 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity Anchored ICD Coding
Aug 15, 2022
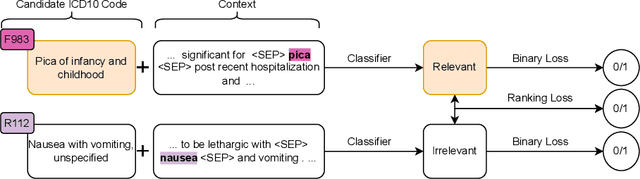
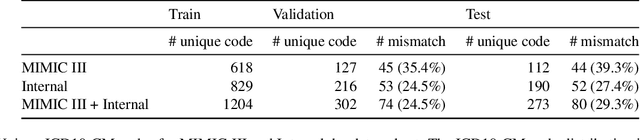

Medical coding is a complex task, requiring assignment of a subset of over 72,000 ICD codes to a patient's notes. Modern natural language processing approaches to these tasks have been challenged by the length of the input and size of the output space. We limit our model inputs to a small window around medical entities found in our documents. From those local contexts, we build contextualized representations of both ICD codes and entities, and aggregate over these representations to form document-level predictions. In contrast to existing methods which use a representation fixed either in size or by codes seen in training, we represent ICD codes by encoding the code description with local context. We discuss metrics appropriate to deploying coding systems in practice. We show that our approach is superior to existing methods in both standard and deployable measures, including performance on rare and unseen codes.
Learning to Revise References for Faithful Summarization
Apr 13, 2022
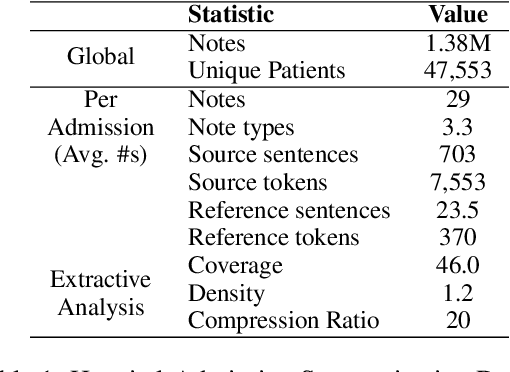
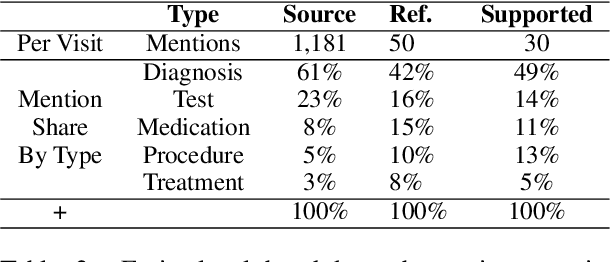

In many real-world scenarios with naturally occurring datasets, reference summaries are noisy and contain information that cannot be inferred from the source text. On large news corpora, removing low quality samples has been shown to reduce model hallucinations. Yet, this method is largely untested for smaller, noisier corpora. To improve reference quality while retaining all data, we propose a new approach: to revise--not remove--unsupported reference content. Without ground-truth supervision, we construct synthetic unsupported alternatives to supported sentences and use contrastive learning to discourage/encourage (un)faithful revisions. At inference, we vary style codes to over-generate revisions of unsupported reference sentences and select a final revision which balances faithfulness and abstraction. We extract a small corpus from a noisy source--the Electronic Health Record (EHR)--for the task of summarizing a hospital admission from multiple notes. Training models on original, filtered, and revised references, we find (1) learning from revised references reduces the hallucination rate substantially more than filtering (18.4\% vs 3.8\%), (2) learning from abstractive (vs extractive) revisions improves coherence, relevance, and faithfulness, (3) beyond redress of noisy data, the revision task has standalone value for the task: as a pre-training objective and as a post-hoc editor.
Zero-shot Medical Entity Retrieval without Annotation: Learning From Rich Knowledge Graph Semantics
May 26, 2021
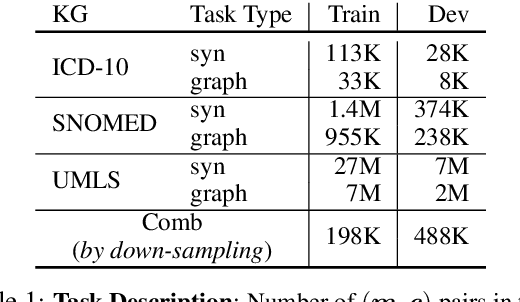
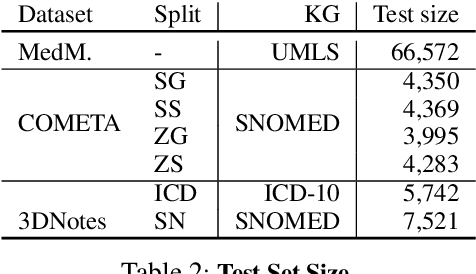
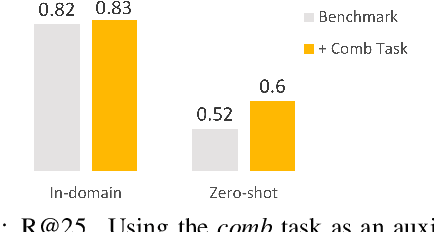
Medical entity retrieval is an integral component for understanding and communicating information across various health systems. Current approaches tend to work well on specific medical domains but generalize poorly to unseen sub-specialties. This is of increasing concern under a public health crisis as new medical conditions and drug treatments come to light frequently. Zero-shot retrieval is challenging due to the high degree of ambiguity and variability in medical corpora, making it difficult to build an accurate similarity measure between mentions and concepts. Medical knowledge graphs (KG), however, contain rich semantics including large numbers of synonyms as well as its curated graphical structures. To take advantage of this valuable information, we propose a suite of learning tasks designed for training efficient zero-shot entity retrieval models. Without requiring any human annotation, our knowledge graph enriched architecture significantly outperforms common zero-shot benchmarks including BM25 and Clinical BERT with 7% to 30% higher recall across multiple major medical ontologies, such as UMLS, SNOMED, and ICD-10.
Direct optimization of F-measure for retrieval-based personal question answering
Sep 28, 2018

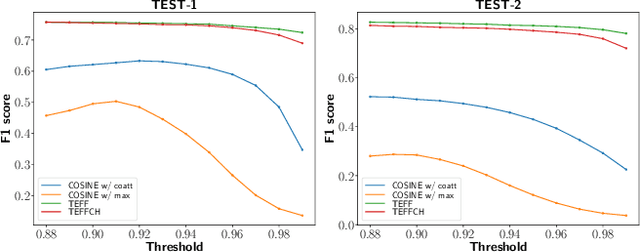
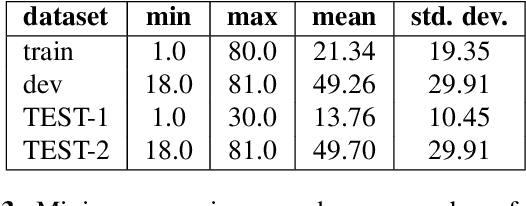
Recent advances in spoken language technologies and the introduction of many customer facing products, have given rise to a wide customer reliance on smart personal assistants for many of their daily tasks. In this paper, we present a system to reduce users' cognitive load by extending personal assistants with long-term personal memory where users can store and retrieve by voice, arbitrary pieces of information. The problem is framed as a neural retrieval based question answering system where answers are selected from previously stored user memories. We propose to directly optimize the end-to-end retrieval performance, measured by the F1-score, using reinforcement learning, leading to better performance on our experimental test set(s).