 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo as the New Language for Real-World Decision Making
Feb 27, 2024


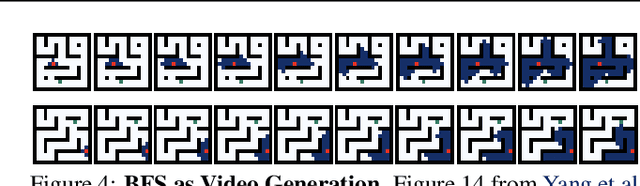
Both text and video data are abundant on the internet and support large-scale self-supervised learning through next token or frame prediction. However, they have not been equally leveraged: language models have had significant real-world impact, whereas video generation has remained largely limited to media entertainment. Yet video data captures important information about the physical world that is difficult to express in language. To address this gap, we discuss an under-appreciated opportunity to extend video generation to solve tasks in the real world. We observe how, akin to language, video can serve as a unified interface that can absorb internet knowledge and represent diverse tasks. Moreover, we demonstrate how, like language models, video generation can serve as planners, agents, compute engines, and environment simulators through techniques such as in-context learning, planning and reinforcement learning. We identify major impact opportunities in domains such as robotics, self-driving, and science, supported by recent work that demonstrates how such advanced capabilities in video generation are plausibly within reach. Lastly, we identify key challenges in video generation that mitigate progress. Addressing these challenges will enable video generation models to demonstrate unique value alongside language models in a wider array of AI applications.
Genie: Generative Interactive Environments
Feb 23, 2024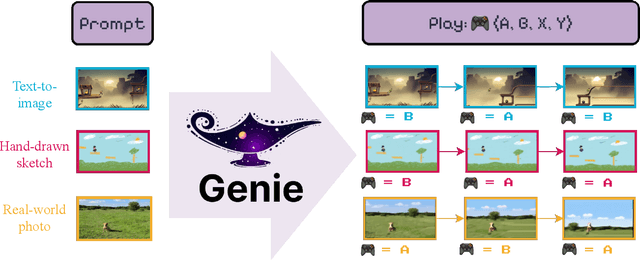
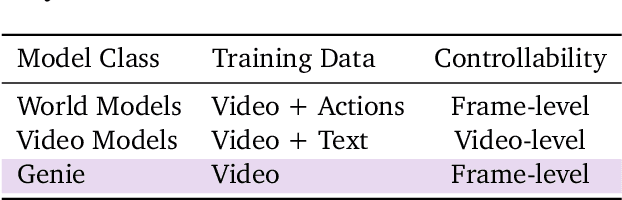
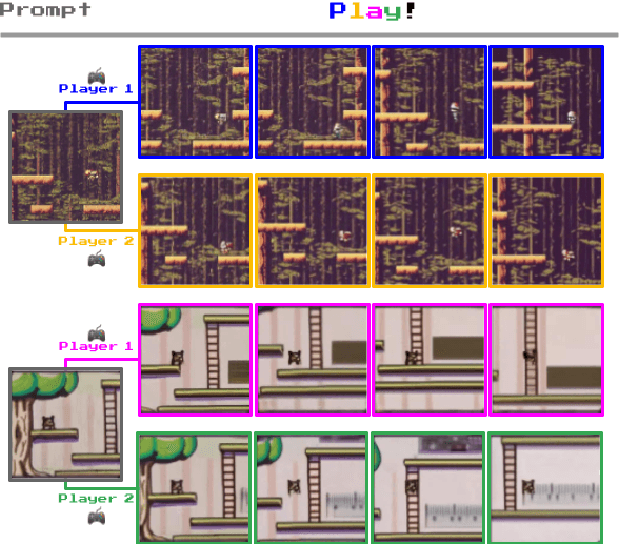
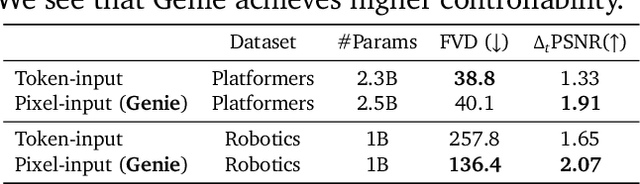
We introduce Genie, the first generative interactive environment trained in an unsupervised manner from unlabelled Internet videos. The model can be prompted to generate an endless variety of action-controllable virtual worlds described through text, synthetic images, photographs, and even sketches. At 11B parameters, Genie can be considered a foundation world model. It is comprised of a spatiotemporal video tokenizer, an autoregressive dynamics model, and a simple and scalable latent action model. Genie enables users to act in the generated environments on a frame-by-frame basis despite training without any ground-truth action labels or other domain-specific requirements typically found in the world model literature. Further the resulting learned latent action space facilitates training agents to imitate behaviors from unseen videos, opening the path for training generalist agents of the future.
A Generalist Dynamics Model for Control
May 18, 2023



We investigate the use of transformer sequence models as dynamics models (TDMs) for control. In a number of experiments in the DeepMind control suite, we find that first, TDMs perform well in a single-environment learning setting when compared to baseline models. Second, TDMs exhibit strong generalization capabilities to unseen environments, both in a few-shot setting, where a generalist model is fine-tuned with small amounts of data from the target environment, and in a zero-shot setting, where a generalist model is applied to an unseen environment without any further training. We further demonstrate that generalizing system dynamics can work much better than generalizing optimal behavior directly as a policy. This makes TDMs a promising ingredient for a foundation model of control.
Accelerating exploration and representation learning with offline pre-training
Mar 31, 2023

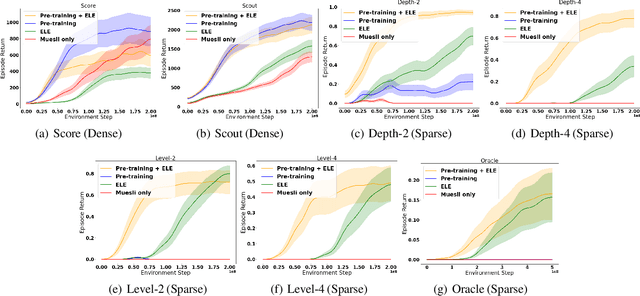
Sequential decision-making agents struggle with long horizon tasks, since solving them requires multi-step reasoning. Most reinforcement learning (RL) algorithms address this challenge by improved credit assignment, introducing memory capability, altering the agent's intrinsic motivation (i.e. exploration) or its worldview (i.e. knowledge representation). Many of these components could be learned from offline data. In this work, we follow the hypothesis that exploration and representation learning can be improved by separately learning two different models from a single offline dataset. We show that learning a state representation using noise-contrastive estimation and a model of auxiliary reward separately from a single collection of human demonstrations can significantly improve the sample efficiency on the challenging NetHack benchmark. We also ablate various components of our experimental setting and highlight crucial insights.
A Generalist Agent
May 19, 2022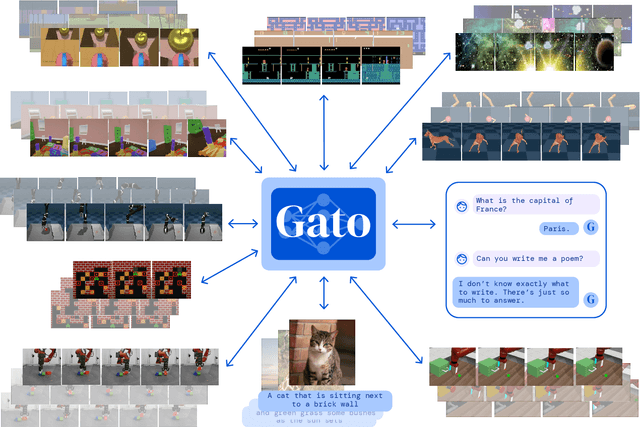
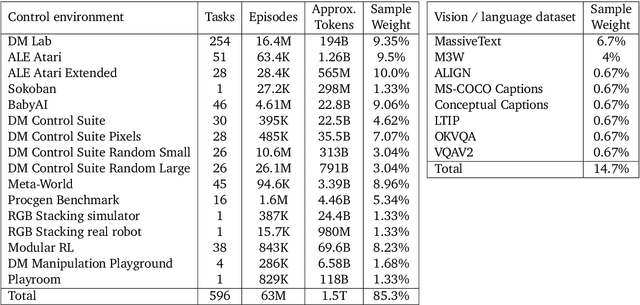
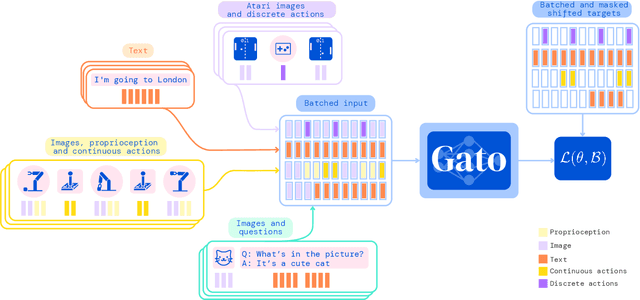

Inspired by progress in large-scale language modeling, we apply a similar approach towards building a single generalist agent beyond the realm of text outputs. The agent, which we refer to as Gato, works as a multi-modal, multi-task, multi-embodiment generalist policy. The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens. In this report we describe the model and the data, and document the current capabilities of Gato.
Imitation by Predicting Observations
Jul 08, 2021
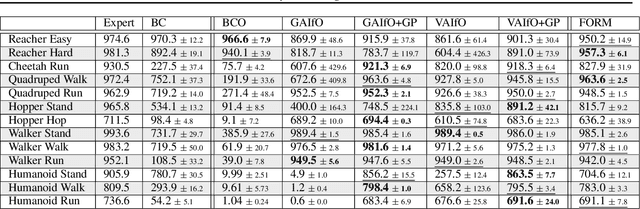


Imitation learning enables agents to reuse and adapt the hard-won expertise of others, offering a solution to several key challenges in learning behavior. Although it is easy to observe behavior in the real-world, the underlying actions may not be accessible. We present a new method for imitation solely from observations that achieves comparable performance to experts on challenging continuous control tasks while also exhibiting robustness in the presence of observations unrelated to the task. Our method, which we call FORM (for "Future Observation Reward Model") is derived from an inverse RL objective and imitates using a model of expert behavior learned by generative modelling of the expert's observations, without needing ground truth actions. We show that FORM performs comparably to a strong baseline IRL method (GAIL) on the DeepMind Control Suite benchmark, while outperforming GAIL in the presence of task-irrelevant features.
Evaluating task-agnostic exploration for fixed-batch learning of arbitrary future tasks
Nov 20, 2019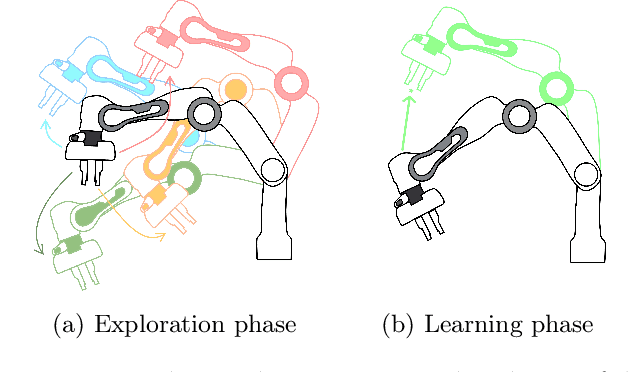
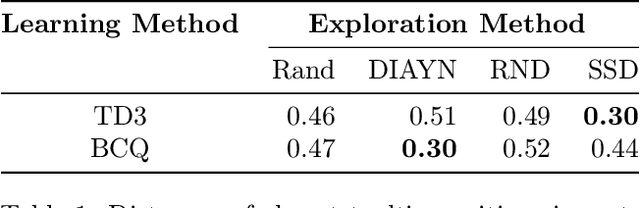

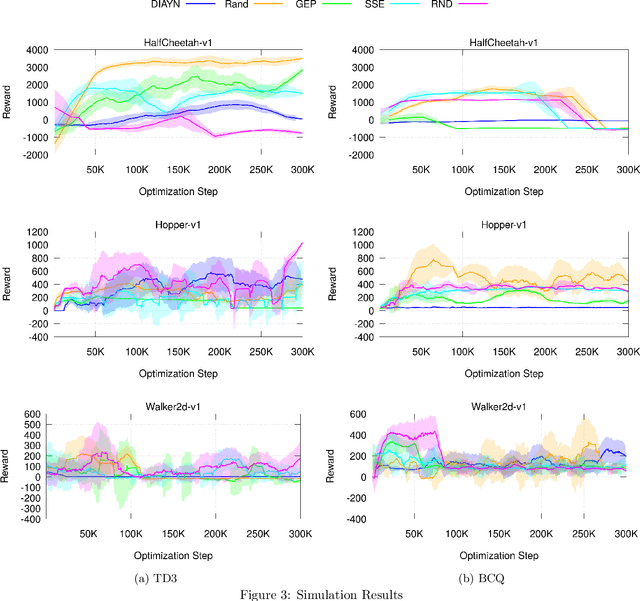
Deep reinforcement learning has been shown to solve challenging tasks where large amounts of training experience is available, usually obtained online while learning the task. Robotics is a significant potential application domain for many of these algorithms, but generating robot experience in the real world is expensive, especially when each task requires a lengthy online training procedure. Off-policy algorithms can in principle learn arbitrary tasks from a diverse enough fixed dataset. In this work, we evaluate popular exploration methods by generating robotics datasets for the purpose of learning to solve tasks completely offline without any further interaction in the real world. We present results on three popular continuous control tasks in simulation, as well as continuous control of a high-dimensional real robot arm. Code documenting all algorithms, experiments, and hyper-parameters is available at https://github.com/qutrobotlearning/batchlearning.
Ctrl-Z: Recovering from Instability in Reinforcement Learning
Oct 09, 2019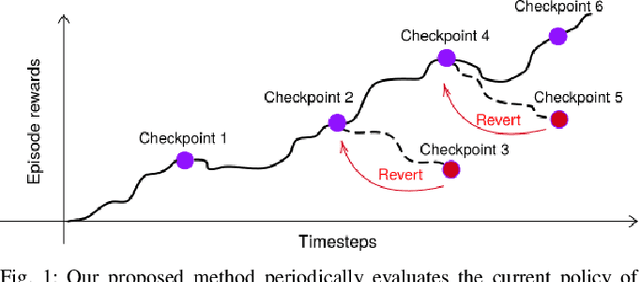
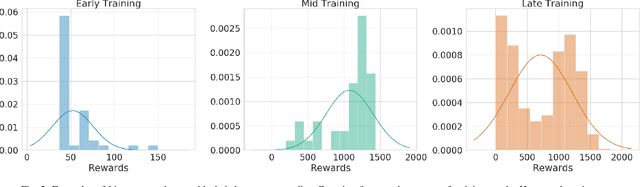

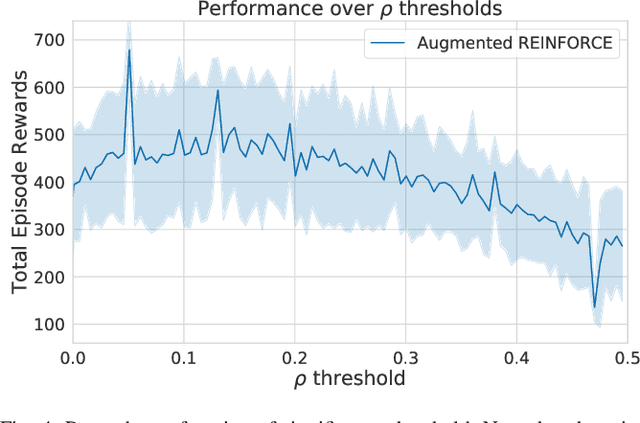
When learning behavior, training data is often generated by the learner itself; this can result in unstable training dynamics, and this problem has particularly important applications in safety-sensitive real-world control tasks such as robotics. In this work, we propose a principled and model-agnostic approach to mitigate the issue of unstable learning dynamics by maintaining a history of a reinforcement learning agent over the course of training, and reverting to the parameters of a previous agent whenever performance significantly decreases. We develop techniques for evaluating this performance through statistical hypothesis testing of continued improvement, and evaluate them on a standard suite of challenging benchmark tasks involving continuous control of simulated robots. We show improvements over state-of-the-art reinforcement learning algorithms in performance and robustness to hyperparameters, outperforming DDPG in 5 out of 6 evaluation environments and showing no decrease in performance with TD3, which is known to be relatively stable. In this way, our approach takes an important step towards increasing data efficiency and stability in training for real-world robotic applications.
Zero-shot Sim-to-Real Transfer with Modular Priors
Sep 20, 2018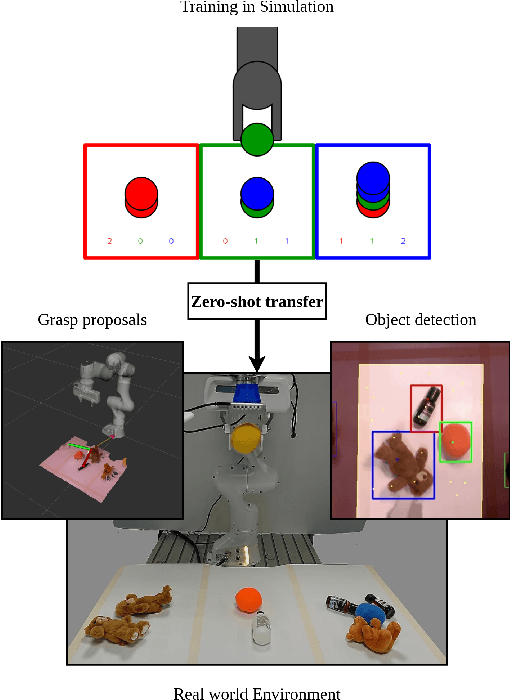
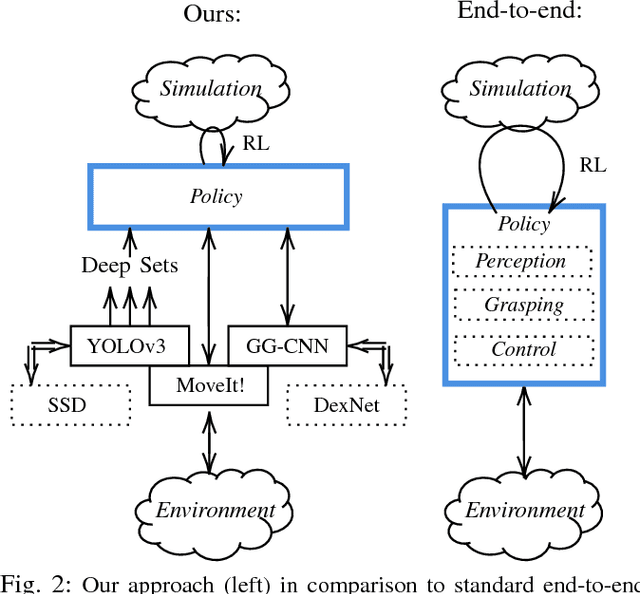
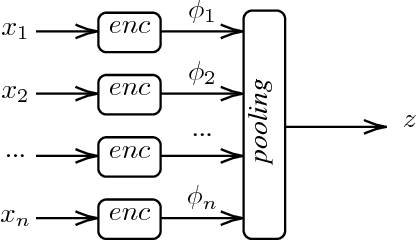

Current end-to-end Reinforcement Learning (RL) approaches are severely limited by restrictively large search spaces and are prone to overfitting to their training environment. This is because in end-to-end RL perception, decision-making and low-level control are all being learned jointly from very sparse reward signals, with little capability of incorporating prior knowledge or existing algorithms. In this work, we propose a novel framework that effectively decouples RL for high-level decision making from low-level perception and control. This allows us to transfer a learned policy from a highly abstract simulation to a real robot without requiring any transfer learning. We therefore coin our approach zero-shot sim-to-real transfer. We successfully demonstrate our approach on the robot manipulation task of object sorting. A key component of our approach is a deep sets encoder that enables us to reinforcement learn the high-level policy based on the variable-length output of a pre-trained object detector, instead of learning from raw pixels. We show that this method can learn effective policies within mere minutes of highly simplified simulation. The learned policies can be directly deployed on a robot without further training, and generalize to variations of the task unseen during training.
Learning Deployable Navigation Policies at Kilometer Scale from a Single Traversal
Jul 11, 2018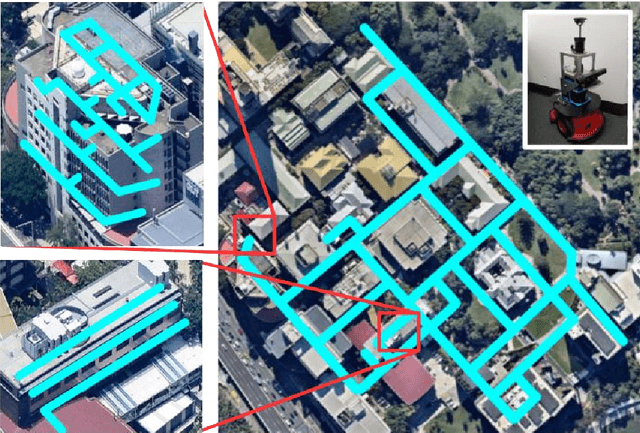
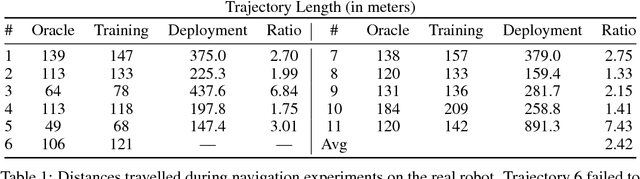

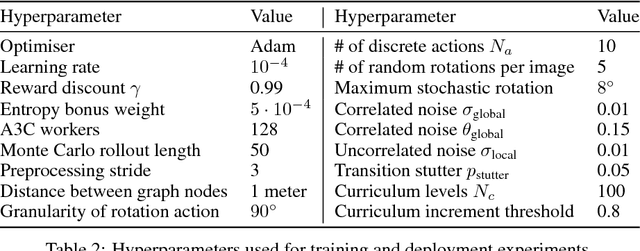
Model-free reinforcement learning has recently been shown to be effective at learning navigation policies from complex image input. However, these algorithms tend to require large amounts of interaction with the environment, which can be prohibitively costly to obtain on robots in the real world. We present an approach for efficiently learning goal-directed navigation policies on a mobile robot, from only a single coverage traversal of recorded data. The navigation agent learns an effective policy over a diverse action space in a large heterogeneous environment consisting of more than 2km of travel, through buildings and outdoor regions that collectively exhibit large variations in visual appearance, self-similarity, and connectivity. We compare pretrained visual encoders that enable precomputation of visual embeddings to achieve a throughput of tens of thousands of transitions per second at training time on a commodity desktop computer, allowing agents to learn from millions of trajectories of experience in a matter of hours. We propose multiple forms of computationally efficient stochastic augmentation to enable the learned policy to generalise beyond these precomputed embeddings, and demonstrate successful deployment of the learned policy on the real robot without fine tuning, despite environmental appearance differences at test time. The dataset and code required to reproduce these results and apply the technique to other datasets and robots is made publicly available at rl-navigation.github.io/deployable.