforming a written story into a reel, and that exploring framings to find the right one was a rewarding process.
Generative Disco: Text-to-Video Generation for Music Visualization
Apr 17, 2023Visuals are a core part of our experience of music, owing to the way they can amplify the emotions and messages conveyed through the music. However, creating music visualization is a complex, time-consuming, and resource-intensive process. We introduce Generative Disco, a generative AI system that helps generate music visualizations with large language models and text-to-image models. Users select intervals of music to visualize and then parameterize that visualization by defining start and end prompts. These prompts are warped between and generated according to the beat of the music for audioreactive video. We introduce design patterns for improving generated videos: "transitions", which express shifts in color, time, subject, or style, and "holds", which encourage visual emphasis and consistency. A study with professionals showed that the system was enjoyable, easy to explore, and highly expressive. We conclude on use cases of Generative Disco for professionals and how AI-generated content is changing the landscape of creative work.