 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBudget-Aware Anytime Reasoning with LLM-Synthesized Preference Data
Jan 16, 2026We study the reasoning behavior of large language models (LLMs) under limited computation budgets. In such settings, producing useful partial solutions quickly is often more practical than exhaustive reasoning, which incurs high inference costs. Many real-world tasks, such as trip planning, require models to deliver the best possible output within a fixed reasoning budget. We introduce an anytime reasoning framework and the Anytime Index, a metric that quantifies how effectively solution quality improves as reasoning tokens increase. To further enhance efficiency, we propose an inference-time self-improvement method using LLM-synthesized preference data, where models learn from their own reasoning comparisons to produce better intermediate solutions. Experiments on NaturalPlan (Trip), AIME, and GPQA datasets show consistent gains across Grok-3, GPT-oss, GPT-4.1/4o, and LLaMA models, improving both reasoning quality and efficiency under budget constraints.
Rewriting Video: Text-Driven Reauthoring of Video Footage
Jan 13, 2026Video is a powerful medium for communication and storytelling, yet reauthoring existing footage remains challenging. Even simple edits often demand expertise, time, and careful planning, constraining how creators envision and shape their narratives. Recent advances in generative AI suggest a new paradigm: what if editing a video were as straightforward as rewriting text? To investigate this, we present a tech probe and a study on text-driven video reauthoring. Our approach involves two technical contributions: (1) a generative reconstruction algorithm that reverse-engineers video into an editable text prompt, and (2) an interactive probe, Rewrite Kit, that allows creators to manipulate these prompts. A technical evaluation of the algorithm reveals a critical human-AI perceptual gap. A probe study with 12 creators surfaced novel use cases such as virtual reshooting, synthetic continuity, and aesthetic restyling. It also highlighted key tensions around coherence, control, and creative alignment in this new paradigm. Our work contributes empirical insights into the opportunities and challenges of text-driven video reauthoring, offering design implications for future co-creative video tools.
Facilitating Longitudinal Interaction Studies of AI Systems
Aug 14, 2025UIST researchers develop tools to address user challenges. However, user interactions with AI evolve over time through learning, adaptation, and repurposing, making one time evaluations insufficient. Capturing these dynamics requires longer-term studies, but challenges in deployment, evaluation design, and data collection have made such longitudinal research difficult to implement. Our workshop aims to tackle these challenges and prepare researchers with practical strategies for longitudinal studies. The workshop includes a keynote, panel discussions, and interactive breakout groups for discussion and hands-on protocol design and tool prototyping sessions. We seek to foster a community around longitudinal system research and promote it as a more embraced method for designing, building, and evaluating UIST tools.
AgentDynEx: Nudging the Mechanics and Dynamics of Multi-Agent Simulations
Apr 13, 2025


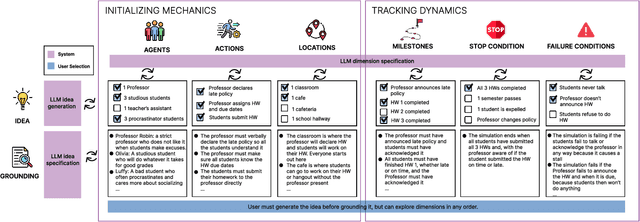
Multi-agent large language model simulations have the potential to model complex human behaviors and interactions. If the mechanics are set up properly, unanticipated and valuable social dynamics can surface. However, it is challenging to consistently enforce simulation mechanics while still allowing for notable and emergent dynamics. We present AgentDynEx, an AI system that helps set up simulations from user-specified mechanics and dynamics. AgentDynEx uses LLMs to guide users through a Configuration Matrix to identify core mechanics and define milestones to track dynamics. It also introduces a method called \textit{nudging}, where the system dynamically reflects on simulation progress and gently intervenes if it begins to deviate from intended outcomes. A technical evaluation found that nudging enables simulations to have more complex mechanics and maintain its notable dynamics compared to simulations without nudging. We discuss the importance of nudging as a technique for balancing mechanics and dynamics of multi-agent simulations.
STORYSUMM: Evaluating Faithfulness in Story Summarization
Jul 09, 2024
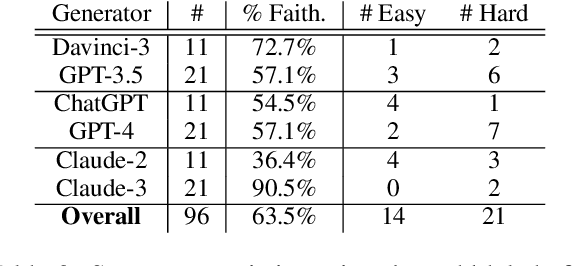

Human evaluation has been the gold standard for checking faithfulness in abstractive summarization. However, with a challenging source domain like narrative, multiple annotators can agree a summary is faithful, while missing details that are obvious errors only once pointed out. We therefore introduce a new dataset, STORYSUMM, comprising LLM summaries of short stories with localized faithfulness labels and error explanations. This benchmark is for evaluation methods, testing whether a given method can detect challenging inconsistencies. Using this dataset, we first show that any one human annotation protocol is likely to miss inconsistencies, and we advocate for pursuing a range of methods when establishing ground truth for a summarization dataset. We finally test recent automatic metrics and find that none of them achieve more than 70% balanced accuracy on this task, demonstrating that it is a challenging benchmark for future work in faithfulness evaluation.
Reading Subtext: Evaluating Large Language Models on Short Story Summarization with Writers
Mar 02, 2024We evaluate recent Large language Models (LLMs) on the challenging task of summarizing short stories, which can be lengthy, and include nuanced subtext or scrambled timelines. Importantly, we work directly with authors to ensure that the stories have not been shared online (and therefore are unseen by the models), and to obtain informed evaluations of summary quality using judgments from the authors themselves. Through quantitative and qualitative analysis grounded in narrative theory, we compare GPT-4, Claude-2.1, and LLama-2-70B. We find that all three models make faithfulness mistakes in over 50% of summaries and struggle to interpret difficult subtext. However, at their best, the models can provide thoughtful thematic analysis of stories. We additionally demonstrate that LLM judgments of summary quality do not match the feedback from the writers.
Not Just Novelty: A Longitudinal Study on Utility and Customization of AI Workflows
Feb 15, 2024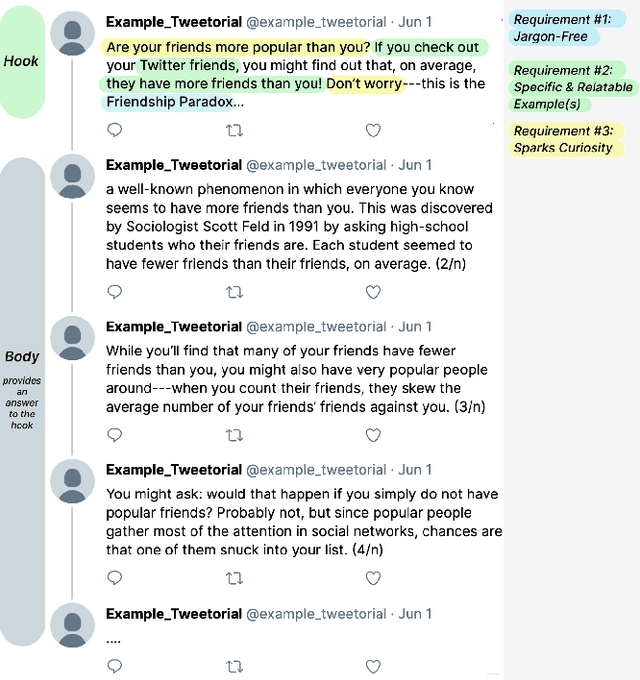
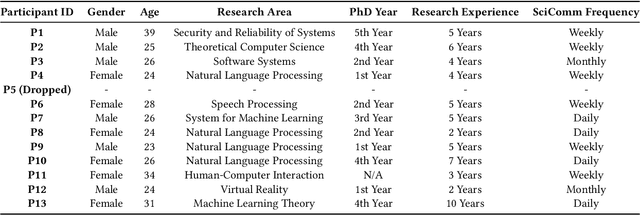

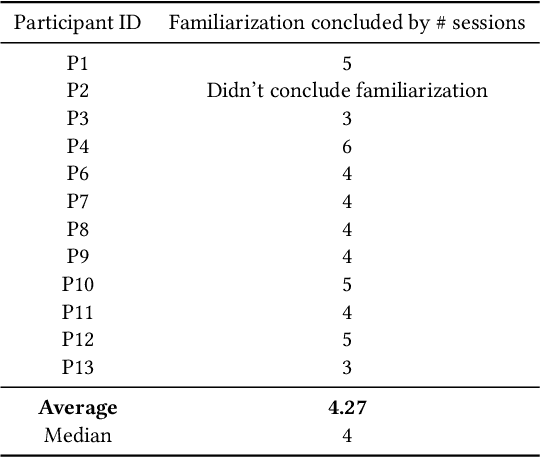
Generative AI brings novel and impressive abilities to help people in everyday tasks. There are many AI workflows that solve real and complex problems by chaining AI outputs together with human interaction. Although there is an undeniable lure of AI, it's uncertain how useful generative AI workflows are after the novelty wears off. Additionally, tools built with generative AI have the potential to be personalized and adapted quickly and easily, but do users take advantage of the potential to customize? We conducted a three-week longitudinal study with 12 users to understand the familiarization and customization of generative AI tools for science communication. Our study revealed that the familiarization phase lasts for 4.3 sessions, where users explore the capabilities of the workflow and which aspects they find useful. After familiarization, the perceived utility of the system is rated higher than before, indicating that the perceived utility of AI is not just a novelty effect. The increase in benefits mainly comes from end-users' ability to customize prompts, and thus appropriate the system to their own needs. This points to a future where generative AI systems can allow us to design for appropriation.
Challenges and Opportunities for the Design of Smart Speakers
Jun 09, 2023



Advances in voice technology and voice user interfaces (VUIs) -- such as Alexa, Siri, and Google Home -- have opened up the potential for many new types of interaction. However, despite the potential of these devices reflected by the growing market and body of VUI research, there is a lingering sense that the technology is still underused. In this paper, we conducted a systematic literature review of 35 papers to identify and synthesize 127 VUI design guidelines into five themes. Additionally, we conducted semi-structured interviews with 15 smart speaker users to understand their use and non-use of the technology. From the interviews, we distill four design challenges that contribute the most to non-use. Based on their (non-)use, we identify four opportunity spaces for designers to explore such as focusing on information support while multitasking (cooking, driving, childcare, etc), incorporating users' mental models for smart speakers, and integrating calm design principles.
Tweetorial Hooks: Generative AI Tools to Motivate Science on Social Media
May 20, 2023
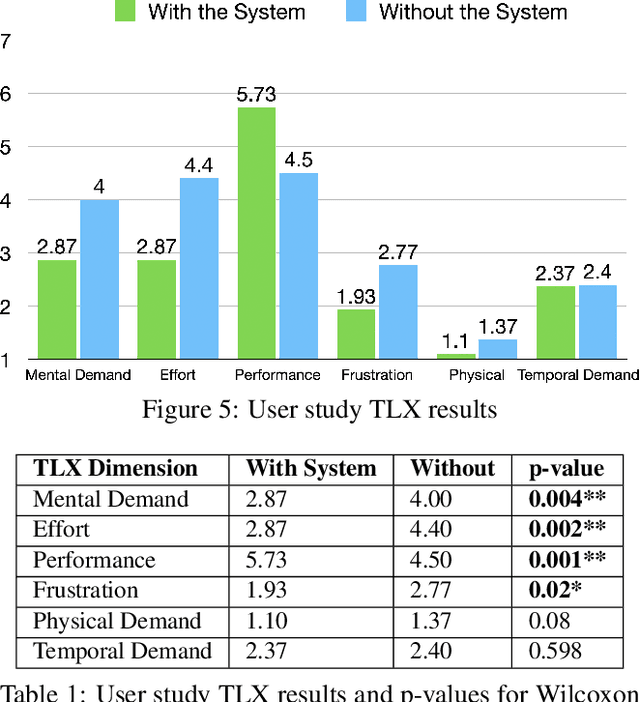


Communicating science and technology is essential for the public to understand and engage in a rapidly changing world. Tweetorials are an emerging phenomenon where experts explain STEM topics on social media in creative and engaging ways. However, STEM experts struggle to write an engaging "hook" in the first tweet that captures the reader's attention. We propose methods to use large language models (LLMs) to help users scaffold their process of writing a relatable hook for complex scientific topics. We demonstrate that LLMs can help writers find everyday experiences that are relatable and interesting to the public, avoid jargon, and spark curiosity. Our evaluation shows that the system reduces cognitive load and helps people write better hooks. Lastly, we discuss the importance of interactivity with LLMs to preserve the correctness, effectiveness, and authenticity of the writing.
ReelFramer: Co-creating News Reels on Social Media with Generative AI
Apr 19, 2023



Short videos on social media are a prime way many young people find and consume content. News outlets would like to reach audiences through news reels, but currently struggle to translate traditional journalistic formats into the short, entertaining videos that match the style of the platform. There are many ways to frame a reel-style narrative around a news story, and selecting one is a challenge. Different news stories call for different framings, and require a different trade-off between entertainment and information. We present a system called ReelFramer that uses text and image generation to help journalists explore multiple narrative framings for a story, then generate scripts, character boards and storyboards they can edit and iterate on. A user study of five graduate students in journalism-related fields found the system greatly eased the burden of transforming a written story into a reel, and that exploring framings to find the right one was a rewarding process.