 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity Anchored ICD Coding
Aug 15, 2022
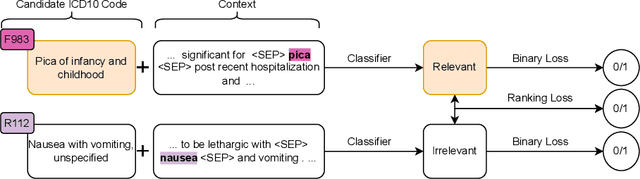

Medical coding is a complex task, requiring assignment of a subset of over 72,000 ICD codes to a patient's notes. Modern natural language processing approaches to these tasks have been challenged by the length of the input and size of the output space. We limit our model inputs to a small window around medical entities found in our documents. From those local contexts, we build contextualized representations of both ICD codes and entities, and aggregate over these representations to form document-level predictions. In contrast to existing methods which use a representation fixed either in size or by codes seen in training, we represent ICD codes by encoding the code description with local context. We discuss metrics appropriate to deploying coding systems in practice. We show that our approach is superior to existing methods in both standard and deployable measures, including performance on rare and unseen codes.
Learning to Revise References for Faithful Summarization
Apr 13, 2022
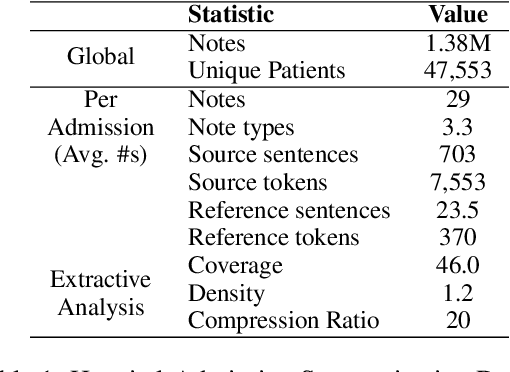
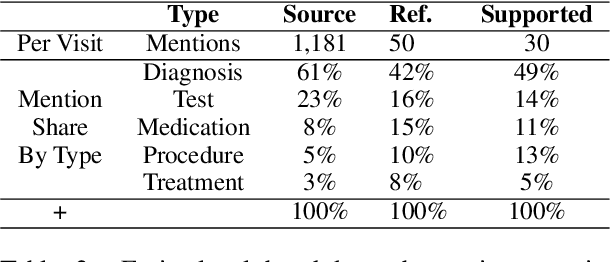

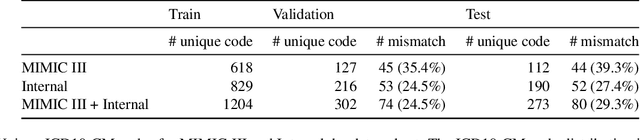
In many real-world scenarios with naturally occurring datasets, reference summaries are noisy and contain information that cannot be inferred from the source text. On large news corpora, removing low quality samples has been shown to reduce model hallucinations. Yet, this method is largely untested for smaller, noisier corpora. To improve reference quality while retaining all data, we propose a new approach: to revise--not remove--unsupported reference content. Without ground-truth supervision, we construct synthetic unsupported alternatives to supported sentences and use contrastive learning to discourage/encourage (un)faithful revisions. At inference, we vary style codes to over-generate revisions of unsupported reference sentences and select a final revision which balances faithfulness and abstraction. We extract a small corpus from a noisy source--the Electronic Health Record (EHR)--for the task of summarizing a hospital admission from multiple notes. Training models on original, filtered, and revised references, we find (1) learning from revised references reduces the hallucination rate substantially more than filtering (18.4\% vs 3.8\%), (2) learning from abstractive (vs extractive) revisions improves coherence, relevance, and faithfulness, (3) beyond redress of noisy data, the revision task has standalone value for the task: as a pre-training objective and as a post-hoc editor.
Towards Clinical Encounter Summarization: Learning to Compose Discharge Summaries from Prior Notes
Apr 27, 2021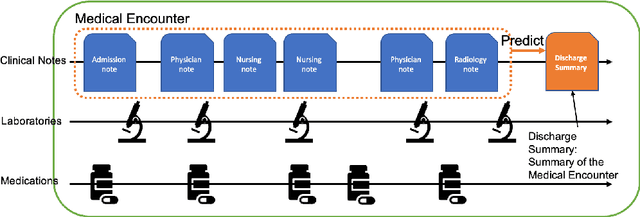

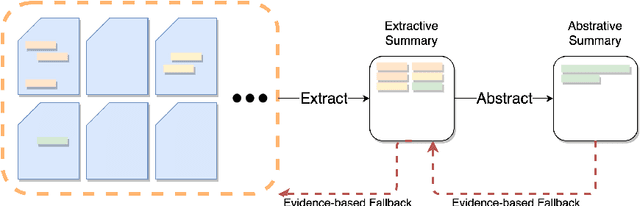
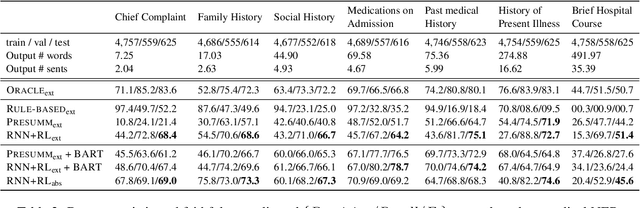
The records of a clinical encounter can be extensive and complex, thus placing a premium on tools that can extract and summarize relevant information. This paper introduces the task of generating discharge summaries for a clinical encounter. Summaries in this setting need to be faithful, traceable, and scale to multiple long documents, motivating the use of extract-then-abstract summarization cascades. We introduce two new measures, faithfulness and hallucination rate for evaluation in this task, which complement existing measures for fluency and informativeness. Results across seven medical sections and five models show that a summarization architecture that supports traceability yields promising results, and that a sentence-rewriting approach performs consistently on the measure used for faithfulness (faithfulness-adjusted $F_3$) over a diverse range of generated sections.
Assigning Medical Codes at the Encounter Level by Paying Attention to Documents
Nov 15, 2019


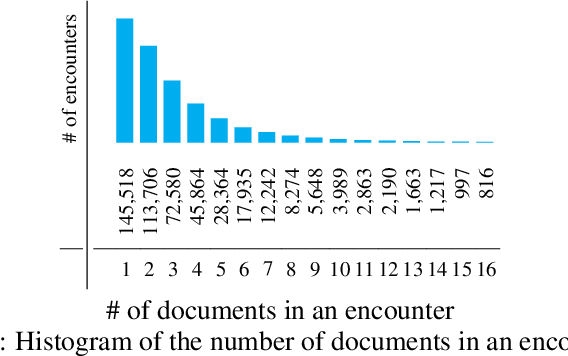
The vast majority of research in computer assisted medical coding focuses on coding at the document level, but a substantial proportion of medical coding in the real world involves coding at the level of clinical encounters, each of which is typically represented by a potentially large set of documents. We introduce encounter-level document attention networks, which use hierarchical attention to explicitly take the hierarchical structure of encounter documentation into account. Experimental evaluation demonstrates improvements in coding accuracy as well as facilitation of human reviewers in their ability to identify which documents within an encounter play a role in determining the encounter level codes.