 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyclicJudge: Mitigating Judge Bias Efficiently in LLM-based Evaluation
Mar 02, 2026LLM-as-judge evaluation has become standard practice for open-ended model assessment; however, judges exhibit systematic biases that cannot be eliminated by increasing the number of scenarios or generations. These biases are often similar in magnitude to the model differences that benchmarks are designed to detect, resulting in unreliable rankings when single-judge evaluations are used. This work introduces a variance decomposition that partitions benchmark score variance into scenario, generation, judge, and residual components. Based on this analysis, CyclicJudge, a round-robin assignment of judges, is demonstrated to be the optimal allocation strategy. It eliminates bias precisely while requiring each judge only once per cycle, maintaining the cost of single-judge evaluation. Empirical validation on MT-Bench supports all theoretical predictions.
Beyond Simulations: What 20,000 Real Conversations Reveal About Mental Health AI Safety
Jan 14, 2026Large language models (LLMs) are increasingly used for mental health support, yet existing safety evaluations rely primarily on small, simulation-based test sets that have an unknown relationship to the linguistic distribution of real usage. In this study, we present replications of four published safety test sets targeting suicide risk assessment, harmful content generation, refusal robustness, and adversarial jailbreaks for a leading frontier generic AI model alongside an AI purpose built for mental health support. We then propose and conduct an ecological audit on over 20,000 real-world user conversations with the purpose-built AI designed with layered suicide and non-suicidal self-injury (NSSI) safeguards to compare test set performance to real world performance. While the purpose-built AI was significantly less likely than general-purpose LLMs to produce enabling or harmful content across suicide/NSSI (.4-11.27% vs 29.0-54.4%), eating disorder (8.4% vs 54.0%), and substance use (9.9% vs 45.0%) benchmark prompts, test set failure rates for suicide/NSSI were far higher than in real-world deployment. Clinician review of flagged conversations from the ecological audit identified zero cases of suicide risk that failed to receive crisis resources. Across all 20,000 conversations, three mentions of NSSI risk (.015%) did not trigger a crisis intervention; among sessions flagged by the LLM judge, this corresponds to an end-to-end system false negative rate of .38%, providing a lower bound on real-world safety failures. These findings support a shift toward continuous, deployment-relevant safety assurance for AI mental-health systems rather than limited set benchmark certification.
Adversarial Training for Failure-Sensitive User Simulation in Mental Health Dialogue Optimization
Dec 23, 2025Realistic user simulation is crucial for training and evaluating task-oriented dialogue (TOD) systems, yet creating simulators that accurately replicate human behavior remains challenging. A key property of effective simulators is their ability to expose failure modes of the systems they evaluate. We present an adversarial training framework that iteratively improves user simulator realism through a competitive dynamic between a generator (user simulator) and a discriminator. Applied to mental health support chatbots, our approach demonstrates that fine-tuned simulators dramatically outperform zero-shot base models at surfacing system issues, and adversarial training further enhances diversity, distributional alignment, and predictive validity. The resulting simulator achieves a strong correlation between simulated and real failure occurrence rates across diverse chatbot configurations while maintaining low distributional divergence of failure modes. Discriminator accuracy decreases drastically after three adversarial iterations, suggesting improved realism. These results provide evidence that adversarial training is a promising approach for creating realistic user simulators in mental health support TOD domains, enabling rapid, reliable, and cost-effective system evaluation before deployment.
Large-Scale Retrieval for Reinforcement Learning
Jun 10, 2022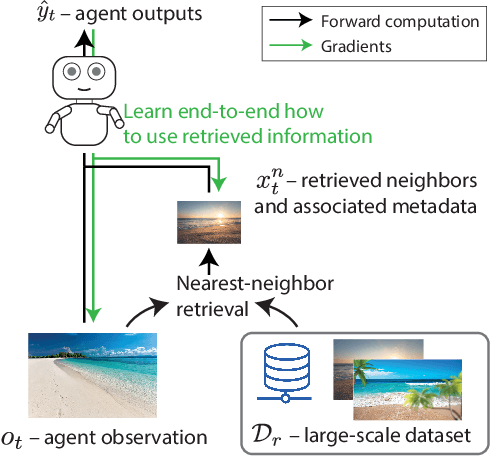
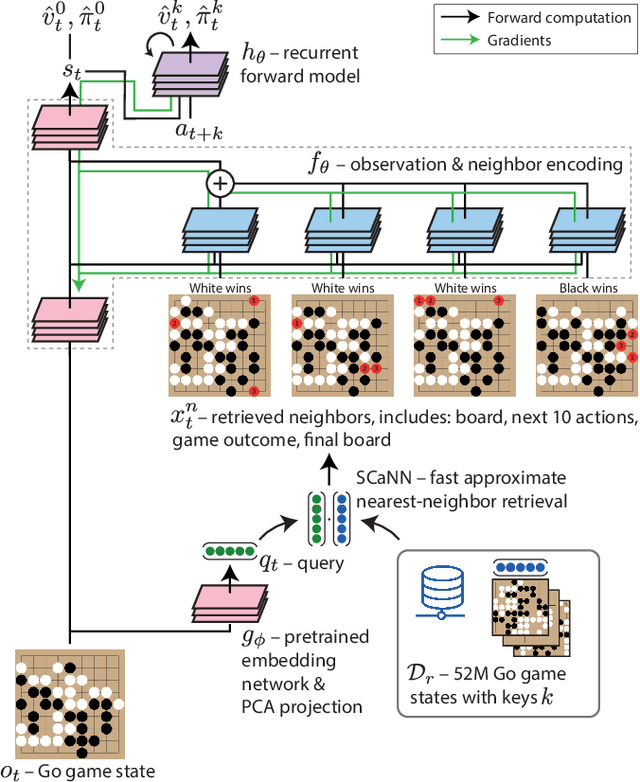
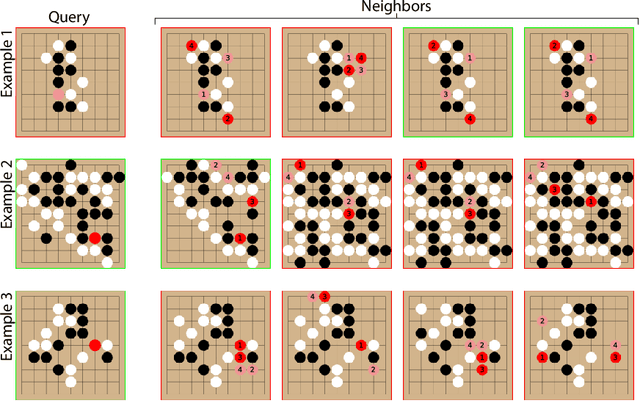
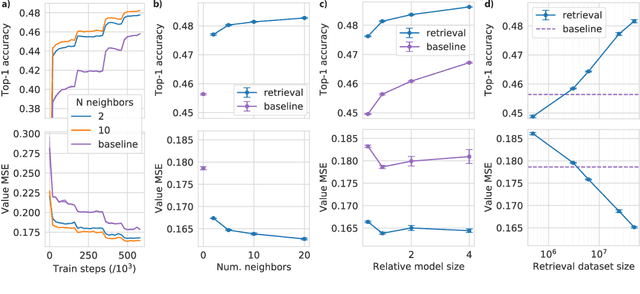
Effective decision making involves flexibly relating past experiences and relevant contextual information to a novel situation. In deep reinforcement learning, the dominant paradigm is for an agent to amortise information that helps decision-making into its network weights via gradient descent on training losses. Here, we pursue an alternative approach in which agents can utilise large-scale context-sensitive database lookups to support their parametric computations. This allows agents to directly learn in an end-to-end manner to utilise relevant information to inform their outputs. In addition, new information can be attended to by the agent, without retraining, by simply augmenting the retrieval dataset. We study this approach in Go, a challenging game for which the vast combinatorial state space privileges generalisation over direct matching to past experiences. We leverage fast, approximate nearest neighbor techniques in order to retrieve relevant data from a set of tens of millions of expert demonstration states. Attending to this information provides a significant boost to prediction accuracy and game-play performance over simply using these demonstrations as training trajectories, providing a compelling demonstration of the value of large-scale retrieval in reinforcement learning agents.
Formalising Concepts as Grounded Abstractions
Jan 13, 2021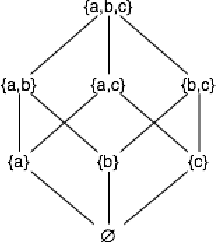
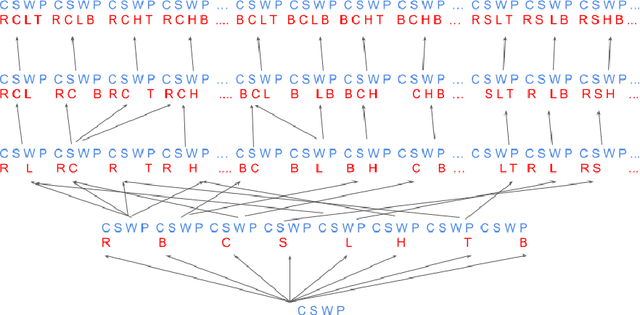
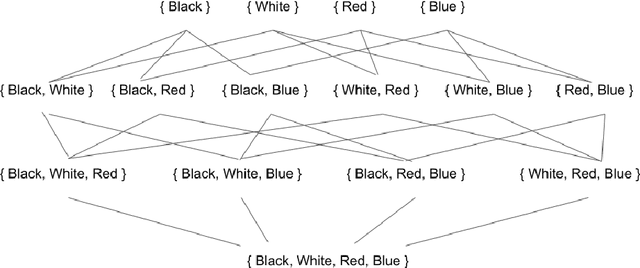
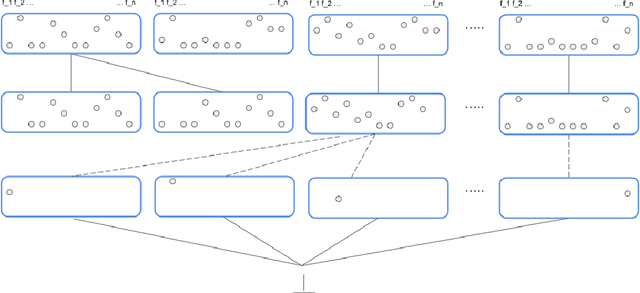
The notion of concept has been studied for centuries, by philosophers, linguists, cognitive scientists, and researchers in artificial intelligence (Margolis & Laurence, 1999). There is a large literature on formal, mathematical models of concepts, including a whole sub-field of AI -- Formal Concept Analysis -- devoted to this topic (Ganter & Obiedkov, 2016). Recently, researchers in machine learning have begun to investigate how methods from representation learning can be used to induce concepts from raw perceptual data (Higgins, Sonnerat, et al., 2018). The goal of this report is to provide a formal account of concepts which is compatible with this latest work in deep learning. The main technical goal of this report is to show how techniques from representation learning can be married with a lattice-theoretic formulation of conceptual spaces. The mathematics of partial orders and lattices is a standard tool for modelling conceptual spaces (Ch.2, Mitchell (1997), Ganter and Obiedkov (2016)); however, there is no formal work that we are aware of which defines a conceptual lattice on top of a representation that is induced using unsupervised deep learning (Goodfellow et al., 2016). The advantages of partially-ordered lattice structures are that these provide natural mechanisms for use in concept discovery algorithms, through the meets and joins of the lattice.
Grounded Language Learning Fast and Slow
Sep 15, 2020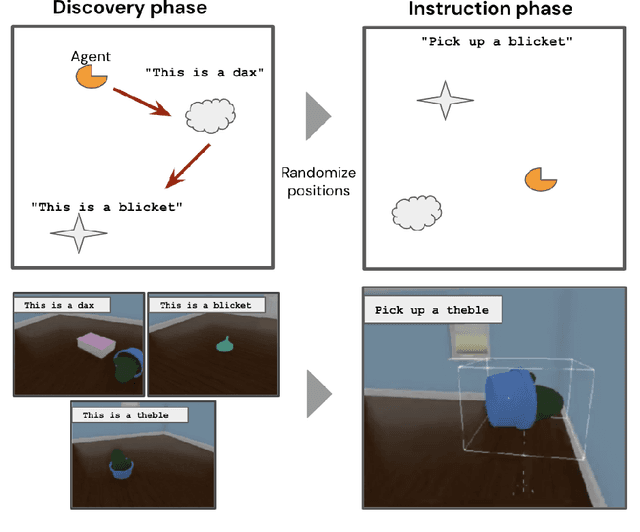
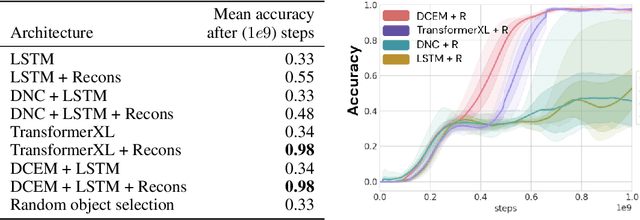
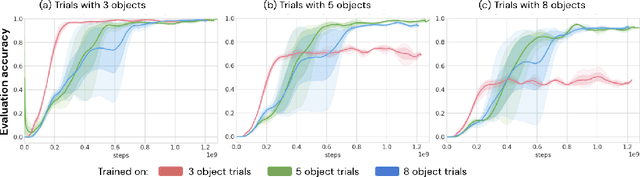
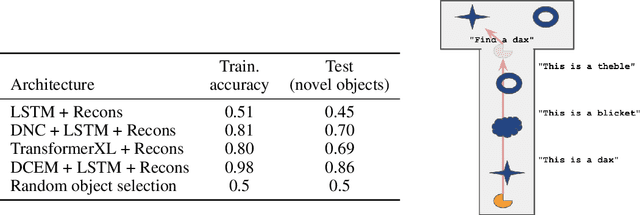
Recent work has shown that large text-based neural language models, trained with conventional supervised learning objectives, acquire a surprising propensity for few- and one-shot learning. Here, we show that an embodied agent situated in a simulated 3D world, and endowed with a novel dual-coding external memory, can exhibit similar one-shot word learning when trained with conventional reinforcement learning algorithms. After a single introduction to a novel object via continuous visual perception and a language prompt ("This is a dax"), the agent can re-identify the object and manipulate it as instructed ("Put the dax on the bed"). In doing so, it seamlessly integrates short-term, within-episode knowledge of the appropriate referent for the word "dax" with long-term lexical and motor knowledge acquired across episodes (i.e. "bed" and "putting"). We find that, under certain training conditions and with a particular memory writing mechanism, the agent's one-shot word-object binding generalizes to novel exemplars within the same ShapeNet category, and is effective in settings with unfamiliar numbers of objects. We further show how dual-coding memory can be exploited as a signal for intrinsic motivation, stimulating the agent to seek names for objects that may be useful for later executing instructions. Together, the results demonstrate that deep neural networks can exploit meta-learning, episodic memory and an explicitly multi-modal environment to account for 'fast-mapping', a fundamental pillar of human cognitive development and a potentially transformative capacity for agents that interact with human users.
Multi-agent Communication meets Natural Language: Synergies between Functional and Structural Language Learning
May 14, 2020
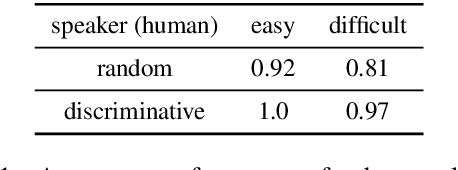
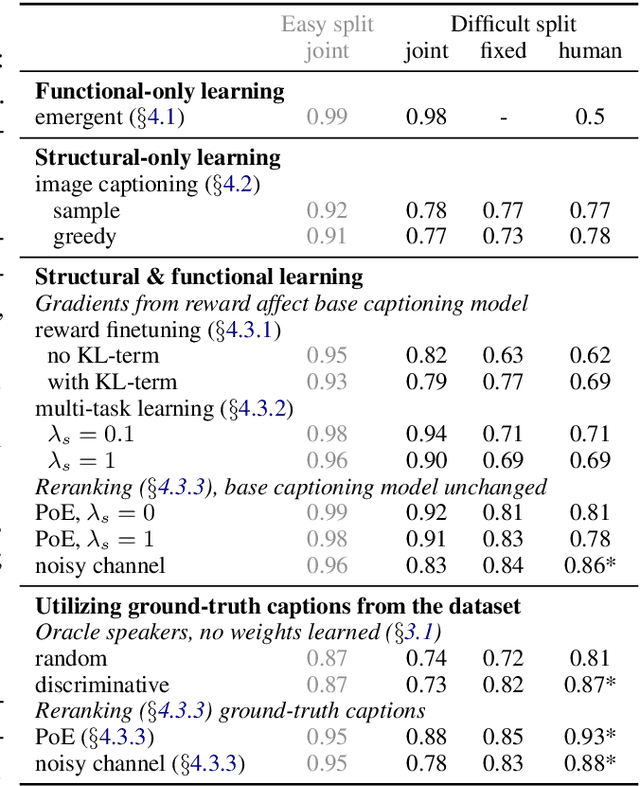
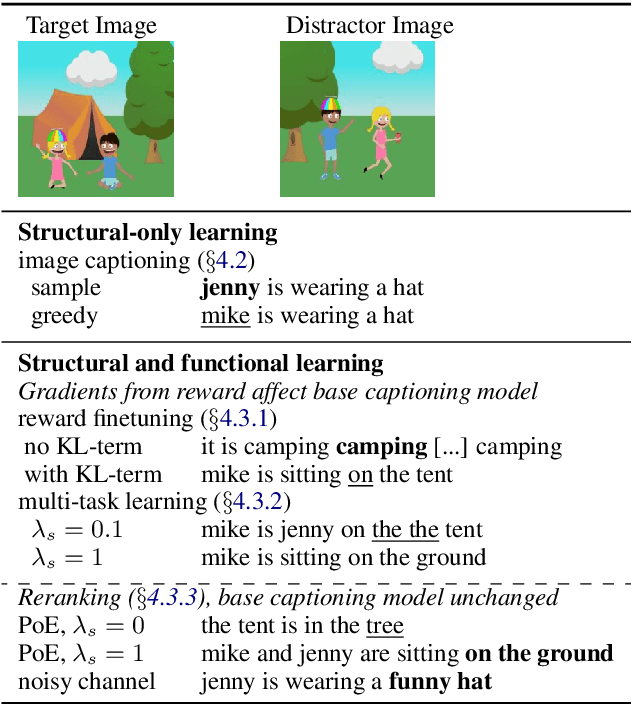
We present a method for combining multi-agent communication and traditional data-driven approaches to natural language learning, with an end goal of teaching agents to communicate with humans in natural language. Our starting point is a language model that has been trained on generic, not task-specific language data. We then place this model in a multi-agent self-play environment that generates task-specific rewards used to adapt or modulate the model, turning it into a task-conditional language model. We introduce a new way for combining the two types of learning based on the idea of reranking language model samples, and show that this method outperforms others in communicating with humans in a visual referential communication task. Finally, we present a taxonomy of different types of language drift that can occur alongside a set of measures to detect them.
Never Give Up: Learning Directed Exploration Strategies
Feb 14, 2020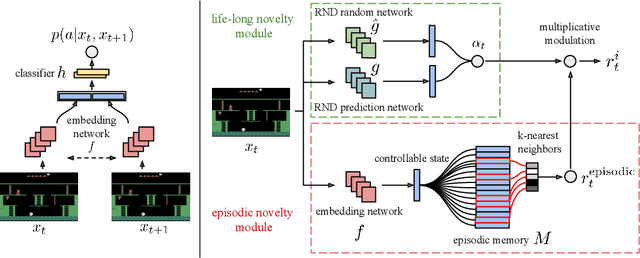
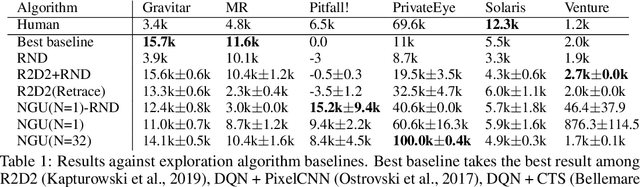
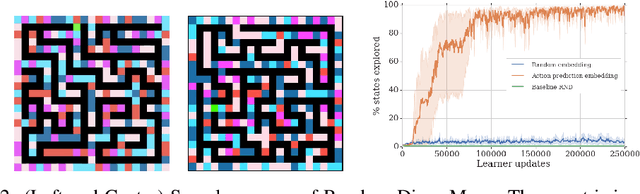
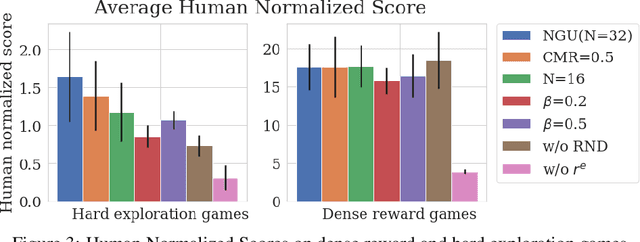
We propose a reinforcement learning agent to solve hard exploration games by learning a range of directed exploratory policies. We construct an episodic memory-based intrinsic reward using k-nearest neighbors over the agent's recent experience to train the directed exploratory policies, thereby encouraging the agent to repeatedly revisit all states in its environment. A self-supervised inverse dynamics model is used to train the embeddings of the nearest neighbour lookup, biasing the novelty signal towards what the agent can control. We employ the framework of Universal Value Function Approximators (UVFA) to simultaneously learn many directed exploration policies with the same neural network, with different trade-offs between exploration and exploitation. By using the same neural network for different degrees of exploration/exploitation, transfer is demonstrated from predominantly exploratory policies yielding effective exploitative policies. The proposed method can be incorporated to run with modern distributed RL agents that collect large amounts of experience from many actors running in parallel on separate environment instances. Our method doubles the performance of the base agent in all hard exploration in the Atari-57 suite while maintaining a very high score across the remaining games, obtaining a median human normalised score of 1344.0%. Notably, the proposed method is the first algorithm to achieve non-zero rewards (with a mean score of 8,400) in the game of Pitfall! without using demonstrations or hand-crafted features.
Shaping representations through communication: community size effect in artificial learning systems
Dec 12, 2019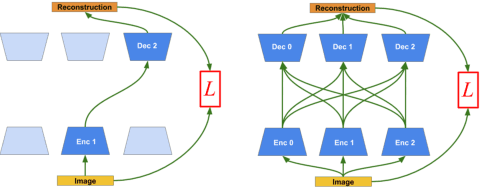
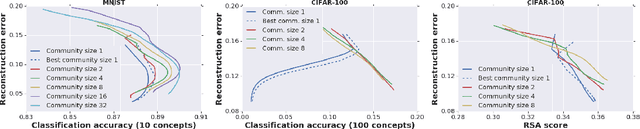

Motivated by theories of language and communication that explain why communities with large numbers of speakers have, on average, simpler languages with more regularity, we cast the representation learning problem in terms of learning to communicate. Our starting point sees the traditional autoencoder setup as a single encoder with a fixed decoder partner that must learn to communicate. Generalizing from there, we introduce community-based autoencoders in which multiple encoders and decoders collectively learn representations by being randomly paired up on successive training iterations. We find that increasing community sizes reduce idiosyncrasies in the learned codes, resulting in representations that better encode concept categories and correlate with human feature norms.
A Factorial Mixture Prior for Compositional Deep Generative Models
Dec 18, 2018

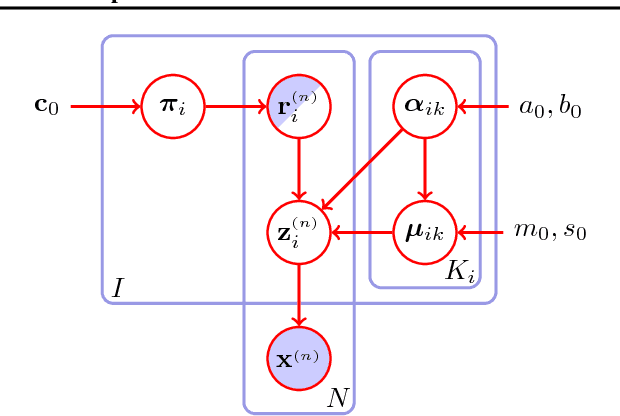
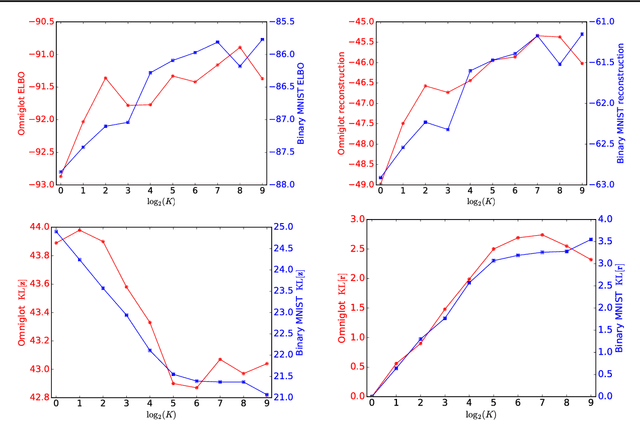
We assume that a high-dimensional datum, like an image, is a compositional expression of a set of properties, with a complicated non-linear relationship between the datum and its properties. This paper proposes a factorial mixture prior for capturing latent properties, thereby adding structured compositionality to deep generative models. The prior treats a latent vector as belonging to Cartesian product of subspaces, each of which is quantized separately with a Gaussian mixture model. Some mixture components can be set to represent properties as observed random variables whenever labeled properties are present. Through a combination of stochastic variational inference and gradient descent, a method for learning how to infer discrete properties in an unsupervised or semi-supervised way is outlined and empirically evaluated.