 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Flow Networks
Aug 14, 2023



This paper introduces Bayesian Flow Networks (BFNs), a new class of generative model in which the parameters of a set of independent distributions are modified with Bayesian inference in the light of noisy data samples, then passed as input to a neural network that outputs a second, interdependent distribution. Starting from a simple prior and iteratively updating the two distributions yields a generative procedure similar to the reverse process of diffusion models; however it is conceptually simpler in that no forward process is required. Discrete and continuous-time loss functions are derived for continuous, discretised and discrete data, along with sample generation procedures. Notably, the network inputs for discrete data lie on the probability simplex, and are therefore natively differentiable, paving the way for gradient-based sample guidance and few-step generation in discrete domains such as language modelling. The loss function directly optimises data compression and places no restrictions on the network architecture. In our experiments BFNs achieve competitive log-likelihoods for image modelling on dynamically binarized MNIST and CIFAR-10, and outperform all known discrete diffusion models on the text8 character-level language modelling task.
A Practical Sparse Approximation for Real Time Recurrent Learning
Jun 12, 2020
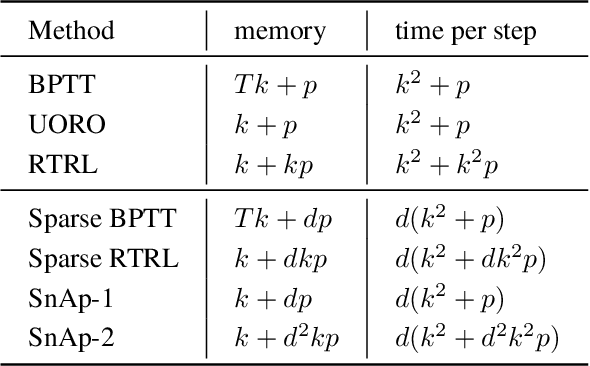
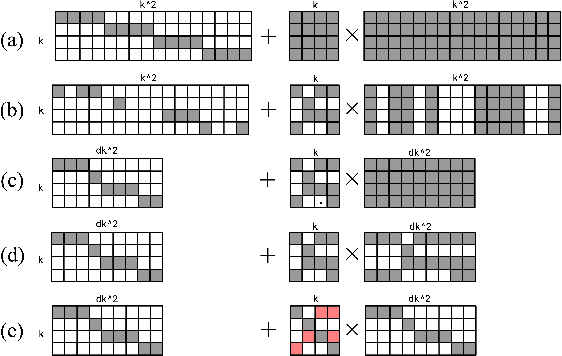

Current methods for training recurrent neural networks are based on backpropagation through time, which requires storing a complete history of network states, and prohibits updating the weights `online' (after every timestep). Real Time Recurrent Learning (RTRL) eliminates the need for history storage and allows for online weight updates, but does so at the expense of computational costs that are quartic in the state size. This renders RTRL training intractable for all but the smallest networks, even ones that are made highly sparse. We introduce the Sparse n-step Approximation (SnAp) to the RTRL influence matrix, which only keeps entries that are nonzero within n steps of the recurrent core. SnAp with n=1 is no more expensive than backpropagation, and we find that it substantially outperforms other RTRL approximations with comparable costs such as Unbiased Online Recurrent Optimization. For highly sparse networks, SnAp with n=2 remains tractable and can outperform backpropagation through time in terms of learning speed when updates are done online. SnAp becomes equivalent to RTRL when n is large.
The Kanerva Machine: A Generative Distributed Memory
Jun 18, 2018
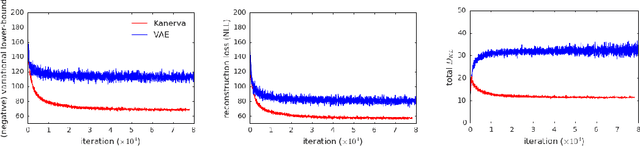


We present an end-to-end trained memory system that quickly adapts to new data and generates samples like them. Inspired by Kanerva's sparse distributed memory, it has a robust distributed reading and writing mechanism. The memory is analytically tractable, which enables optimal on-line compression via a Bayesian update-rule. We formulate it as a hierarchical conditional generative model, where memory provides a rich data-dependent prior distribution. Consequently, the top-down memory and bottom-up perception are combined to produce the code representing an observation. Empirically, we demonstrate that the adaptive memory significantly improves generative models trained on both the Omniglot and CIFAR datasets. Compared with the Differentiable Neural Computer (DNC) and its variants, our memory model has greater capacity and is significantly easier to train.
Associative Compression Networks for Representation Learning
Apr 26, 2018
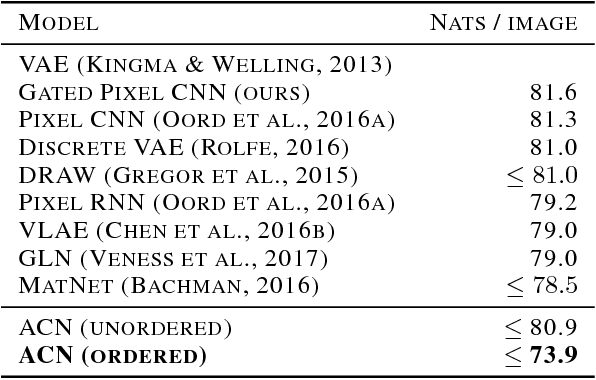

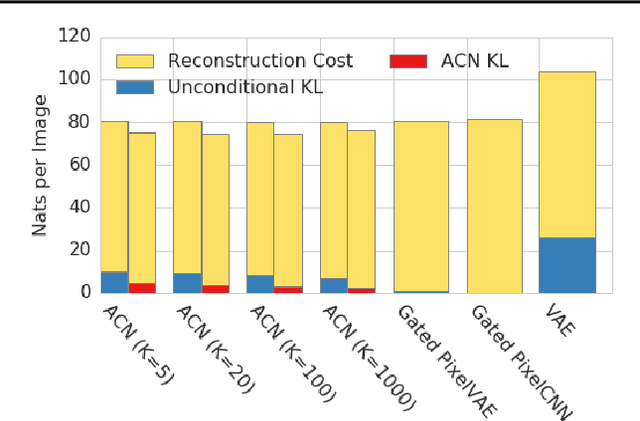
This paper introduces Associative Compression Networks (ACNs), a new framework for variational autoencoding with neural networks. The system differs from existing variational autoencoders (VAEs) in that the prior distribution used to model each code is conditioned on a similar code from the dataset. In compression terms this equates to sequentially transmitting the dataset using an ordering determined by proximity in latent space. Since the prior need only account for local, rather than global variations in the latent space, the coding cost is greatly reduced, leading to rich, informative codes. Crucially, the codes remain informative when powerful, autoregressive decoders are used, which we argue is fundamentally difficult with normal VAEs. Experimental results on MNIST, CIFAR-10, ImageNet and CelebA show that ACNs discover high-level latent features such as object class, writing style, pose and facial expression, which can be used to cluster and classify the data, as well as to generate diverse and convincing samples. We conclude that ACNs are a promising new direction for representation learning: one that steps away from IID modelling, and towards learning a structured description of the dataset as a whole.
Noisy Networks for Exploration
Feb 15, 2018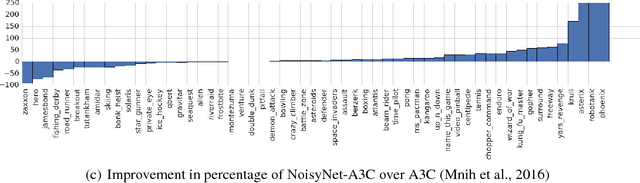
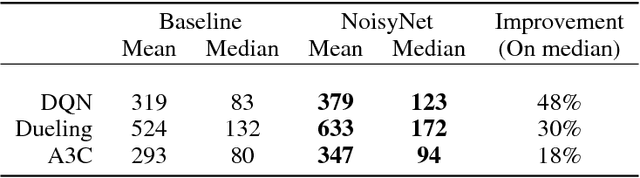
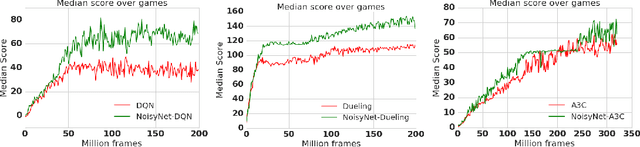
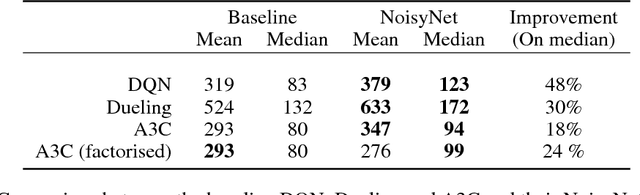
We introduce NoisyNet, a deep reinforcement learning agent with parametric noise added to its weights, and show that the induced stochasticity of the agent's policy can be used to aid efficient exploration. The parameters of the noise are learned with gradient descent along with the remaining network weights. NoisyNet is straightforward to implement and adds little computational overhead. We find that replacing the conventional exploration heuristics for A3C, DQN and dueling agents (entropy reward and $\epsilon$-greedy respectively) with NoisyNet yields substantially higher scores for a wide range of Atari games, in some cases advancing the agent from sub to super-human performance.
Parallel WaveNet: Fast High-Fidelity Speech Synthesis
Nov 28, 2017
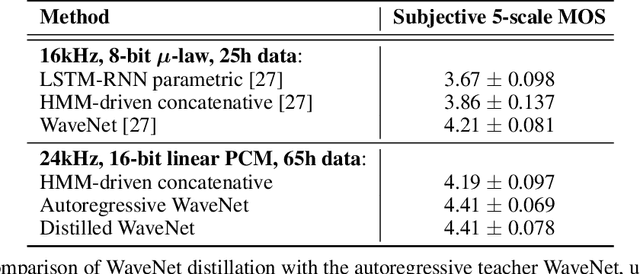
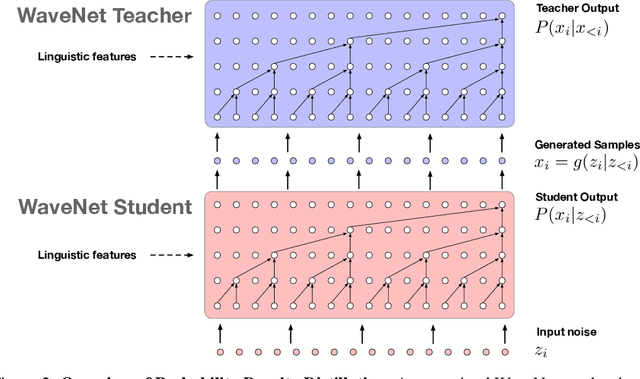
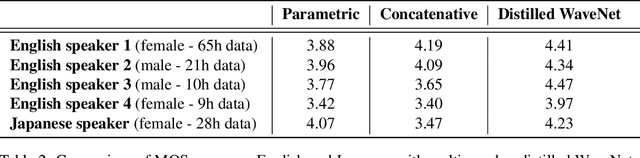
The recently-developed WaveNet architecture is the current state of the art in realistic speech synthesis, consistently rated as more natural sounding for many different languages than any previous system. However, because WaveNet relies on sequential generation of one audio sample at a time, it is poorly suited to today's massively parallel computers, and therefore hard to deploy in a real-time production setting. This paper introduces Probability Density Distillation, a new method for training a parallel feed-forward network from a trained WaveNet with no significant difference in quality. The resulting system is capable of generating high-fidelity speech samples at more than 20 times faster than real-time, and is deployed online by Google Assistant, including serving multiple English and Japanese voices.
Decoupled Neural Interfaces using Synthetic Gradients
Jul 03, 2017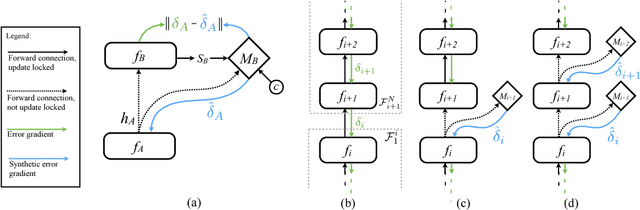
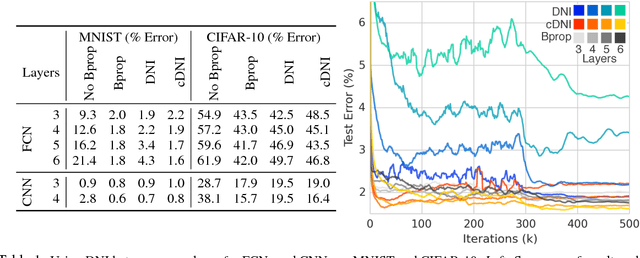
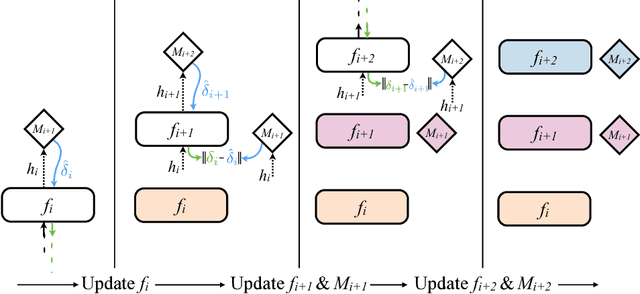

Training directed neural networks typically requires forward-propagating data through a computation graph, followed by backpropagating error signal, to produce weight updates. All layers, or more generally, modules, of the network are therefore locked, in the sense that they must wait for the remainder of the network to execute forwards and propagate error backwards before they can be updated. In this work we break this constraint by decoupling modules by introducing a model of the future computation of the network graph. These models predict what the result of the modelled subgraph will produce using only local information. In particular we focus on modelling error gradients: by using the modelled synthetic gradient in place of true backpropagated error gradients we decouple subgraphs, and can update them independently and asynchronously i.e. we realise decoupled neural interfaces. We show results for feed-forward models, where every layer is trained asynchronously, recurrent neural networks (RNNs) where predicting one's future gradient extends the time over which the RNN can effectively model, and also a hierarchical RNN system with ticking at different timescales. Finally, we demonstrate that in addition to predicting gradients, the same framework can be used to predict inputs, resulting in models which are decoupled in both the forward and backwards pass -- amounting to independent networks which co-learn such that they can be composed into a single functioning corporation.
Automated Curriculum Learning for Neural Networks
Apr 10, 2017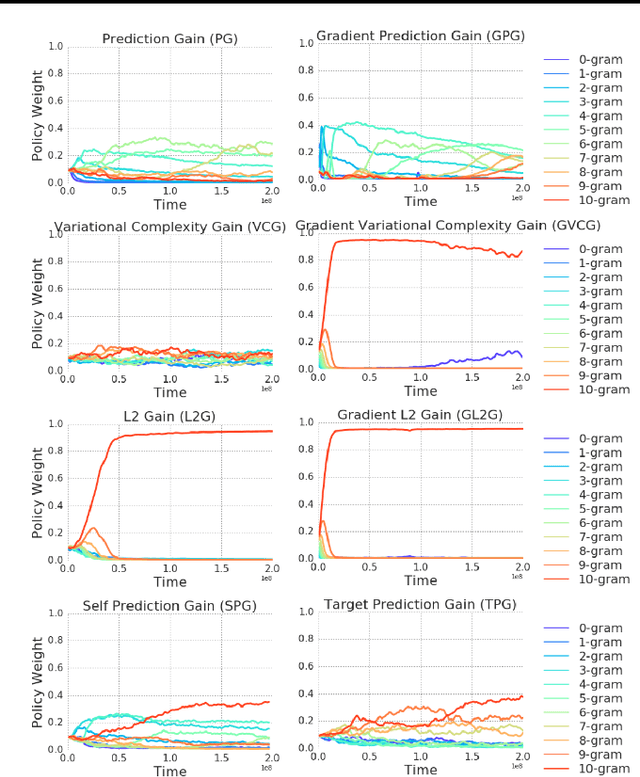
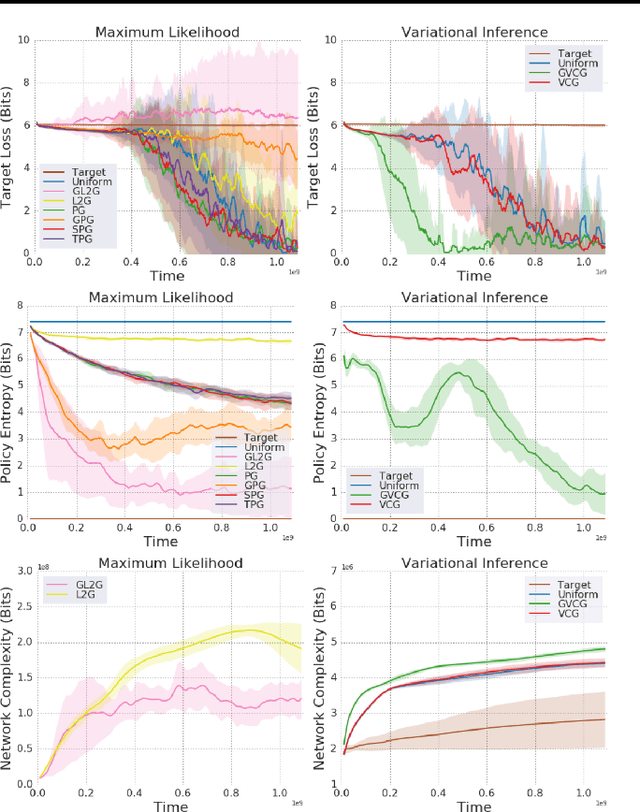
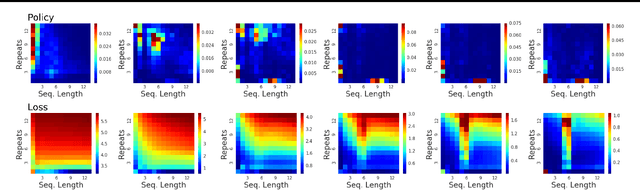
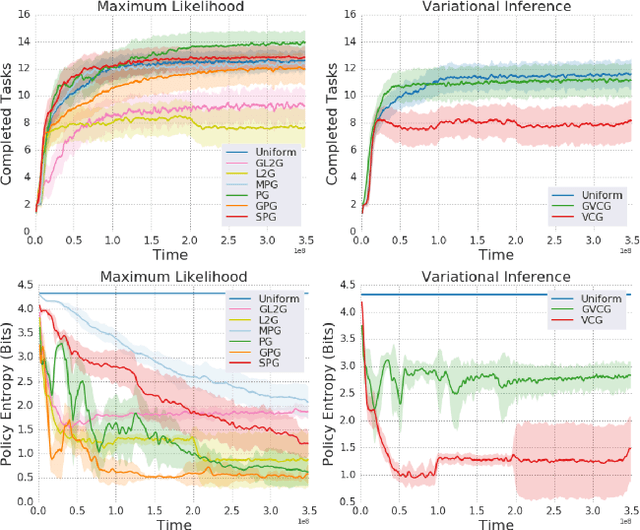
We introduce a method for automatically selecting the path, or syllabus, that a neural network follows through a curriculum so as to maximise learning efficiency. A measure of the amount that the network learns from each data sample is provided as a reward signal to a nonstationary multi-armed bandit algorithm, which then determines a stochastic syllabus. We consider a range of signals derived from two distinct indicators of learning progress: rate of increase in prediction accuracy, and rate of increase in network complexity. Experimental results for LSTM networks on three curricula demonstrate that our approach can significantly accelerate learning, in some cases halving the time required to attain a satisfactory performance level.
Neural Machine Translation in Linear Time
Mar 15, 2017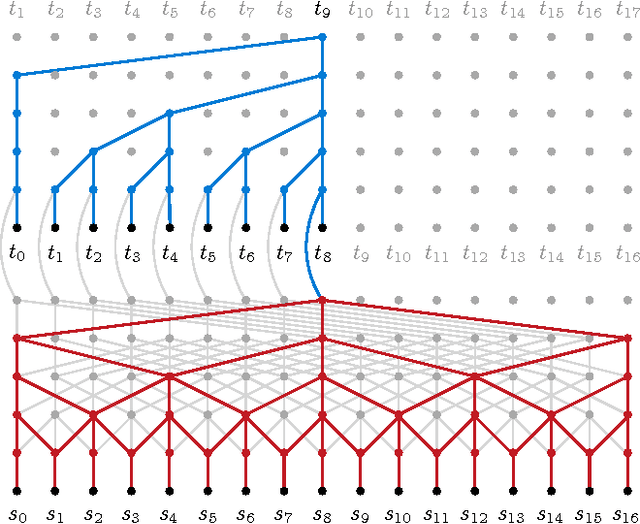
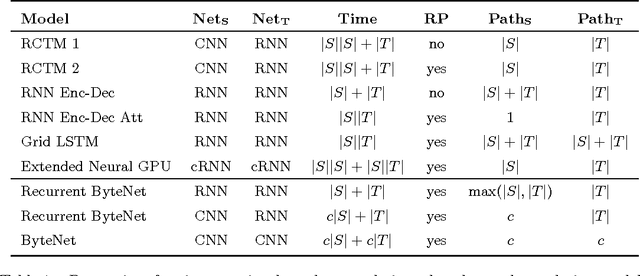


We present a novel neural network for processing sequences. The ByteNet is a one-dimensional convolutional neural network that is composed of two parts, one to encode the source sequence and the other to decode the target sequence. The two network parts are connected by stacking the decoder on top of the encoder and preserving the temporal resolution of the sequences. To address the differing lengths of the source and the target, we introduce an efficient mechanism by which the decoder is dynamically unfolded over the representation of the encoder. The ByteNet uses dilation in the convolutional layers to increase its receptive field. The resulting network has two core properties: it runs in time that is linear in the length of the sequences and it sidesteps the need for excessive memorization. The ByteNet decoder attains state-of-the-art performance on character-level language modelling and outperforms the previous best results obtained with recurrent networks. The ByteNet also achieves state-of-the-art performance on character-to-character machine translation on the English-to-German WMT translation task, surpassing comparable neural translation models that are based on recurrent networks with attentional pooling and run in quadratic time. We find that the latent alignment structure contained in the representations reflects the expected alignment between the tokens.
Adaptive Computation Time for Recurrent Neural Networks
Feb 21, 2017

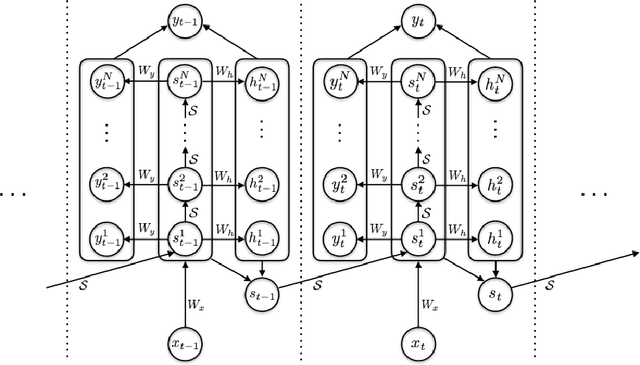

This paper introduces Adaptive Computation Time (ACT), an algorithm that allows recurrent neural networks to learn how many computational steps to take between receiving an input and emitting an output. ACT requires minimal changes to the network architecture, is deterministic and differentiable, and does not add any noise to the parameter gradients. Experimental results are provided for four synthetic problems: determining the parity of binary vectors, applying binary logic operations, adding integers, and sorting real numbers. Overall, performance is dramatically improved by the use of ACT, which successfully adapts the number of computational steps to the requirements of the problem. We also present character-level language modelling results on the Hutter prize Wikipedia dataset. In this case ACT does not yield large gains in performance; however it does provide intriguing insight into the structure of the data, with more computation allocated to harder-to-predict transitions, such as spaces between words and ends of sentences. This suggests that ACT or other adaptive computation methods could provide a generic method for inferring segment boundaries in sequence data.