 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Greedy Networks
Oct 30, 2018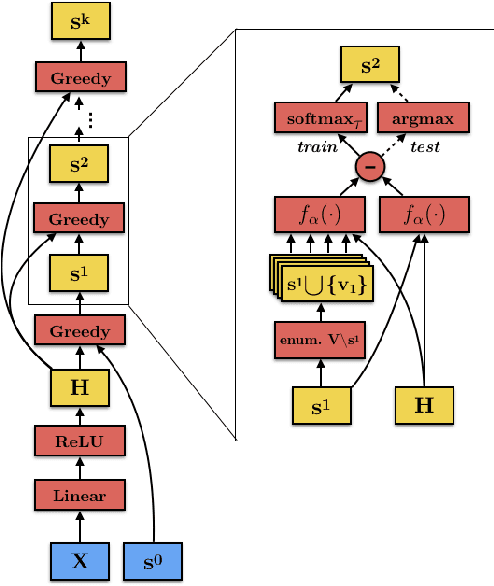
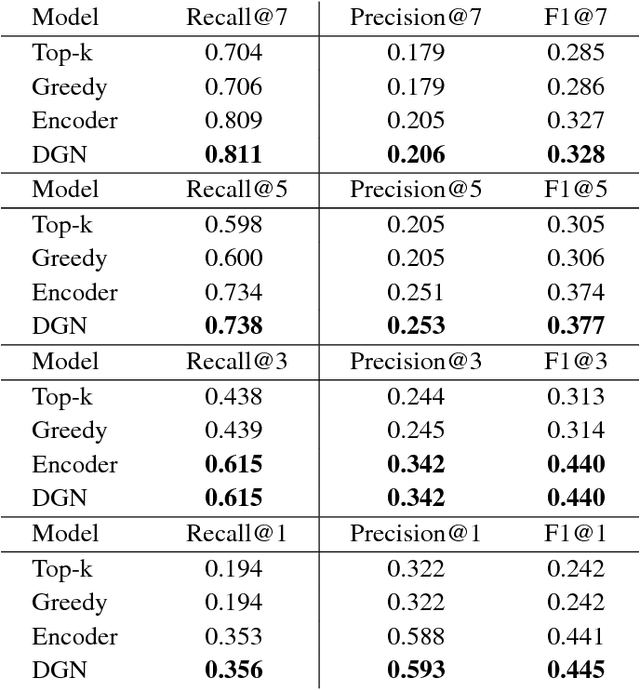
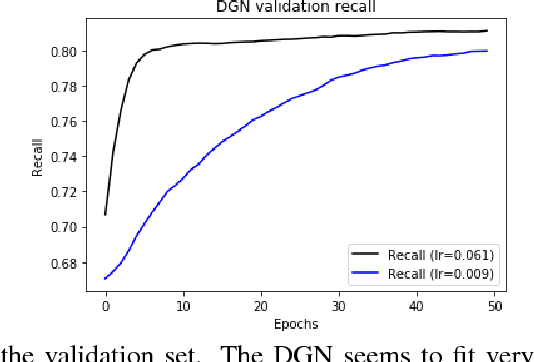

Optimal selection of a subset of items from a given set is a hard problem that requires combinatorial optimization. In this paper, we propose a subset selection algorithm that is trainable with gradient-based methods yet achieves near-optimal performance via submodular optimization. We focus on the task of identifying a relevant set of sentences for claim verification in the context of the FEVER task. Conventional methods for this task look at sentences on their individual merit and thus do not optimize the informativeness of sentences as a set. We show that our proposed method which builds on the idea of unfolding a greedy algorithm into a computational graph allows both interpretability and gradient-based training. The proposed differentiable greedy network (DGN) outperforms discrete optimization algorithms as well as other baseline methods in terms of precision and recall.
Direct optimization of F-measure for retrieval-based personal question answering
Sep 28, 2018

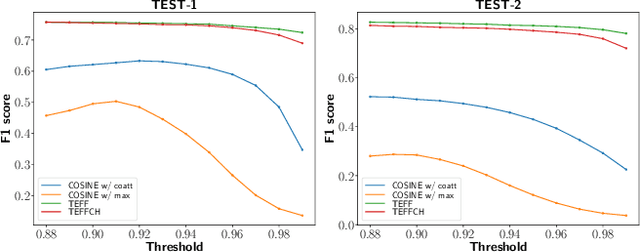
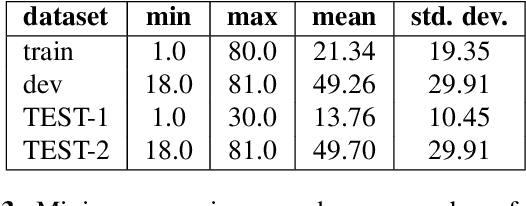
Recent advances in spoken language technologies and the introduction of many customer facing products, have given rise to a wide customer reliance on smart personal assistants for many of their daily tasks. In this paper, we present a system to reduce users' cognitive load by extending personal assistants with long-term personal memory where users can store and retrieve by voice, arbitrary pieces of information. The problem is framed as a neural retrieval based question answering system where answers are selected from previously stored user memories. We propose to directly optimize the end-to-end retrieval performance, measured by the F1-score, using reinforcement learning, leading to better performance on our experimental test set(s).
Memory-augmented Attention Modelling for Videos
Apr 24, 2017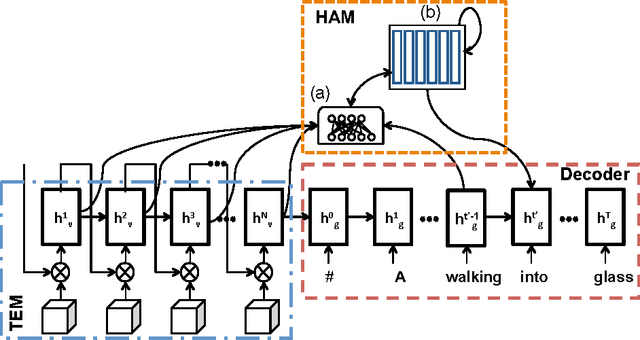
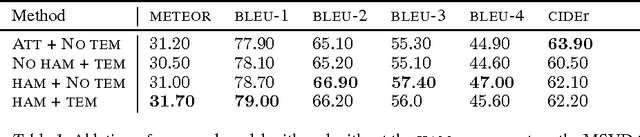


We present a method to improve video description generation by modeling higher-order interactions between video frames and described concepts. By storing past visual attention in the video associated to previously generated words, the system is able to decide what to look at and describe in light of what it has already looked at and described. This enables not only more effective local attention, but tractable consideration of the video sequence while generating each word. Evaluation on the challenging and popular MSVD and Charades datasets demonstrates that the proposed architecture outperforms previous video description approaches without requiring external temporal video features.
Deep API Programmer: Learning to Program with APIs
Apr 14, 2017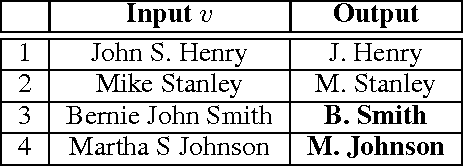


We present DAPIP, a Programming-By-Example system that learns to program with APIs to perform data transformation tasks. We design a domain-specific language (DSL) that allows for arbitrary concatenations of API outputs and constant strings. The DSL consists of three family of APIs: regular expression-based APIs, lookup APIs, and transformation APIs. We then present a novel neural synthesis algorithm to search for programs in the DSL that are consistent with a given set of examples. The search algorithm uses recently introduced neural architectures to encode input-output examples and to model the program search in the DSL. We show that synthesis algorithm outperforms baseline methods for synthesizing programs on both synthetic and real-world benchmarks.
RobustFill: Neural Program Learning under Noisy I/O
Mar 21, 2017

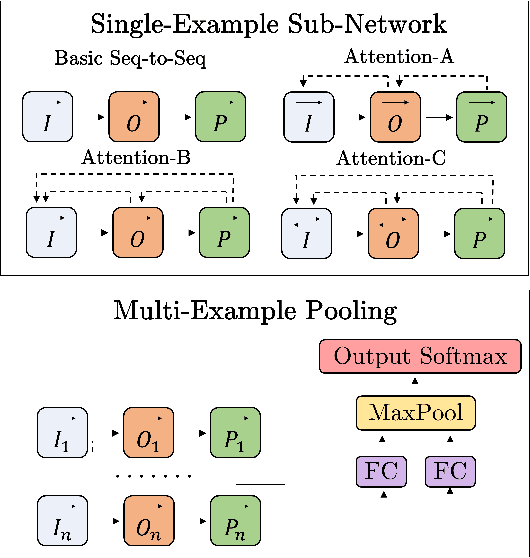
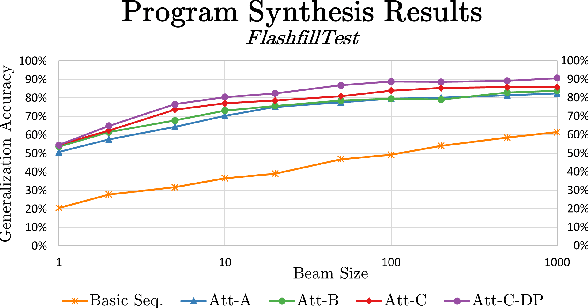
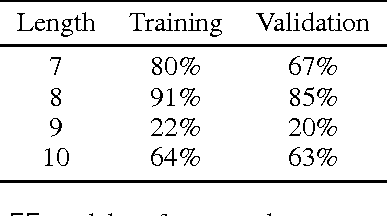
The problem of automatically generating a computer program from some specification has been studied since the early days of AI. Recently, two competing approaches for automatic program learning have received significant attention: (1) neural program synthesis, where a neural network is conditioned on input/output (I/O) examples and learns to generate a program, and (2) neural program induction, where a neural network generates new outputs directly using a latent program representation. Here, for the first time, we directly compare both approaches on a large-scale, real-world learning task. We additionally contrast to rule-based program synthesis, which uses hand-crafted semantics to guide the program generation. Our neural models use a modified attention RNN to allow encoding of variable-sized sets of I/O pairs. Our best synthesis model achieves 92% accuracy on a real-world test set, compared to the 34% accuracy of the previous best neural synthesis approach. The synthesis model also outperforms a comparable induction model on this task, but we more importantly demonstrate that the strength of each approach is highly dependent on the evaluation metric and end-user application. Finally, we show that we can train our neural models to remain very robust to the type of noise expected in real-world data (e.g., typos), while a highly-engineered rule-based system fails entirely.
Neuro-Symbolic Program Synthesis
Nov 06, 2016
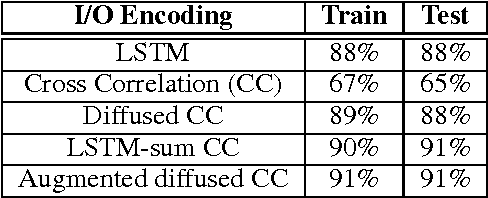
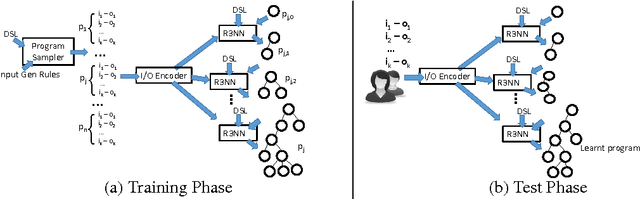
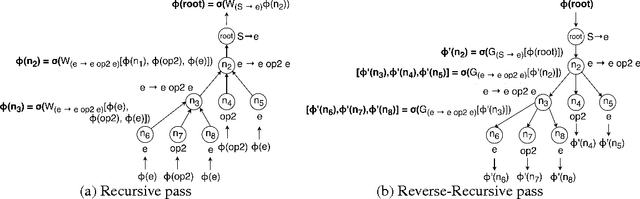
Recent years have seen the proposal of a number of neural architectures for the problem of Program Induction. Given a set of input-output examples, these architectures are able to learn mappings that generalize to new test inputs. While achieving impressive results, these approaches have a number of important limitations: (a) they are computationally expensive and hard to train, (b) a model has to be trained for each task (program) separately, and (c) it is hard to interpret or verify the correctness of the learnt mapping (as it is defined by a neural network). In this paper, we propose a novel technique, Neuro-Symbolic Program Synthesis, to overcome the above-mentioned problems. Once trained, our approach can automatically construct computer programs in a domain-specific language that are consistent with a set of input-output examples provided at test time. Our method is based on two novel neural modules. The first module, called the cross correlation I/O network, given a set of input-output examples, produces a continuous representation of the set of I/O examples. The second module, the Recursive-Reverse-Recursive Neural Network (R3NN), given the continuous representation of the examples, synthesizes a program by incrementally expanding partial programs. We demonstrate the effectiveness of our approach by applying it to the rich and complex domain of regular expression based string transformations. Experiments show that the R3NN model is not only able to construct programs from new input-output examples, but it is also able to construct new programs for tasks that it had never observed before during training.
Blending LSTMs into CNNs
Sep 14, 2016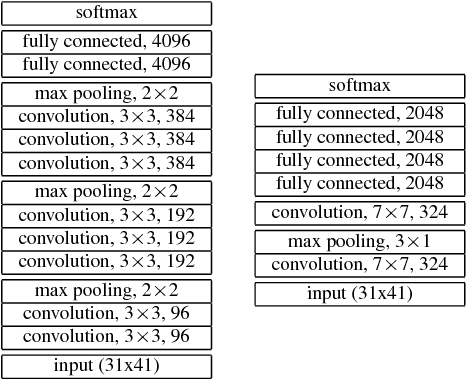
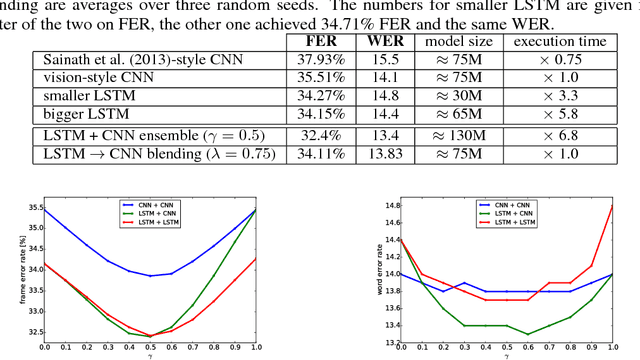

We consider whether deep convolutional networks (CNNs) can represent decision functions with similar accuracy as recurrent networks such as LSTMs. First, we show that a deep CNN with an architecture inspired by the models recently introduced in image recognition can yield better accuracy than previous convolutional and LSTM networks on the standard 309h Switchboard automatic speech recognition task. Then we show that even more accurate CNNs can be trained under the guidance of LSTMs using a variant of model compression, which we call model blending because the teacher and student models are similar in complexity but different in inductive bias. Blending further improves the accuracy of our CNN, yielding a computationally efficient model of accuracy higher than any of the other individual models. Examining the effect of "dark knowledge" in this model compression task, we find that less than 1% of the highest probability labels are needed for accurate model compression.
Improvements to deep convolutional neural networks for LVCSR
Dec 10, 2013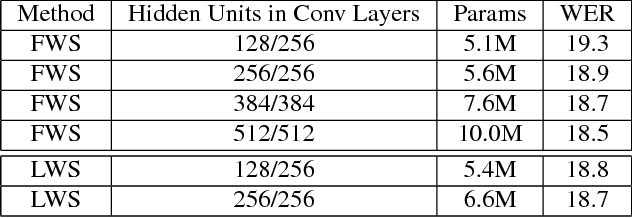

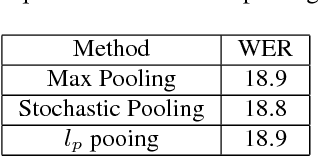

Deep Convolutional Neural Networks (CNNs) are more powerful than Deep Neural Networks (DNN), as they are able to better reduce spectral variation in the input signal. This has also been confirmed experimentally, with CNNs showing improvements in word error rate (WER) between 4-12% relative compared to DNNs across a variety of LVCSR tasks. In this paper, we describe different methods to further improve CNN performance. First, we conduct a deep analysis comparing limited weight sharing and full weight sharing with state-of-the-art features. Second, we apply various pooling strategies that have shown improvements in computer vision to an LVCSR speech task. Third, we introduce a method to effectively incorporate speaker adaptation, namely fMLLR, into log-mel features. Fourth, we introduce an effective strategy to use dropout during Hessian-free sequence training. We find that with these improvements, particularly with fMLLR and dropout, we are able to achieve an additional 2-3% relative improvement in WER on a 50-hour Broadcast News task over our previous best CNN baseline. On a larger 400-hour BN task, we find an additional 4-5% relative improvement over our previous best CNN baseline.
Speech Recognition with Deep Recurrent Neural Networks
Mar 22, 2013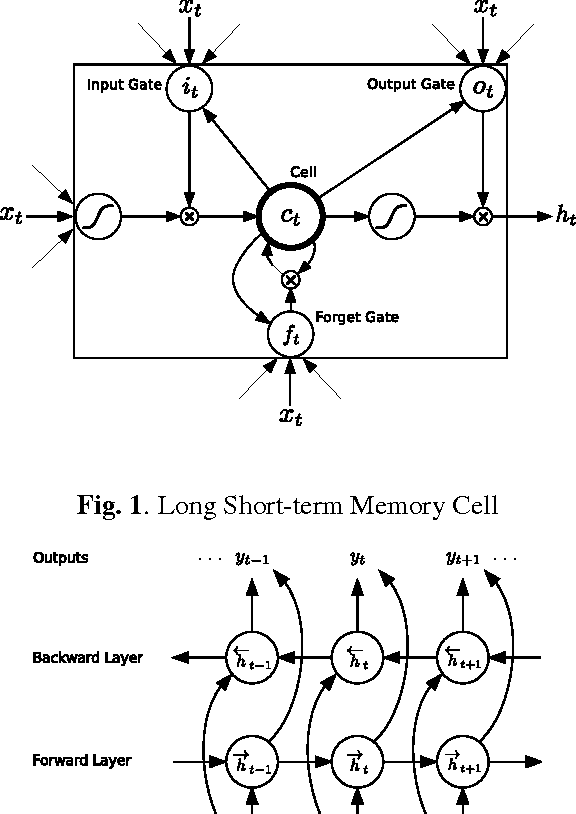

Recurrent neural networks (RNNs) are a powerful model for sequential data. End-to-end training methods such as Connectionist Temporal Classification make it possible to train RNNs for sequence labelling problems where the input-output alignment is unknown. The combination of these methods with the Long Short-term Memory RNN architecture has proved particularly fruitful, delivering state-of-the-art results in cursive handwriting recognition. However RNN performance in speech recognition has so far been disappointing, with better results returned by deep feedforward networks. This paper investigates \emph{deep recurrent neural networks}, which combine the multiple levels of representation that have proved so effective in deep networks with the flexible use of long range context that empowers RNNs. When trained end-to-end with suitable regularisation, we find that deep Long Short-term Memory RNNs achieve a test set error of 17.7% on the TIMIT phoneme recognition benchmark, which to our knowledge is the best recorded score.