 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference
Dec 19, 2024



Encoder-only transformer models such as BERT offer a great performance-size tradeoff for retrieval and classification tasks with respect to larger decoder-only models. Despite being the workhorse of numerous production pipelines, there have been limited Pareto improvements to BERT since its release. In this paper, we introduce ModernBERT, bringing modern model optimizations to encoder-only models and representing a major Pareto improvement over older encoders. Trained on 2 trillion tokens with a native 8192 sequence length, ModernBERT models exhibit state-of-the-art results on a large pool of evaluations encompassing diverse classification tasks and both single and multi-vector retrieval on different domains (including code). In addition to strong downstream performance, ModernBERT is also the most speed and memory efficient encoder and is designed for inference on common GPUs.
STORYSUMM: Evaluating Faithfulness in Story Summarization
Jul 09, 2024
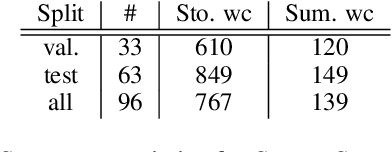
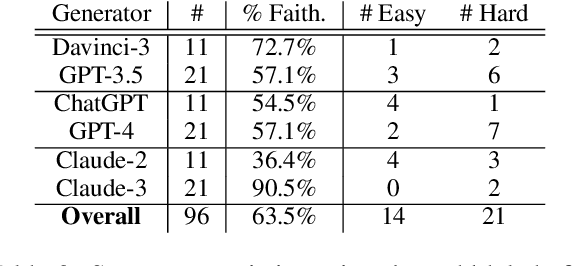

Human evaluation has been the gold standard for checking faithfulness in abstractive summarization. However, with a challenging source domain like narrative, multiple annotators can agree a summary is faithful, while missing details that are obvious errors only once pointed out. We therefore introduce a new dataset, STORYSUMM, comprising LLM summaries of short stories with localized faithfulness labels and error explanations. This benchmark is for evaluation methods, testing whether a given method can detect challenging inconsistencies. Using this dataset, we first show that any one human annotation protocol is likely to miss inconsistencies, and we advocate for pursuing a range of methods when establishing ground truth for a summarization dataset. We finally test recent automatic metrics and find that none of them achieve more than 70% balanced accuracy on this task, demonstrating that it is a challenging benchmark for future work in faithfulness evaluation.
Generating Faithful and Complete Hospital-Course Summaries from the Electronic Health Record
Apr 01, 2024



The rapid adoption of Electronic Health Records (EHRs) has been instrumental in streamlining administrative tasks, increasing transparency, and enabling continuity of care across providers. An unintended consequence of the increased documentation burden, however, has been reduced face-time with patients and, concomitantly, a dramatic rise in clinician burnout. In this thesis, we pinpoint a particularly time-intensive, yet critical, documentation task: generating a summary of a patient's hospital admissions, and propose and evaluate automated solutions. In Chapter 2, we construct a dataset based on 109,000 hospitalizations (2M source notes) and perform exploratory analyses to motivate future work on modeling and evaluation [NAACL 2021]. In Chapter 3, we address faithfulness from a modeling perspective by revising noisy references [EMNLP 2022] and, to reduce the reliance on references, directly calibrating model outputs to metrics [ACL 2023]. These works relied heavily on automatic metrics as human annotations were limited. To fill this gap, in Chapter 4, we conduct a fine-grained expert annotation of system errors in order to meta-evaluate existing metrics and better understand task-specific issues of domain adaptation and source-summary alignments. To learn a metric less correlated to extractiveness (copy-and-paste), we derive noisy faithfulness labels from an ensemble of existing metrics and train a faithfulness classifier on these pseudo labels [MLHC 2023]. Finally, in Chapter 5, we demonstrate that fine-tuned LLMs (Mistral and Zephyr) are highly prone to entity hallucinations and cover fewer salient entities. We improve both coverage and faithfulness by performing sentence-level entity planning based on a set of pre-computed salient entities from the source text, which extends our work on entity-guided news summarization [ACL, 2023], [EMNLP, 2023].
SPEER: Sentence-Level Planning of Long Clinical Summaries via Embedded Entity Retrieval
Jan 04, 2024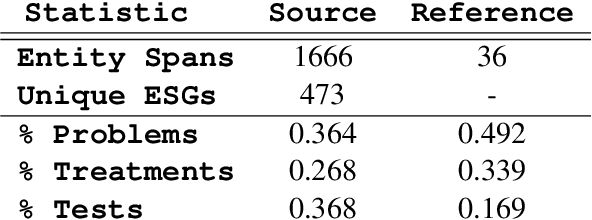

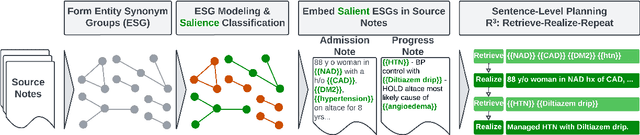

Clinician must write a lengthy summary each time a patient is discharged from the hospital. This task is time-consuming due to the sheer number of unique clinical concepts covered in the admission. Identifying and covering salient entities is vital for the summary to be clinically useful. We fine-tune open-source LLMs (Mistral-7B-Instruct and Zephyr-7B-\b{eta}) on the task and find that they generate incomplete and unfaithful summaries. To increase entity coverage, we train a smaller, encoder-only model to predict salient entities, which are treated as content-plans to guide the LLM. To encourage the LLM to focus on specific mentions in the source notes, we propose SPEER: Sentence-level Planning via Embedded Entity Retrieval. Specifically, we mark each salient entity span with special "{{ }}" boundary tags and instruct the LLM to retrieve marked spans before generating each sentence. Sentence-level planning acts as a form of state tracking in that the model is explicitly recording the entities it uses. We fine-tune Mistral and Zephyr variants on a large-scale, diverse dataset of ~167k in-patient hospital admissions and evaluate on 3 datasets. SPEER shows gains in both coverage and faithfulness metrics over non-guided and guided baselines.
From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting
Sep 08, 2023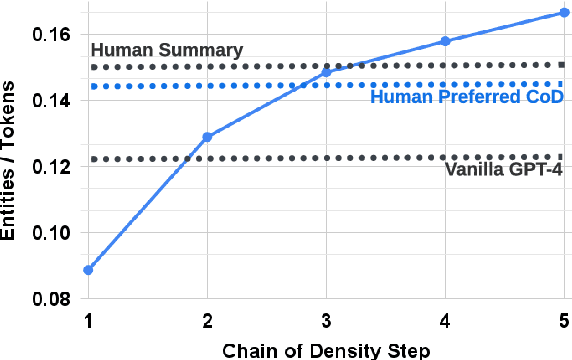



Selecting the ``right'' amount of information to include in a summary is a difficult task. A good summary should be detailed and entity-centric without being overly dense and hard to follow. To better understand this tradeoff, we solicit increasingly dense GPT-4 summaries with what we refer to as a ``Chain of Density'' (CoD) prompt. Specifically, GPT-4 generates an initial entity-sparse summary before iteratively incorporating missing salient entities without increasing the length. Summaries generated by CoD are more abstractive, exhibit more fusion, and have less of a lead bias than GPT-4 summaries generated by a vanilla prompt. We conduct a human preference study on 100 CNN DailyMail articles and find that that humans prefer GPT-4 summaries that are more dense than those generated by a vanilla prompt and almost as dense as human written summaries. Qualitative analysis supports the notion that there exists a tradeoff between informativeness and readability. 500 annotated CoD summaries, as well as an extra 5,000 unannotated summaries, are freely available on HuggingFace (https://huggingface.co/datasets/griffin/chain_of_density).
Generating EDU Extracts for Plan-Guided Summary Re-Ranking
May 28, 2023
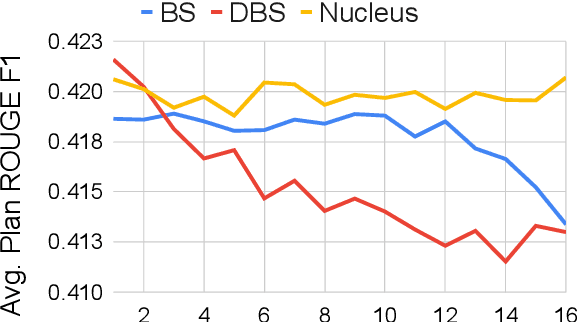
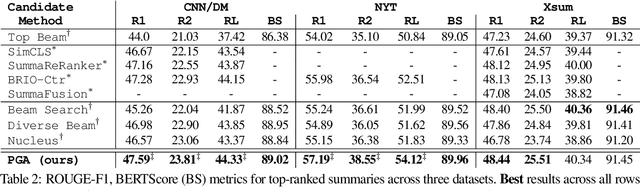
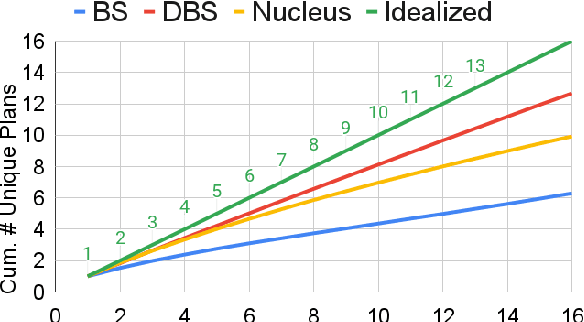
Two-step approaches, in which summary candidates are generated-then-reranked to return a single summary, can improve ROUGE scores over the standard single-step approach. Yet, standard decoding methods (i.e., beam search, nucleus sampling, and diverse beam search) produce candidates with redundant, and often low quality, content. In this paper, we design a novel method to generate candidates for re-ranking that addresses these issues. We ground each candidate abstract on its own unique content plan and generate distinct plan-guided abstracts using a model's top beam. More concretely, a standard language model (a BART LM) auto-regressively generates elemental discourse unit (EDU) content plans with an extractive copy mechanism. The top K beams from the content plan generator are then used to guide a separate LM, which produces a single abstractive candidate for each distinct plan. We apply an existing re-ranker (BRIO) to abstractive candidates generated from our method, as well as baseline decoding methods. We show large relevance improvements over previously published methods on widely used single document news article corpora, with ROUGE-2 F1 gains of 0.88, 2.01, and 0.38 on CNN / Dailymail, NYT, and Xsum, respectively. A human evaluation on CNN / DM validates these results. Similarly, on 1k samples from CNN / DM, we show that prompting GPT-3 to follow EDU plans outperforms sampling-based methods by 1.05 ROUGE-2 F1 points. Code to generate and realize plans is available at https://github.com/griff4692/edu-sum.
What are the Desired Characteristics of Calibration Sets? Identifying Correlates on Long Form Scientific Summarization
May 12, 2023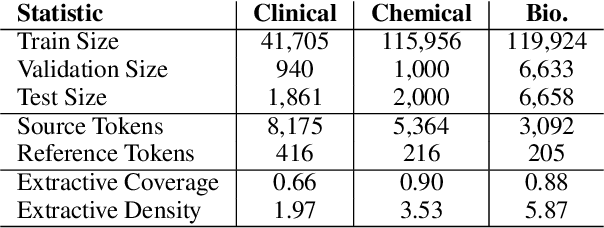
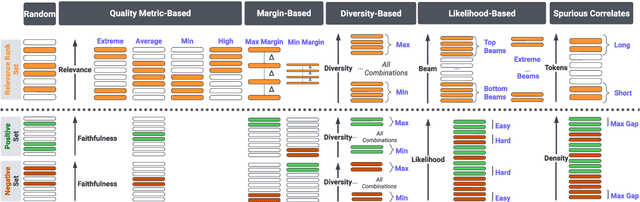
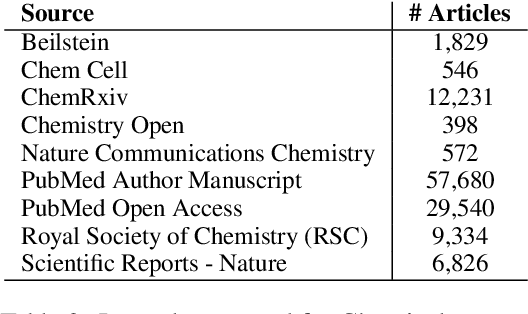
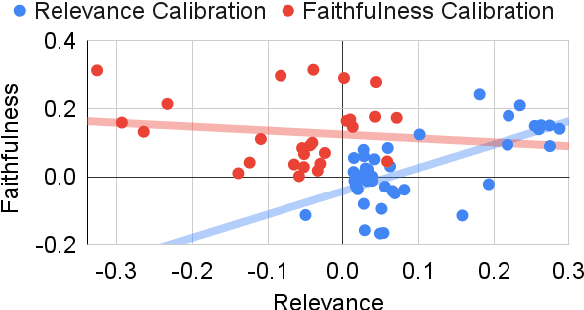
Summarization models often generate text that is poorly calibrated to quality metrics because they are trained to maximize the likelihood of a single reference (MLE). To address this, recent work has added a calibration step, which exposes a model to its own ranked outputs to improve relevance or, in a separate line of work, contrasts positive and negative sets to improve faithfulness. While effective, much of this work has focused on how to generate and optimize these sets. Less is known about why one setup is more effective than another. In this work, we uncover the underlying characteristics of effective sets. For each training instance, we form a large, diverse pool of candidates and systematically vary the subsets used for calibration fine-tuning. Each selection strategy targets distinct aspects of the sets, such as lexical diversity or the size of the gap between positive and negatives. On three diverse scientific long-form summarization datasets (spanning biomedical, clinical, and chemical domains), we find, among others, that faithfulness calibration is optimal when the negative sets are extractive and more likely to be generated, whereas for relevance calibration, the metric margin between candidates should be maximized and surprise--the disagreement between model and metric defined candidate rankings--minimized. Code to create, select, and optimize calibration sets is available at https://github.com/griff4692/calibrating-summaries
A Meta-Evaluation of Faithfulness Metrics for Long-Form Hospital-Course Summarization
Mar 07, 2023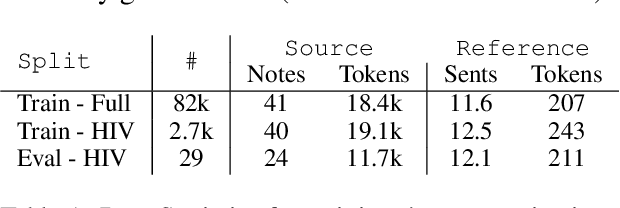
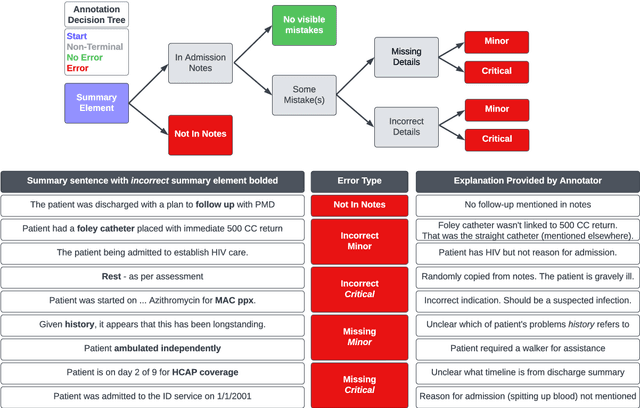
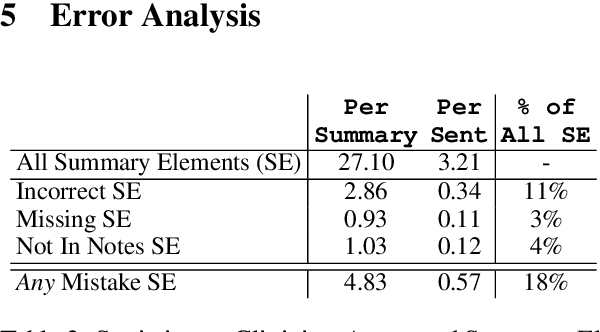
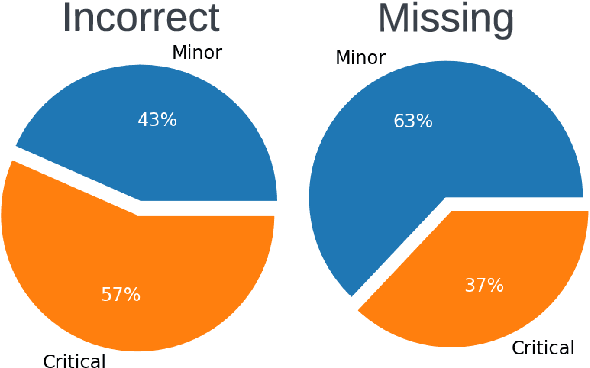
Long-form clinical summarization of hospital admissions has real-world significance because of its potential to help both clinicians and patients. The faithfulness of summaries is critical to their safe usage in clinical settings. To better understand the limitations of abstractive systems, as well as the suitability of existing evaluation metrics, we benchmark faithfulness metrics against fine-grained human annotations for model-generated summaries of a patient's Brief Hospital Course. We create a corpus of patient hospital admissions and summaries for a cohort of HIV patients, each with complex medical histories. Annotators are presented with summaries and source notes, and asked to categorize manually highlighted summary elements (clinical entities like conditions and medications as well as actions like "following up") into one of three categories: ``Incorrect,'' ``Missing,'' and ``Not in Notes.'' We meta-evaluate a broad set of proposed faithfulness metrics and, across metrics, explore the importance of domain adaptation (e.g. the impact of in-domain pre-training and metric fine-tuning), the use of source-summary alignments, and the effects of distilling a single metric from an ensemble of pre-existing metrics. Off-the-shelf metrics with no exposure to clinical text correlate well yet overly rely on summary extractiveness. As a practical guide to long-form clinical narrative summarization, we find that most metrics correlate best to human judgments when provided with one summary sentence at a time and a minimal set of relevant source context.
Learning to Revise References for Faithful Summarization
Apr 13, 2022
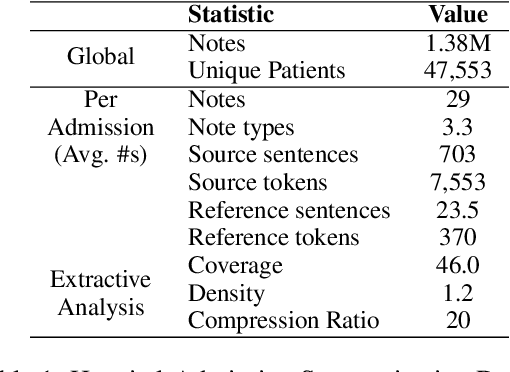
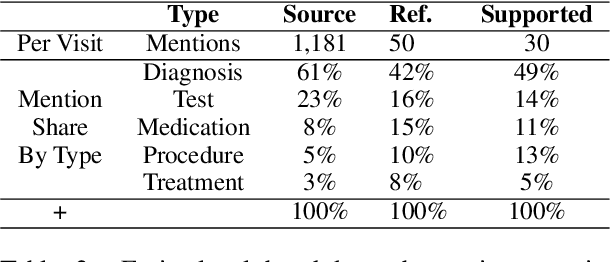

In many real-world scenarios with naturally occurring datasets, reference summaries are noisy and contain information that cannot be inferred from the source text. On large news corpora, removing low quality samples has been shown to reduce model hallucinations. Yet, this method is largely untested for smaller, noisier corpora. To improve reference quality while retaining all data, we propose a new approach: to revise--not remove--unsupported reference content. Without ground-truth supervision, we construct synthetic unsupported alternatives to supported sentences and use contrastive learning to discourage/encourage (un)faithful revisions. At inference, we vary style codes to over-generate revisions of unsupported reference sentences and select a final revision which balances faithfulness and abstraction. We extract a small corpus from a noisy source--the Electronic Health Record (EHR)--for the task of summarizing a hospital admission from multiple notes. Training models on original, filtered, and revised references, we find (1) learning from revised references reduces the hallucination rate substantially more than filtering (18.4\% vs 3.8\%), (2) learning from abstractive (vs extractive) revisions improves coherence, relevance, and faithfulness, (3) beyond redress of noisy data, the revision task has standalone value for the task: as a pre-training objective and as a post-hoc editor.