 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaD Physics: Evaluating information seeking under constraints in physical environments
May 11, 2026Scientific discovery is fundamentally a resource-constrained process that requires navigating complex trade-offs between the quality and quantity of measurements due to physical and cost constraints. Measurements drive the scientific process by revealing novel phenomena to improve our understanding. Existing benchmarks for evaluating agents for scientific discovery focus on either static knowledge-based reasoning or unconstrained experimental design tasks, and do not capture the ability to make measurements and plan under constraints. To bridge this gap, we propose Measuring and Discovering Physics (MaD Physics), a benchmark to evaluate the ability of agents to make informative measurements and conclusions subject to constraints on the quality and quantity of measurements. The benchmark consists of three environments, each based on a distinct physical law. To mitigate contamination from existing knowledge, MaD Physics includes altered physical laws. In each trial, the agent makes measurements of the system until it exhausts an allotted budget and then the agent has to infer the underlying physical law to make predictions about the state of the system in the future. MaD Physics evaluates two fundamental capabilities of scientific agents: inferring models from data and planning under constraints. We also demonstrate how MaD Physics can be used to evaluate other capabilities such as multimodality and in-context learning. We benchmark agents on MaD Physics using four Gemini models (2.5 Flash Lite, 2.5 Flash, 2.5 Pro, and 3 Flash), identifying shortcomings in their structured exploration and data collection capabilities and highlighting directions to improve their scientific reasoning.
How LLMs Detect and Correct Their Own Errors: The Role of Internal Confidence Signals
Apr 24, 2026Large language models can detect their own errors and sometimes correct them without external feedback, but the underlying mechanisms remain unknown. We investigate this through the lens of second-order models of confidence from decision neuroscience. In a first-order system, confidence derives from the generation signal itself and is therefore maximal for the chosen response, precluding error detection. Second-order models posit a partially independent evaluative signal that can disagree with the committed response, providing the basis for error detection. Kumaran et al. (2026) showed that LLMs cache a confidence representation at a token immediately following the answer (i.e. post-answer newline: PANL) -- that causally drives verbal confidence and dissociates from log-probabilities. Here we test whether this PANL signal extends beyond confidence to support error detection and self-correction. Here we test whether this signal supports error detection and self-correction, deriving predictions from the second-order framework. Using a verify-then-correct paradigm, we show that: (i) verbal confidence predicts error detection far beyond token log-probabilities, ruling out a first-order account; (ii) PANL activations predict error detection beyond verbal confidence itself; and (iii) PANL predicts which errors the model can correct -- where all behavioural signals fail. Causal interventions confirm that PANL signals rescue error detection behavior when answer information is corrupted. All findings replicate across models (Gemma 3 27B and Qwen 2.5 7B) and tasks (TriviaQA and MNLI). These results reveal that LLMs naturally implement a second-order confidence architecture whose internal evaluative signal encodes not only whether an answer is likely wrong but whether the model has the knowledge to fix it.
Causal Evidence that Language Models use Confidence to Drive Behavior
Mar 23, 2026Metacognition -- the ability to assess one's own cognitive performance -- is documented across species, with internal confidence estimates serving as a key signal for adaptive behavior. While confidence can be extracted from Large Language Model (LLM) outputs, whether models actively use these signals to regulate behavior remains a fundamental question. We investigate this through a four-phase abstention paradigm.Phase 1 established internal confidence estimates in the absence of an abstention option. Phase 2 revealed that LLMs apply implicit thresholds to these estimates when deciding to answer or abstain. Confidence emerged as the dominant predictor of behavior, with effect sizes an order of magnitude larger than knowledge retrieval accessibility (RAG scores) or surface-level semantic features. Phase 3 provided causal evidence through activation steering: manipulating internal confidence signals correspondingly shifted abstention rates. Finally, Phase 4 demonstrated that models can systematically vary abstention policies based on instructed thresholds.Our findings indicate that abstention arises from the joint operation of internal confidence representations and threshold-based policies, mirroring the two-stage metacognitive control found in biological systems. This capacity is essential as LLMs transition into autonomous agents that must recognize their own uncertainty to decide when to act or seek help.
How do LLMs Compute Verbal Confidence
Mar 18, 2026Verbal confidence -- prompting LLMs to state their confidence as a number or category -- is widely used to extract uncertainty estimates from black-box models. However, how LLMs internally generate such scores remains unknown. We address two questions: first, when confidence is computed - just-in-time when requested, or automatically during answer generation and cached for later retrieval; and second, what verbal confidence represents - token log-probabilities, or a richer evaluation of answer quality? Focusing on Gemma 3 27B and Qwen 2.5 7B, we provide convergent evidence for cached retrieval. Activation steering, patching, noising, and swap experiments reveal that confidence representations emerge at answer-adjacent positions before appearing at the verbalization site. Attention blocking pinpoints the information flow: confidence is gathered from answer tokens, cached at the first post-answer position, then retrieved for output. Critically, linear probing and variance partitioning reveal that these cached representations explain substantial variance in verbal confidence beyond token log-probabilities, suggesting a richer answer-quality evaluation rather than a simple fluency readout. These findings demonstrate that verbal confidence reflects automatic, sophisticated self-evaluation -- not post-hoc reconstruction -- with implications for understanding metacognition in LLMs and improving calibration.
A Theory of Appropriateness That Accounts for Norms of Rationality
Mar 14, 2026We propose a society-first theory of normative appropriateness where individuals, modeled as pre-trained actors with cognitive architectures analogous to Large Language Models (LLMs), generate behavior via predictive pattern completion. Our theory posits that individuals act by completing distributed symbolic patterns based on context, answering questions such as "What does a person such as I do in a situation such as this?". This sense-making mechanism provides a parsimonious account of the key features of human norms: their context-dependence, arbitrariness, automaticity, dynamism, and their support from social sanctioning. It challenges rational-choice theories of social norms by accounting for their key features without needing to exogenously posit scalar rewards or preference relations. By distinguishing between explicit norms, which we associate with in-context adaptation, and implicit norms, which we associate with long-term memory, the theory reconceptualizes several foundational ideas in cognitive science. In particular, it gives an alternative account to the data traditionally seen as supporting dual-process models, and it flips the role of rationality, allowing us to construe it as adherence to culturally-contingent justification standards.
Intelligent AI Delegation
Feb 12, 2026AI agents are able to tackle increasingly complex tasks. To achieve more ambitious goals, AI agents need to be able to meaningfully decompose problems into manageable sub-components, and safely delegate their completion across to other AI agents and humans alike. Yet, existing task decomposition and delegation methods rely on simple heuristics, and are not able to dynamically adapt to environmental changes and robustly handle unexpected failures. Here we propose an adaptive framework for intelligent AI delegation - a sequence of decisions involving task allocation, that also incorporates transfer of authority, responsibility, accountability, clear specifications regarding roles and boundaries, clarity of intent, and mechanisms for establishing trust between the two (or more) parties. The proposed framework is applicable to both human and AI delegators and delegatees in complex delegation networks, aiming to inform the development of protocols in the emerging agentic web.
Perplexity Cannot Always Tell Right from Wrong
Jan 30, 2026Perplexity -- a function measuring a model's overall level of "surprise" when encountering a particular output -- has gained significant traction in recent years, both as a loss function and as a simple-to-compute metric of model quality. Prior studies have pointed out several limitations of perplexity, often from an empirical manner. Here we leverage recent results on Transformer continuity to show in a rigorous manner how perplexity may be an unsuitable metric for model selection. Specifically, we prove that, if there is any sequence that a compact decoder-only Transformer model predicts accurately and confidently -- a necessary pre-requisite for strong generalisation -- it must imply existence of another sequence with very low perplexity, but not predicted correctly by that same model. Further, by analytically studying iso-perplexity plots, we find that perplexity will not always select for the more accurate model -- rather, any increase in model confidence must be accompanied by a commensurate rise in accuracy for the new model to be selected.
Distributional AGI Safety
Dec 18, 2025AI safety and alignment research has predominantly been focused on methods for safeguarding individual AI systems, resting on the assumption of an eventual emergence of a monolithic Artificial General Intelligence (AGI). The alternative AGI emergence hypothesis, where general capability levels are first manifested through coordination in groups of sub-AGI individual agents with complementary skills and affordances, has received far less attention. Here we argue that this patchwork AGI hypothesis needs to be given serious consideration, and should inform the development of corresponding safeguards and mitigations. The rapid deployment of advanced AI agents with tool-use capabilities and the ability to communicate and coordinate makes this an urgent safety consideration. We therefore propose a framework for distributional AGI safety that moves beyond evaluating and aligning individual agents. This framework centers on the design and implementation of virtual agentic sandbox economies (impermeable or semi-permeable), where agent-to-agent transactions are governed by robust market mechanisms, coupled with appropriate auditability, reputation management, and oversight to mitigate collective risks.
Societal and technological progress as sewing an ever-growing, ever-changing, patchy, and polychrome quilt
May 08, 2025Artificial Intelligence (AI) systems are increasingly placed in positions where their decisions have real consequences, e.g., moderating online spaces, conducting research, and advising on policy. Ensuring they operate in a safe and ethically acceptable fashion is thus critical. However, most solutions have been a form of one-size-fits-all "alignment". We are worried that such systems, which overlook enduring moral diversity, will spark resistance, erode trust, and destabilize our institutions. This paper traces the underlying problem to an often-unstated Axiom of Rational Convergence: the idea that under ideal conditions, rational agents will converge in the limit of conversation on a single ethics. Treating that premise as both optional and doubtful, we propose what we call the appropriateness framework: an alternative approach grounded in conflict theory, cultural evolution, multi-agent systems, and institutional economics. The appropriateness framework treats persistent disagreement as the normal case and designs for it by applying four principles: (1) contextual grounding, (2) community customization, (3) continual adaptation, and (4) polycentric governance. We argue here that adopting these design principles is a good way to shift the main alignment metaphor from moral unification to a more productive metaphor of conflict management, and that taking this step is both desirable and urgent.
Wanting to be Understood
Apr 10, 2025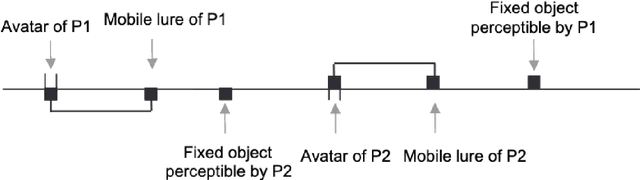
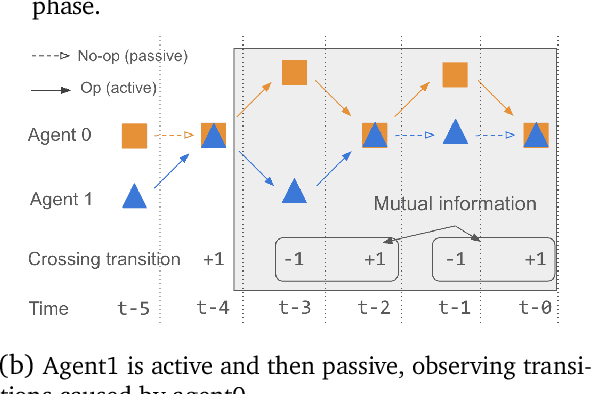
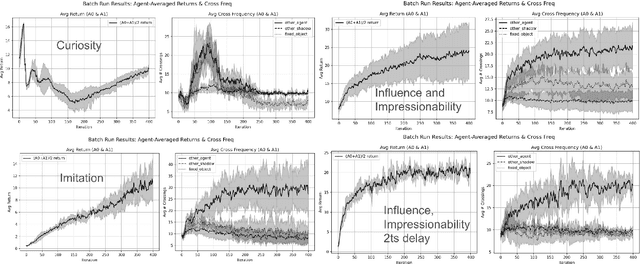
This paper explores an intrinsic motivation for mutual awareness, hypothesizing that humans possess a fundamental drive to understand and to be understood even in the absence of extrinsic rewards. Through simulations of the perceptual crossing paradigm, we explore the effect of various internal reward functions in reinforcement learning agents. The drive to understand is implemented as an active inference type artificial curiosity reward, whereas the drive to be understood is implemented through intrinsic rewards for imitation, influence/impressionability, and sub-reaction time anticipation of the other. Results indicate that while artificial curiosity alone does not lead to a preference for social interaction, rewards emphasizing reciprocal understanding successfully drive agents to prioritize interaction. We demonstrate that this intrinsic motivation can facilitate cooperation in tasks where only one agent receives extrinsic reward for the behaviour of the other.