 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntentmaking and Sensemaking: Human Interaction with AI-Guided Mathematical Discovery
May 07, 2026Artificial intelligence offers powerful new tools for scientific discovery, but the interaction paradigms required to effectively harness these systems remain underexplored. In this paper, we present findings from a formative user study with 11 expert mathematicians who used AlphaEvolve, an evolutionary coding agent, to tackle advanced problems in their fields of expertise. We identify and characterize a distinct workflow we term intentmaking, the iterative process of discovering, defining, and refining one's experimental goals through active system interaction. We frame this as a natural extension to sensemaking, the cognitive process of building an understanding of complex or novel data. We suggest that users enter a cycle of intentmaking (defining and updating their experiment) and sensemaking (interpreting the results) which repeats many times during the course of an investigation. Our documentation of these themes suggests an approach to designing AI tools for scientific discovery that goes beyond the existing question/answer model of many current systems, treating them as collaborative instruments rather than opaque black-box assistants.
ArchAgent: Agentic AI-driven Computer Architecture Discovery
Feb 25, 2026Agile hardware design flows are a critically needed force multiplier to meet the exploding demand for compute. Recently, agentic generative AI systems have demonstrated significant advances in algorithm design, improving code efficiency, and enabling discovery across scientific domains. Bridging these worlds, we present ArchAgent, an automated computer architecture discovery system built on AlphaEvolve. We show ArchAgent's ability to automatically design/implement state-of-the-art (SoTA) cache replacement policies (architecting new mechanisms/logic, not only changing parameters), broadly within the confines of an established cache replacement policy design competition. In two days without human intervention, ArchAgent generated a policy achieving a 5.3% IPC speedup improvement over the prior SoTA on public multi-core Google Workload Traces. On the heavily-explored single-core SPEC06 workloads, it generated a policy in just 18 days showing a 0.9% IPC speedup improvement over the existing SoTA (a similar "winning margin" as reported by the existing SoTA). ArchAgent achieved these gains 3-5x faster than prior human-developed SoTA policies. Agentic flows also enable "post-silicon hyperspecialization" where agents tune runtime-configurable parameters exposed in hardware policies to further align the policies with a specific workload (mix). Exploiting this, we demonstrate a 2.4% IPC speedup improvement over prior SoTA on SPEC06 workloads. Finally, we outline broader implications for computer architecture research in the era of agentic AI. For example, we demonstrate the phenomenon of "simulator escapes", where the agentic AI flow discovered and exploited a loophole in a popular microarchitectural simulator - a consequence of the fact that these research tools were designed for a (now past) world where they were exclusively operated by humans acting in good-faith.
Magellan: Autonomous Discovery of Novel Compiler Optimization Heuristics with AlphaEvolve
Jan 28, 2026Modern compilers rely on hand-crafted heuristics to guide optimization passes. These human-designed rules often struggle to adapt to the complexity of modern software and hardware and lead to high maintenance burden. To address this challenge, we present Magellan, an agentic framework that evolves the compiler pass itself by synthesizing executable C++ decision logic. Magellan couples an LLM coding agent with evolutionary search and autotuning in a closed loop of generation, evaluation on user-provided macro-benchmarks, and refinement, producing compact heuristics that integrate directly into existing compilers. Across several production optimization tasks, Magellan discovers policies that match or surpass expert baselines. In LLVM function inlining, Magellan synthesizes new heuristics that outperform decades of manual engineering for both binary-size reduction and end-to-end performance. In register allocation, it learns a concise priority rule for live-range processing that matches intricate human-designed policies on a large-scale workload. We also report preliminary results on XLA problems, demonstrating portability beyond LLVM with reduced engineering effort.
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Jun 16, 2025In this white paper, we present AlphaEvolve, an evolutionary coding agent that substantially enhances capabilities of state-of-the-art LLMs on highly challenging tasks such as tackling open scientific problems or optimizing critical pieces of computational infrastructure. AlphaEvolve orchestrates an autonomous pipeline of LLMs, whose task is to improve an algorithm by making direct changes to the code. Using an evolutionary approach, continuously receiving feedback from one or more evaluators, AlphaEvolve iteratively improves the algorithm, potentially leading to new scientific and practical discoveries. We demonstrate the broad applicability of this approach by applying it to a number of important computational problems. When applied to optimizing critical components of large-scale computational stacks at Google, AlphaEvolve developed a more efficient scheduling algorithm for data centers, found a functionally equivalent simplification in the circuit design of hardware accelerators, and accelerated the training of the LLM underpinning AlphaEvolve itself. Furthermore, AlphaEvolve discovered novel, provably correct algorithms that surpass state-of-the-art solutions on a spectrum of problems in mathematics and computer science, significantly expanding the scope of prior automated discovery methods (Romera-Paredes et al., 2023). Notably, AlphaEvolve developed a search algorithm that found a procedure to multiply two $4 \times 4$ complex-valued matrices using $48$ scalar multiplications; offering the first improvement, after 56 years, over Strassen's algorithm in this setting. We believe AlphaEvolve and coding agents like it can have a significant impact in improving solutions of problems across many areas of science and computation.
Amplifying human performance in combinatorial competitive programming
Nov 29, 2024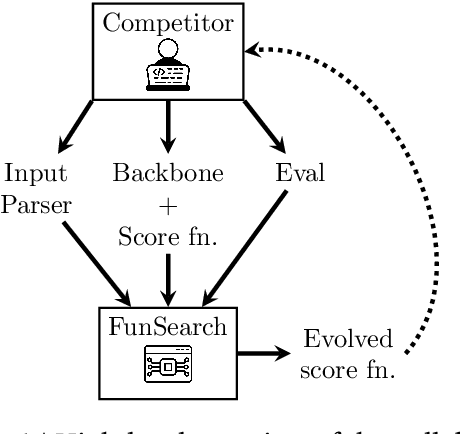

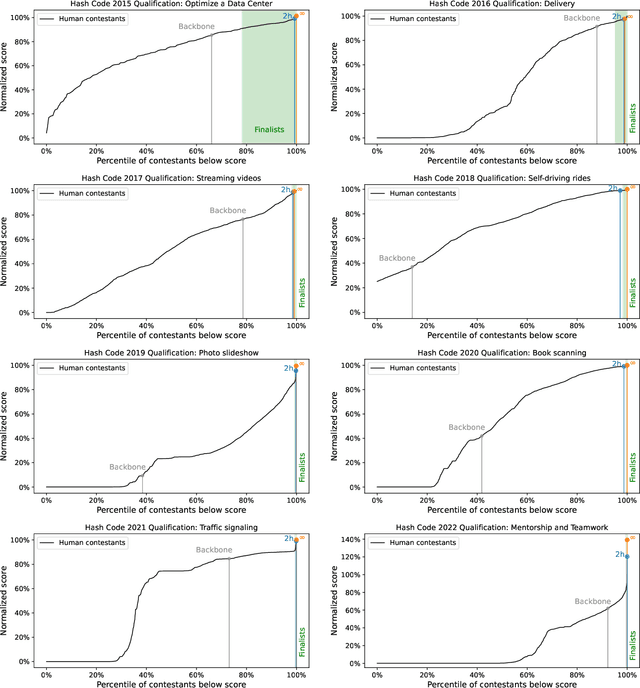
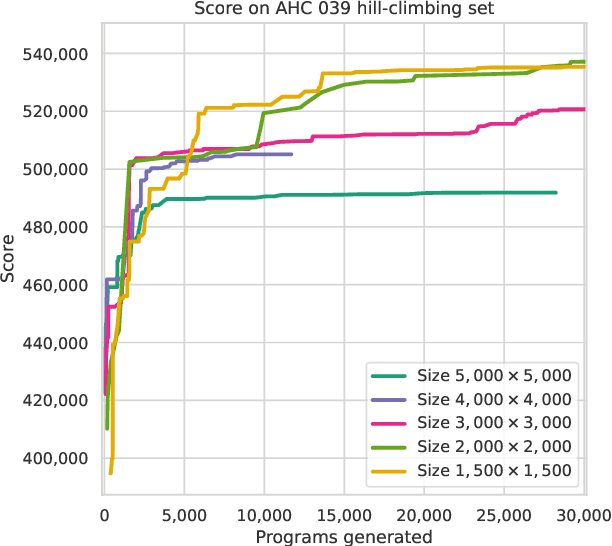
Recent years have seen a significant surge in complex AI systems for competitive programming, capable of performing at admirable levels against human competitors. While steady progress has been made, the highest percentiles still remain out of reach for these methods on standard competition platforms such as Codeforces. Here we instead focus on combinatorial competitive programming, where the target is to find as-good-as-possible solutions to otherwise computationally intractable problems, over specific given inputs. We hypothesise that this scenario offers a unique testbed for human-AI synergy, as human programmers can write a backbone of a heuristic solution, after which AI can be used to optimise the scoring function used by the heuristic. We deploy our approach on previous iterations of Hash Code, a global team programming competition inspired by NP-hard software engineering problems at Google, and we leverage FunSearch to evolve our scoring functions. Our evolved solutions significantly improve the attained scores from their baseline, successfully breaking into the top percentile on all previous Hash Code online qualification rounds, and outperforming the top human teams on several. Our method is also performant on an optimisation problem that featured in a recent held-out AtCoder contest.
Quantum Circuit Optimization with AlphaTensor
Mar 05, 2024



A key challenge in realizing fault-tolerant quantum computers is circuit optimization. Focusing on the most expensive gates in fault-tolerant quantum computation (namely, the T gates), we address the problem of T-count optimization, i.e., minimizing the number of T gates that are needed to implement a given circuit. To achieve this, we develop AlphaTensor-Quantum, a method based on deep reinforcement learning that exploits the relationship between optimizing T-count and tensor decomposition. Unlike existing methods for T-count optimization, AlphaTensor-Quantum can incorporate domain-specific knowledge about quantum computation and leverage gadgets, which significantly reduces the T-count of the optimized circuits. AlphaTensor-Quantum outperforms the existing methods for T-count optimization on a set of arithmetic benchmarks (even when compared without making use of gadgets). Remarkably, it discovers an efficient algorithm akin to Karatsuba's method for multiplication in finite fields. AlphaTensor-Quantum also finds the best human-designed solutions for relevant arithmetic computations used in Shor's algorithm and for quantum chemistry simulation, thus demonstrating it can save hundreds of hours of research by optimizing relevant quantum circuits in a fully automated way.
A Generalist Agent
May 19, 2022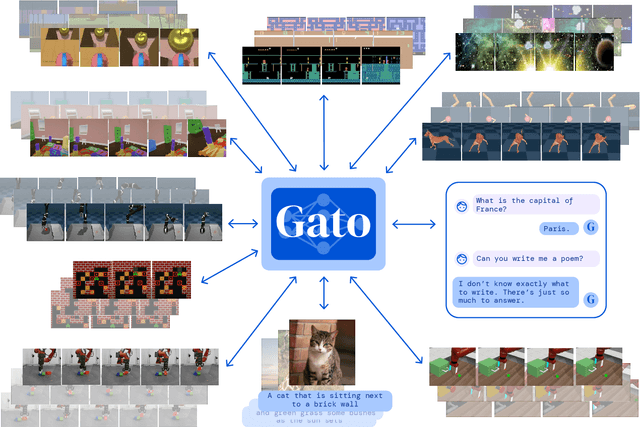
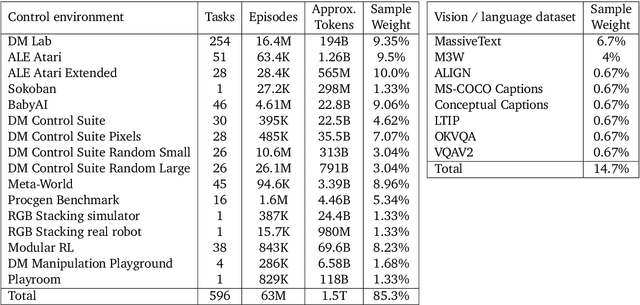
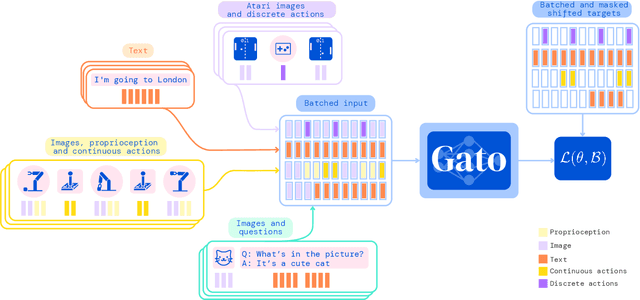

Inspired by progress in large-scale language modeling, we apply a similar approach towards building a single generalist agent beyond the realm of text outputs. The agent, which we refer to as Gato, works as a multi-modal, multi-task, multi-embodiment generalist policy. The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens. In this report we describe the model and the data, and document the current capabilities of Gato.
Benchmarks for Deep Off-Policy Evaluation
Mar 30, 2021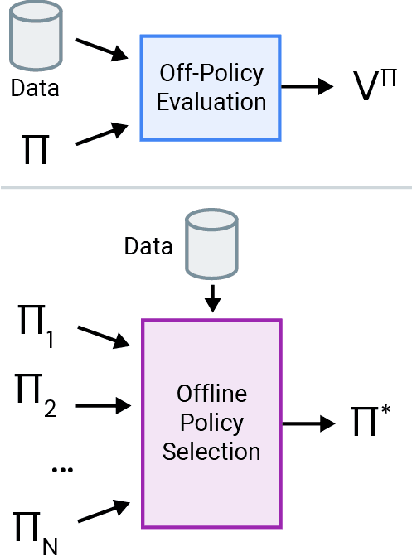
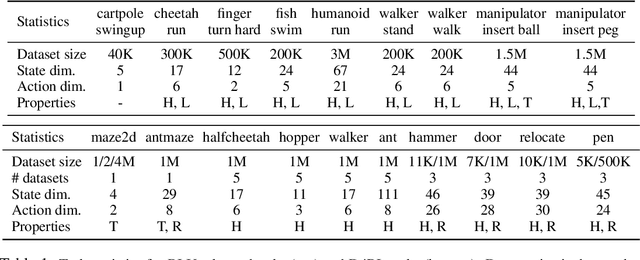
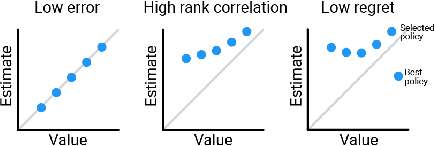
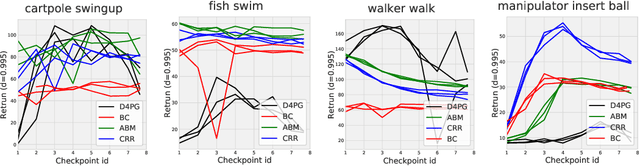
Off-policy evaluation (OPE) holds the promise of being able to leverage large, offline datasets for both evaluating and selecting complex policies for decision making. The ability to learn offline is particularly important in many real-world domains, such as in healthcare, recommender systems, or robotics, where online data collection is an expensive and potentially dangerous process. Being able to accurately evaluate and select high-performing policies without requiring online interaction could yield significant benefits in safety, time, and cost for these applications. While many OPE methods have been proposed in recent years, comparing results between papers is difficult because currently there is a lack of a comprehensive and unified benchmark, and measuring algorithmic progress has been challenging due to the lack of difficult evaluation tasks. In order to address this gap, we present a collection of policies that in conjunction with existing offline datasets can be used for benchmarking off-policy evaluation. Our tasks include a range of challenging high-dimensional continuous control problems, with wide selections of datasets and policies for performing policy selection. The goal of our benchmark is to provide a standardized measure of progress that is motivated from a set of principles designed to challenge and test the limits of existing OPE methods. We perform an evaluation of state-of-the-art algorithms and provide open-source access to our data and code to foster future research in this area.
Automatic differentiation for Riemannian optimization on low-rank matrix and tensor-train manifolds
Mar 27, 2021
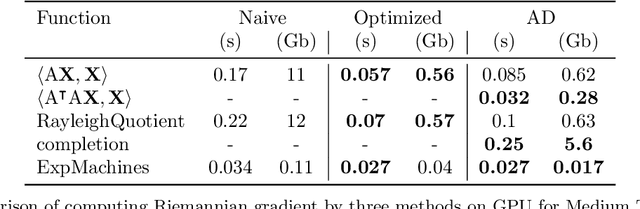
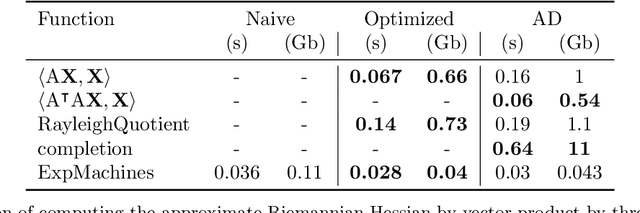

In scientific computing and machine learning applications, matrices and more general multidimensional arrays (tensors) can often be approximated with the help of low-rank decompositions. Since matrices and tensors of fixed rank form smooth Riemannian manifolds, one of the popular tools for finding the low-rank approximations is to use the Riemannian optimization. Nevertheless, efficient implementation of Riemannian gradients and Hessians, required in Riemannian optimization algorithms, can be a nontrivial task in practice. Moreover, in some cases, analytic formulas are not even available. In this paper, we build upon automatic differentiation and propose a method that, given an implementation of the function to be minimized, efficiently computes Riemannian gradients and matrix-by-vector products between approximate Riemannian Hessian and a given vector.
Semi-supervised reward learning for offline reinforcement learning
Dec 12, 2020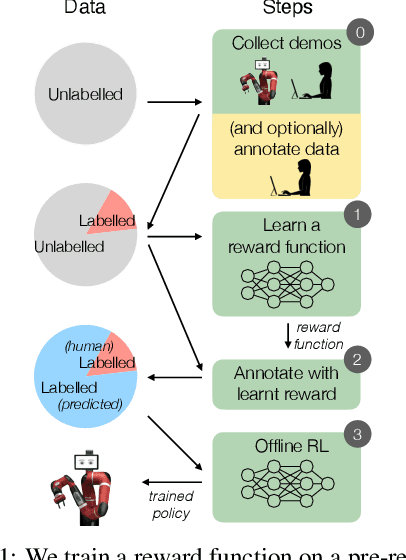
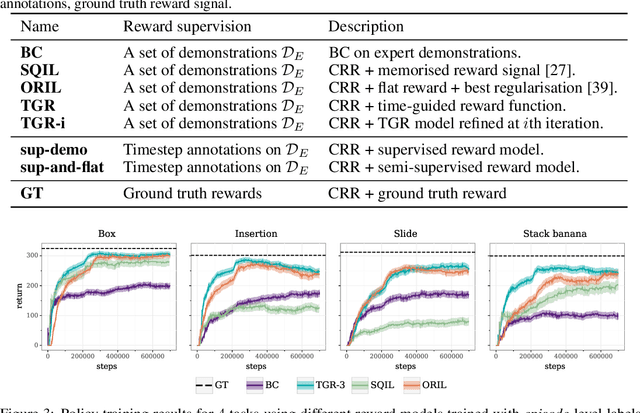

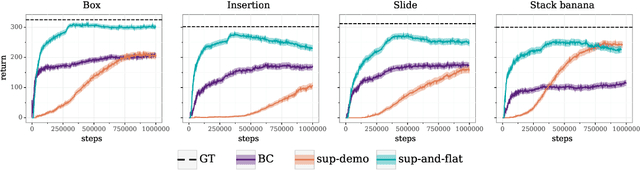
In offline reinforcement learning (RL) agents are trained using a logged dataset. It appears to be the most natural route to attack real-life applications because in domains such as healthcare and robotics interactions with the environment are either expensive or unethical. Training agents usually requires reward functions, but unfortunately, rewards are seldom available in practice and their engineering is challenging and laborious. To overcome this, we investigate reward learning under the constraint of minimizing human reward annotations. We consider two types of supervision: timestep annotations and demonstrations. We propose semi-supervised learning algorithms that learn from limited annotations and incorporate unlabelled data. In our experiments with a simulated robotic arm, we greatly improve upon behavioural cloning and closely approach the performance achieved with ground truth rewards. We further investigate the relationship between the quality of the reward model and the final policies. We notice, for example, that the reward models do not need to be perfect to result in useful policies.