 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining Generalizable Activation Functions
Feb 05, 2026The choice of activation function is an active area of research, with different proposals aimed at improving optimization, while maintaining expressivity. Additionally, the activation function can significantly alter the implicit inductive bias of the architecture, controlling its non-linear behavior. In this paper, in line with previous work, we argue that evolutionary search provides a useful framework for finding new activation functions, while we also make two novel observations. The first is that modern pipelines, such as AlphaEvolve, which relies on frontier LLMs as a mutator operator, allows for a much wider and flexible search space; e.g., over all possible python functions within a certain FLOP budget, eliminating the need for manually constructed search spaces. In addition, these pipelines will be biased towards meaningful activation functions, given their ability to represent common knowledge, leading to a potentially more efficient search of the space. The second observation is that, through this framework, one can target not only performance improvements but also activation functions that encode particular inductive biases. This can be done by using performance on out-of-distribution data as a fitness function, reflecting the degree to which the architecture respects the inherent structure in the data in a manner independent of distribution shifts. We carry an empirical exploration of this proposal and show that relatively small scale synthetic datasets can be sufficient for AlphaEvolve to discover meaningful activations.
What makes a good feedforward computational graph?
Feb 10, 2025



As implied by the plethora of literature on graph rewiring, the choice of computational graph employed by a neural network can make a significant impact on its downstream performance. Certain effects related to the computational graph, such as under-reaching and over-squashing, may even render the model incapable of learning certain functions. Most of these effects have only been thoroughly studied in the domain of undirected graphs; however, recent years have seen a significant rise in interest in feedforward computational graphs: directed graphs without any back edges. In this paper, we study the desirable properties of a feedforward computational graph, discovering two important complementary measures: fidelity and mixing time, and evaluating a few popular choices of graphs through the lens of these measures. Our study is backed by both theoretical analyses of the metrics' asymptotic behaviour for various graphs, as well as correlating these metrics to the performance of trained neural network models using the corresponding graphs.
Amplifying human performance in combinatorial competitive programming
Nov 29, 2024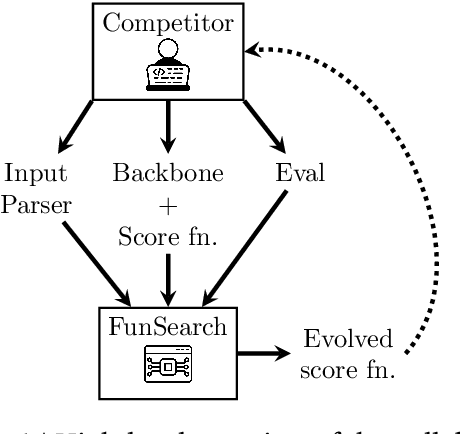

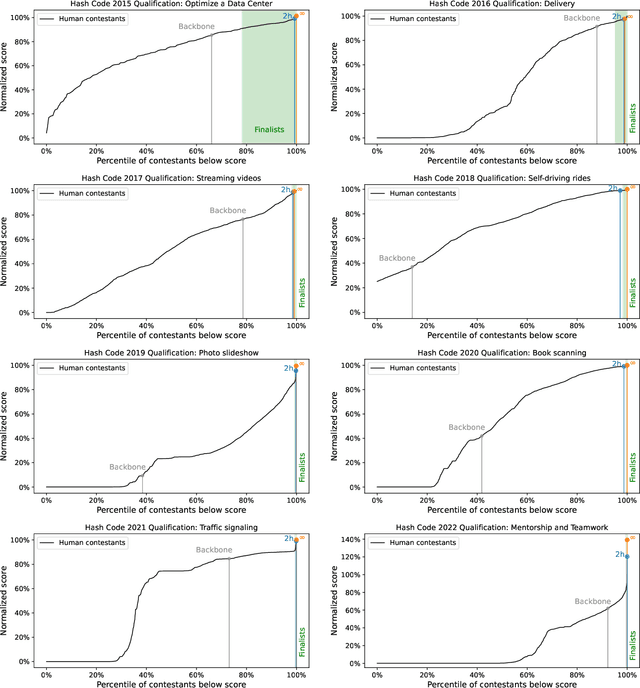
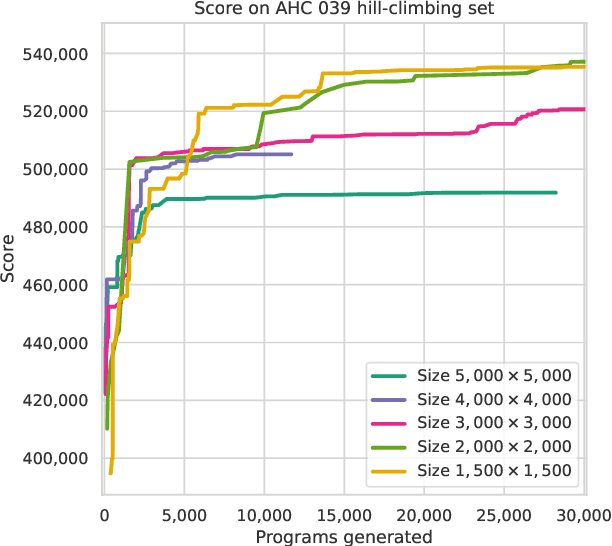
Recent years have seen a significant surge in complex AI systems for competitive programming, capable of performing at admirable levels against human competitors. While steady progress has been made, the highest percentiles still remain out of reach for these methods on standard competition platforms such as Codeforces. Here we instead focus on combinatorial competitive programming, where the target is to find as-good-as-possible solutions to otherwise computationally intractable problems, over specific given inputs. We hypothesise that this scenario offers a unique testbed for human-AI synergy, as human programmers can write a backbone of a heuristic solution, after which AI can be used to optimise the scoring function used by the heuristic. We deploy our approach on previous iterations of Hash Code, a global team programming competition inspired by NP-hard software engineering problems at Google, and we leverage FunSearch to evolve our scoring functions. Our evolved solutions significantly improve the attained scores from their baseline, successfully breaking into the top percentile on all previous Hash Code online qualification rounds, and outperforming the top human teams on several. Our method is also performant on an optimisation problem that featured in a recent held-out AtCoder contest.
Round and Round We Go! What makes Rotary Positional Encodings useful?
Oct 08, 2024Positional Encodings (PEs) are a critical component of Transformer-based Large Language Models (LLMs), providing the attention mechanism with important sequence-position information. One of the most popular types of encoding used today in LLMs are Rotary Positional Encodings (RoPE), that rotate the queries and keys based on their relative distance. A common belief is that RoPE is useful because it helps to decay token dependency as relative distance increases. In this work, we argue that this is unlikely to be the core reason. We study the internals of a trained Gemma 7B model to understand how RoPE is being used at a mechanical level. We find that Gemma learns to use RoPE to construct robust "positional" attention patterns by exploiting the highest frequencies. We also find that, in general, Gemma greatly prefers to use the lowest frequencies of RoPE, which we suspect are used to carry semantic information. We mathematically prove interesting behaviours of RoPE and conduct experiments to verify our findings, proposing a modification of RoPE that fixes some highlighted issues and improves performance. We believe that this work represents an interesting step in better understanding PEs in LLMs, which we believe holds crucial value for scaling LLMs to large sizes and context lengths.
Transformers meet Neural Algorithmic Reasoners
Jun 13, 2024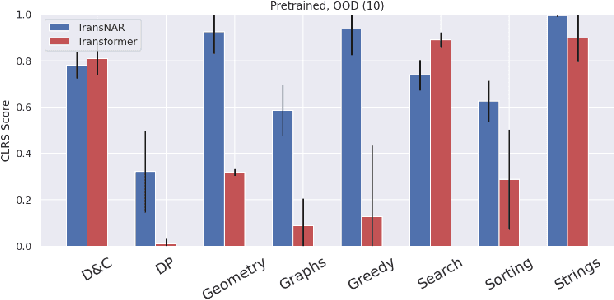
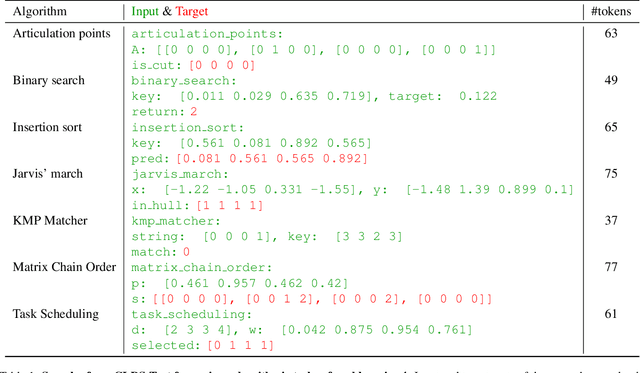
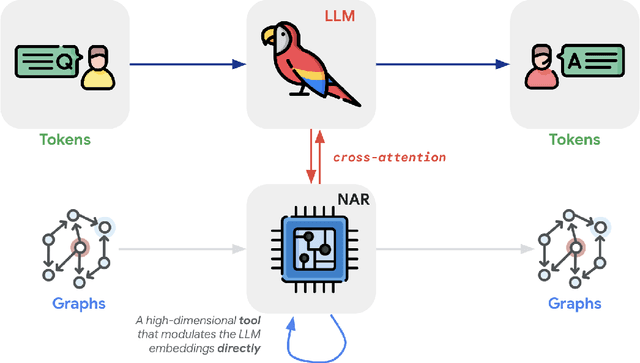
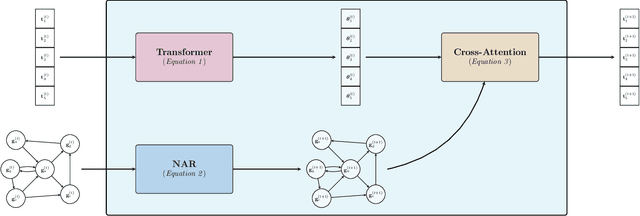
Transformers have revolutionized machine learning with their simple yet effective architecture. Pre-training Transformers on massive text datasets from the Internet has led to unmatched generalization for natural language understanding (NLU) tasks. However, such language models remain fragile when tasked with algorithmic forms of reasoning, where computations must be precise and robust. To address this limitation, we propose a novel approach that combines the Transformer's language understanding with the robustness of graph neural network (GNN)-based neural algorithmic reasoners (NARs). Such NARs proved effective as generic solvers for algorithmic tasks, when specified in graph form. To make their embeddings accessible to a Transformer, we propose a hybrid architecture with a two-phase training procedure, allowing the tokens in the language model to cross-attend to the node embeddings from the NAR. We evaluate our resulting TransNAR model on CLRS-Text, the text-based version of the CLRS-30 benchmark, and demonstrate significant gains over Transformer-only models for algorithmic reasoning, both in and out of distribution.
The CLRS-Text Algorithmic Reasoning Language Benchmark
Jun 06, 2024

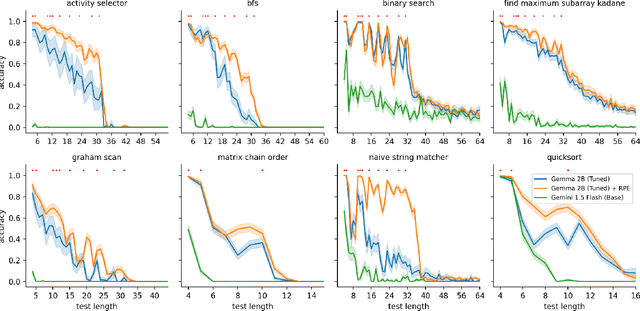
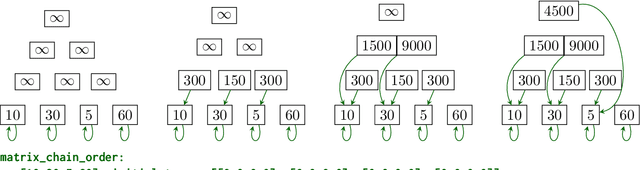
Eliciting reasoning capabilities from language models (LMs) is a critical direction on the path towards building intelligent systems. Most recent studies dedicated to reasoning focus on out-of-distribution performance on procedurally-generated synthetic benchmarks, bespoke-built to evaluate specific skills only. This trend makes results hard to transfer across publications, slowing down progress. Three years ago, a similar issue was identified and rectified in the field of neural algorithmic reasoning, with the advent of the CLRS benchmark. CLRS is a dataset generator comprising graph execution traces of classical algorithms from the Introduction to Algorithms textbook. Inspired by this, we propose CLRS-Text -- a textual version of these algorithmic traces. Out of the box, CLRS-Text is capable of procedurally generating trace data for thirty diverse, challenging algorithmic tasks across any desirable input distribution, while offering a standard pipeline in which any additional algorithmic tasks may be created in the benchmark. We fine-tune and evaluate various LMs as generalist executors on this benchmark, validating prior work and revealing a novel, interesting challenge for the LM reasoning community. Our code is available at https://github.com/google-deepmind/clrs/tree/master/clrs/_src/clrs_text.
Transformers need glasses! Information over-squashing in language tasks
Jun 06, 2024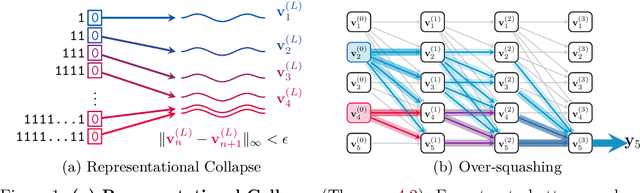

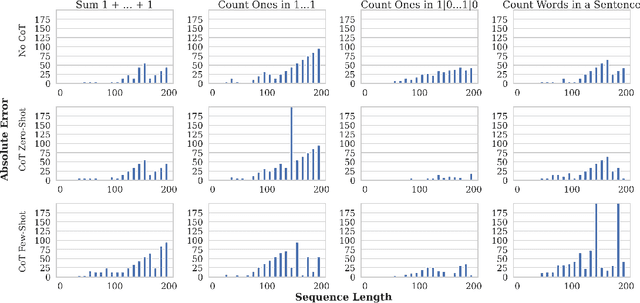
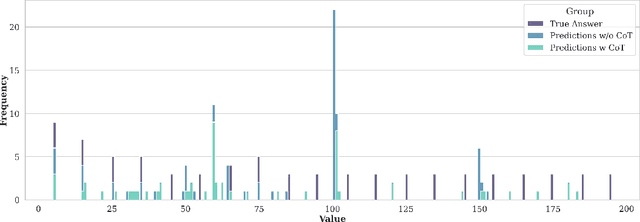
We study how information propagates in decoder-only Transformers, which are the architectural backbone of most existing frontier large language models (LLMs). We rely on a theoretical signal propagation analysis -- specifically, we analyse the representations of the last token in the final layer of the Transformer, as this is the representation used for next-token prediction. Our analysis reveals a representational collapse phenomenon: we prove that certain distinct sequences of inputs to the Transformer can yield arbitrarily close representations in the final token. This effect is exacerbated by the low-precision floating-point formats frequently used in modern LLMs. As a result, the model is provably unable to respond to these sequences in different ways -- leading to errors in, e.g., tasks involving counting or copying. Further, we show that decoder-only Transformer language models can lose sensitivity to specific tokens in the input, which relates to the well-known phenomenon of over-squashing in graph neural networks. We provide empirical evidence supporting our claims on contemporary LLMs. Our theory also points to simple solutions towards ameliorating these issues.
A Generalist Neural Algorithmic Learner
Sep 22, 2022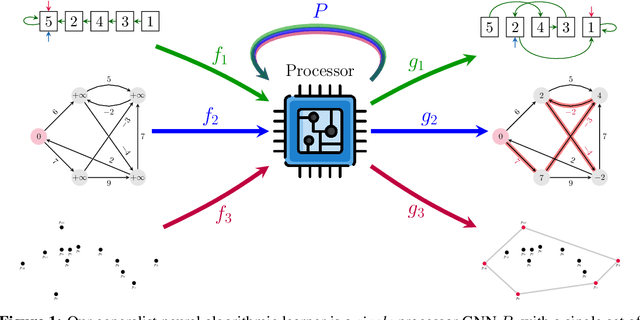
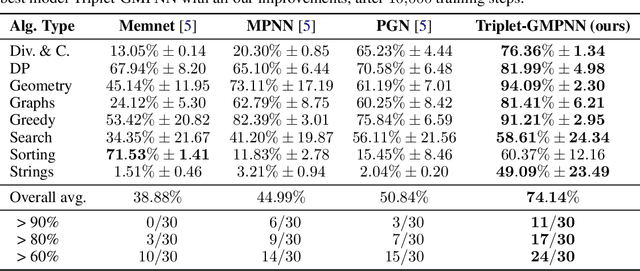
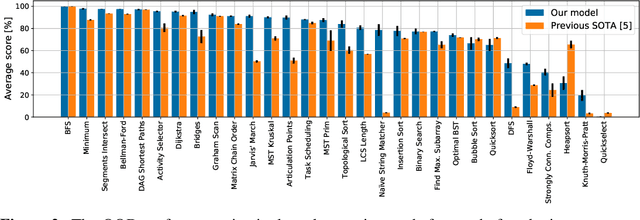
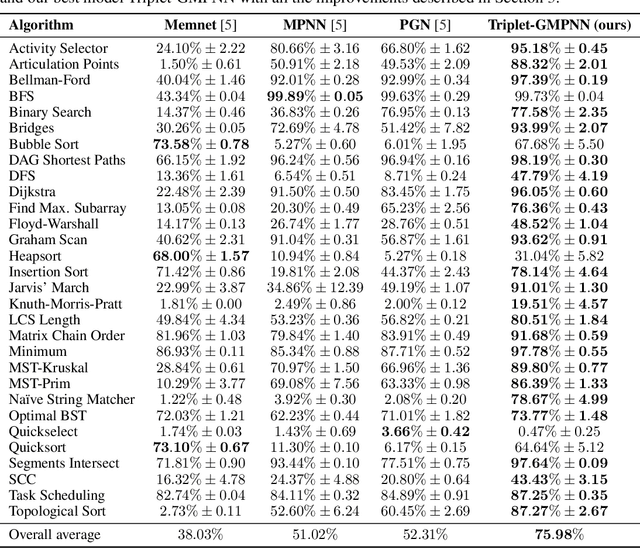
The cornerstone of neural algorithmic reasoning is the ability to solve algorithmic tasks, especially in a way that generalises out of distribution. While recent years have seen a surge in methodological improvements in this area, they mostly focused on building specialist models. Specialist models are capable of learning to neurally execute either only one algorithm or a collection of algorithms with identical control-flow backbone. Here, instead, we focus on constructing a generalist neural algorithmic learner -- a single graph neural network processor capable of learning to execute a wide range of algorithms, such as sorting, searching, dynamic programming, path-finding and geometry. We leverage the CLRS benchmark to empirically show that, much like recent successes in the domain of perception, generalist algorithmic learners can be built by "incorporating" knowledge. That is, it is possible to effectively learn algorithms in a multi-task manner, so long as we can learn to execute them well in a single-task regime. Motivated by this, we present a series of improvements to the input representation, training regime and processor architecture over CLRS, improving average single-task performance by over 20% from prior art. We then conduct a thorough ablation of multi-task learners leveraging these improvements. Our results demonstrate a generalist learner that effectively incorporates knowledge captured by specialist models.
Coverage as a Principle for Discovering Transferable Behavior in Reinforcement Learning
Feb 24, 2021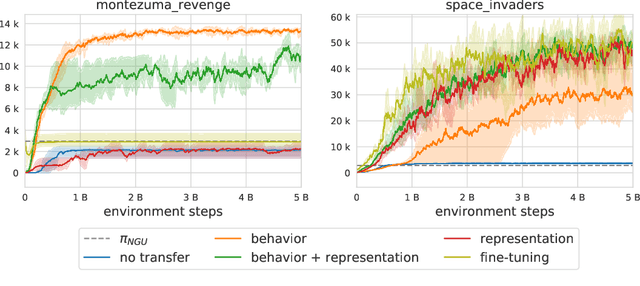
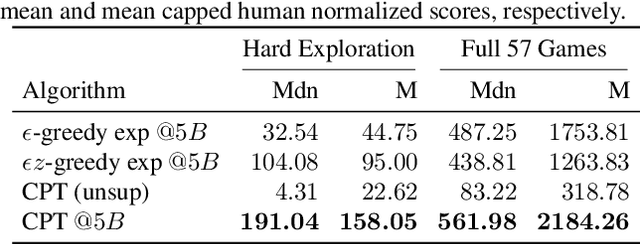
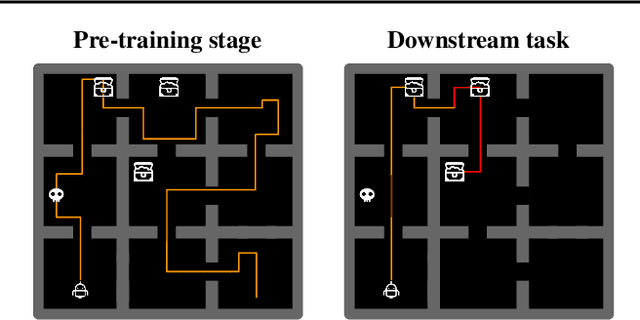
Designing agents that acquire knowledge autonomously and use it to solve new tasks efficiently is an important challenge in reinforcement learning, and unsupervised learning provides a useful paradigm for autonomous acquisition of task-agnostic knowledge. In supervised settings, representations discovered through unsupervised pre-training offer important benefits when transferred to downstream tasks. Given the nature of the reinforcement learning problem, we argue that representation alone is not enough for efficient transfer in challenging domains and explore how to transfer knowledge through behavior. The behavior of pre-trained policies may be used for solving the task at hand (exploitation), as well as for collecting useful data to solve the problem (exploration). We argue that policies pre-trained to maximize coverage will produce behavior that is useful for both strategies. When using these policies for both exploitation and exploration, our agents discover better solutions. The largest gains are generally observed in domains requiring structured exploration, including settings where the behavior of the pre-trained policies is misaligned with the downstream task.
Agent57: Outperforming the Atari Human Benchmark
Mar 30, 2020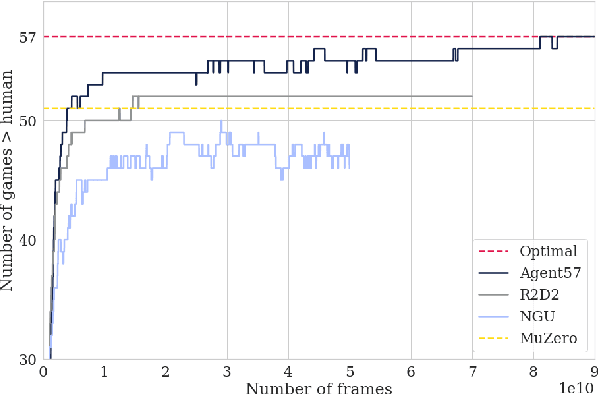
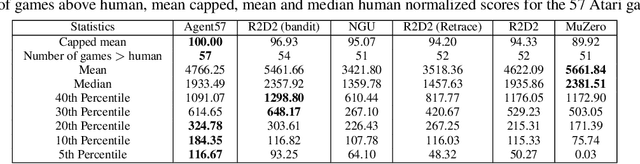
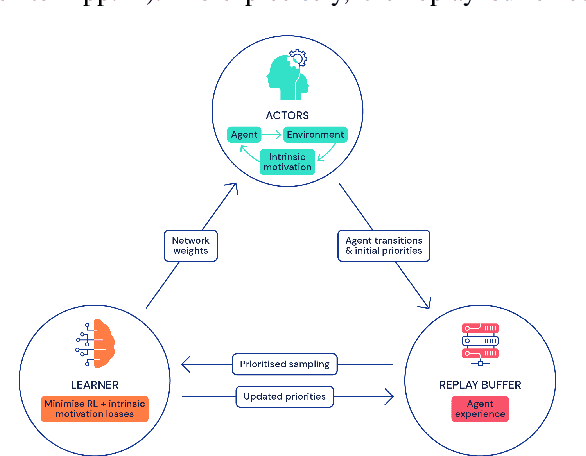

Atari games have been a long-standing benchmark in the reinforcement learning (RL) community for the past decade. This benchmark was proposed to test general competency of RL algorithms. Previous work has achieved good average performance by doing outstandingly well on many games of the set, but very poorly in several of the most challenging games. We propose Agent57, the first deep RL agent that outperforms the standard human benchmark on all 57 Atari games. To achieve this result, we train a neural network which parameterizes a family of policies ranging from very exploratory to purely exploitative. We propose an adaptive mechanism to choose which policy to prioritize throughout the training process. Additionally, we utilize a novel parameterization of the architecture that allows for more consistent and stable learning.