 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
GraphCast: Learning skillful medium-range global weather forecasting
Dec 24, 2022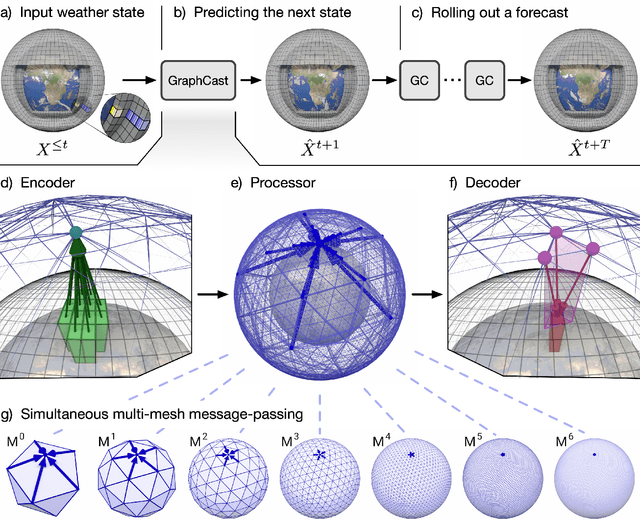
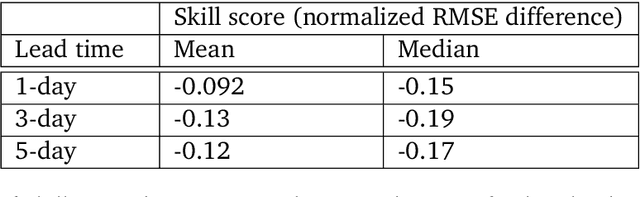
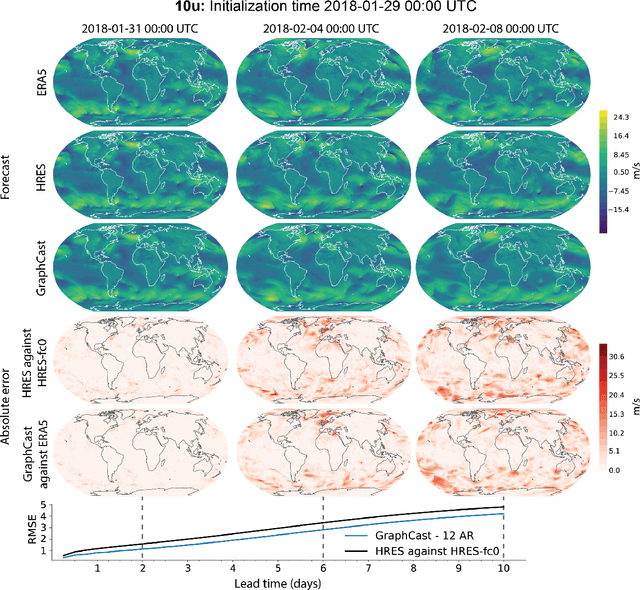
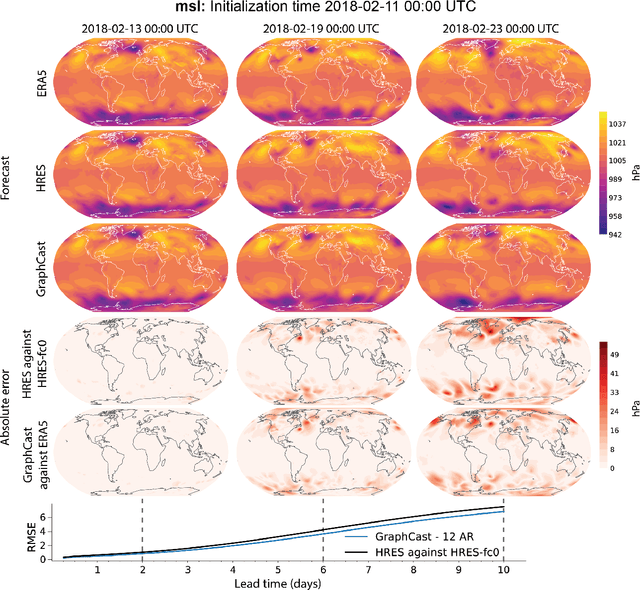
We introduce a machine-learning (ML)-based weather simulator--called "GraphCast"--which outperforms the most accurate deterministic operational medium-range weather forecasting system in the world, as well as all previous ML baselines. GraphCast is an autoregressive model, based on graph neural networks and a novel high-resolution multi-scale mesh representation, which we trained on historical weather data from the European Centre for Medium-Range Weather Forecasts (ECMWF)'s ERA5 reanalysis archive. It can make 10-day forecasts, at 6-hour time intervals, of five surface variables and six atmospheric variables, each at 37 vertical pressure levels, on a 0.25-degree latitude-longitude grid, which corresponds to roughly 25 x 25 kilometer resolution at the equator. Our results show GraphCast is more accurate than ECMWF's deterministic operational forecasting system, HRES, on 90.0% of the 2760 variable and lead time combinations we evaluated. GraphCast also outperforms the most accurate previous ML-based weather forecasting model on 99.2% of the 252 targets it reported. GraphCast can generate a 10-day forecast (35 gigabytes of data) in under 60 seconds on Cloud TPU v4 hardware. Unlike traditional forecasting methods, ML-based forecasting scales well with data: by training on bigger, higher quality, and more recent data, the skill of the forecasts can improve. Together these results represent a key step forward in complementing and improving weather modeling with ML, open new opportunities for fast, accurate forecasting, and help realize the promise of ML-based simulation in the physical sciences.
MultiScale MeshGraphNets
Oct 02, 2022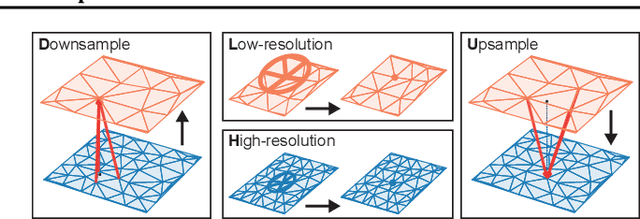
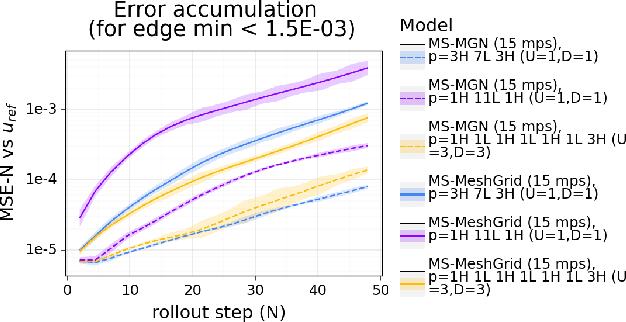
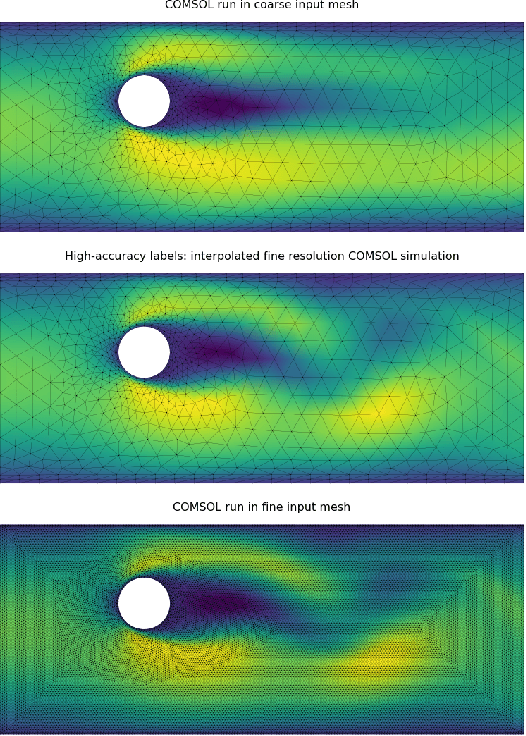
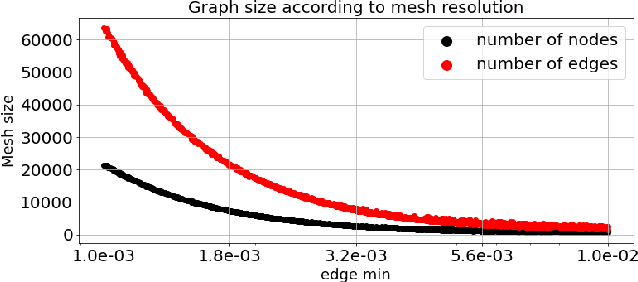
In recent years, there has been a growing interest in using machine learning to overcome the high cost of numerical simulation, with some learned models achieving impressive speed-ups over classical solvers whilst maintaining accuracy. However, these methods are usually tested at low-resolution settings, and it remains to be seen whether they can scale to the costly high-resolution simulations that we ultimately want to tackle. In this work, we propose two complementary approaches to improve the framework from MeshGraphNets, which demonstrated accurate predictions in a broad range of physical systems. MeshGraphNets relies on a message passing graph neural network to propagate information, and this structure becomes a limiting factor for high-resolution simulations, as equally distant points in space become further apart in graph space. First, we demonstrate that it is possible to learn accurate surrogate dynamics of a high-resolution system on a much coarser mesh, both removing the message passing bottleneck and improving performance; and second, we introduce a hierarchical approach (MultiScale MeshGraphNets) which passes messages on two different resolutions (fine and coarse), significantly improving the accuracy of MeshGraphNets while requiring less computational resources.
Normalizing flows for atomic solids
Nov 16, 2021
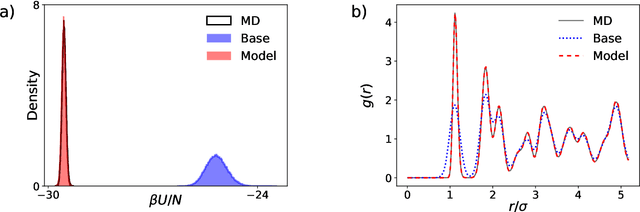
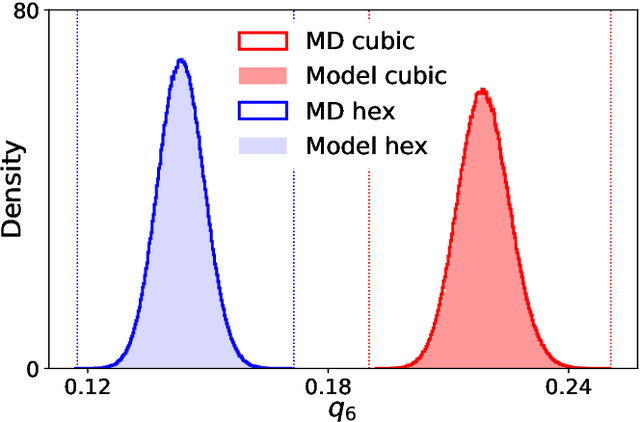
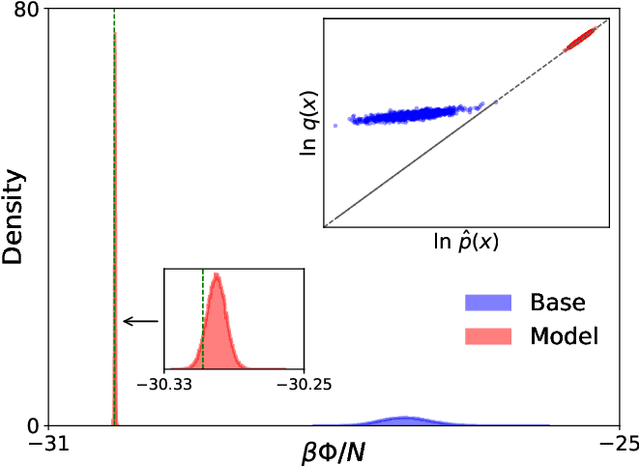
We present a machine-learning approach, based on normalizing flows, for modelling atomic solids. Our model transforms an analytically tractable base distribution into the target solid without requiring ground-truth samples for training. We report Helmholtz free energy estimates for cubic and hexagonal ice modelled as monatomic water as well as for a truncated and shifted Lennard-Jones system, and find them to be in excellent agreement with literature values and with estimates from established baseline methods. We further investigate structural properties and show that the model samples are nearly indistinguishable from the ones obtained with molecular dynamics. Our results thus demonstrate that normalizing flows can provide high-quality samples and free energy estimates of solids, without the need for multi-staging or for imposing restrictions on the crystal geometry.
Never Give Up: Learning Directed Exploration Strategies
Feb 14, 2020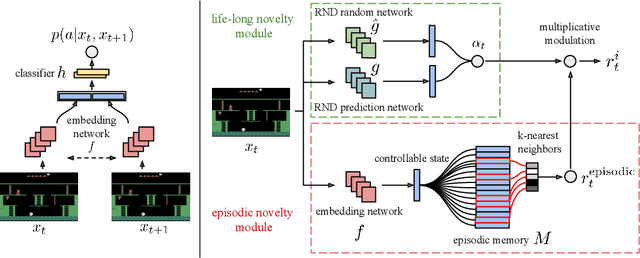
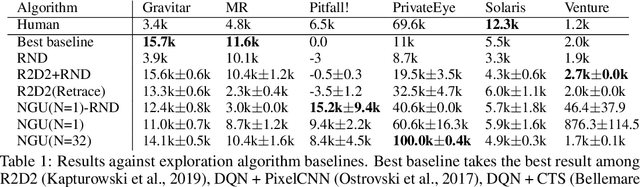
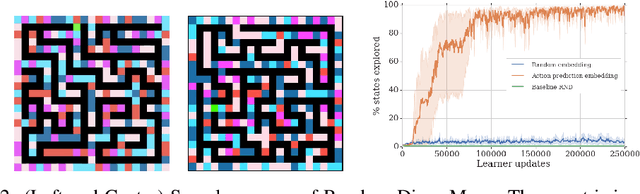
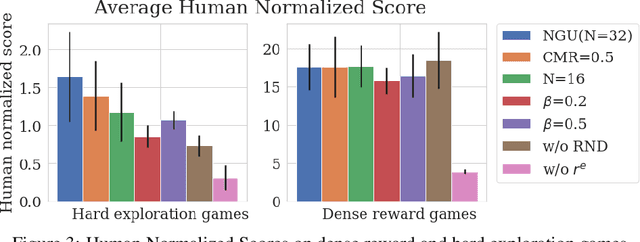
We propose a reinforcement learning agent to solve hard exploration games by learning a range of directed exploratory policies. We construct an episodic memory-based intrinsic reward using k-nearest neighbors over the agent's recent experience to train the directed exploratory policies, thereby encouraging the agent to repeatedly revisit all states in its environment. A self-supervised inverse dynamics model is used to train the embeddings of the nearest neighbour lookup, biasing the novelty signal towards what the agent can control. We employ the framework of Universal Value Function Approximators (UVFA) to simultaneously learn many directed exploration policies with the same neural network, with different trade-offs between exploration and exploitation. By using the same neural network for different degrees of exploration/exploitation, transfer is demonstrated from predominantly exploratory policies yielding effective exploitative policies. The proposed method can be incorporated to run with modern distributed RL agents that collect large amounts of experience from many actors running in parallel on separate environment instances. Our method doubles the performance of the base agent in all hard exploration in the Atari-57 suite while maintaining a very high score across the remaining games, obtaining a median human normalised score of 1344.0%. Notably, the proposed method is the first algorithm to achieve non-zero rewards (with a mean score of 8,400) in the game of Pitfall! without using demonstrations or hand-crafted features.
Targeted free energy estimation via learned mappings
Feb 12, 2020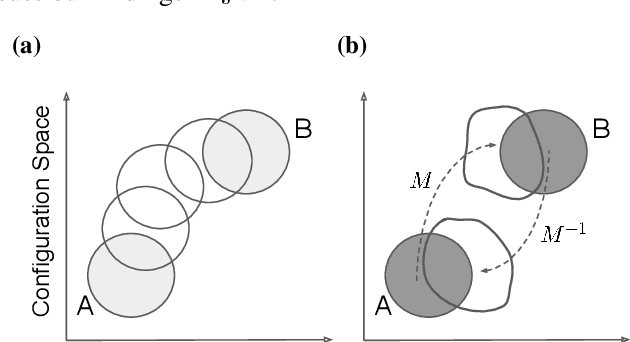
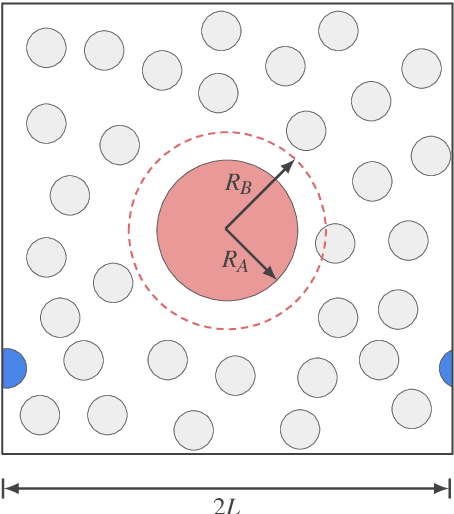
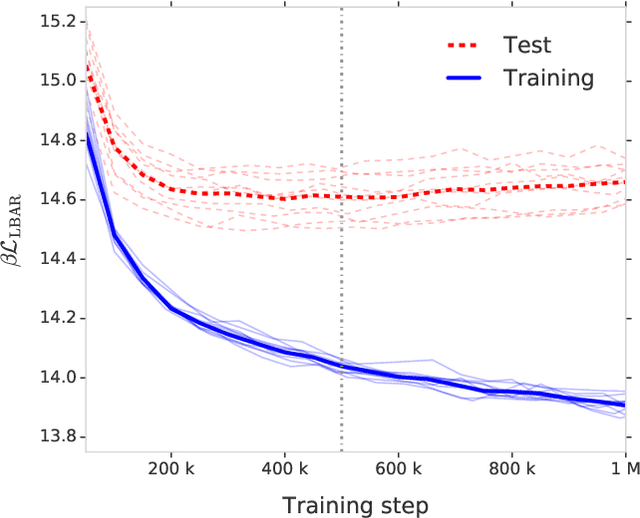
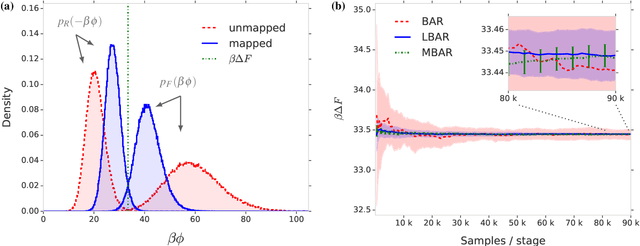
Free energy perturbation (FEP) was proposed by Zwanzig more than six decades ago as a method to estimate free energy differences, and has since inspired a huge body of related methods that use it as an integral building block. Being an importance sampling based estimator, however, FEP suffers from a severe limitation: the requirement of sufficient overlap between distributions. One strategy to mitigate this problem, called Targeted Free Energy Perturbation, uses a high-dimensional mapping in configuration space to increase overlap of the underlying distributions. Despite its potential, this method has attracted only limited attention due to the formidable challenge of formulating a tractable mapping. Here, we cast Targeted FEP as a machine learning (ML) problem in which the mapping is parameterized as a neural network that is optimized so as to increase overlap. We test our method on a fully-periodic solvation system, with a model that respects the inherent permutational and periodic symmetries of the problem. We demonstrate that our method leads to a substantial variance reduction in free energy estimates when compared against baselines.
Fast deep reinforcement learning using online adjustments from the past
Oct 18, 2018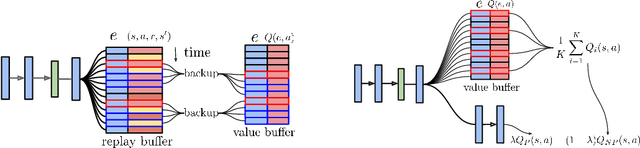
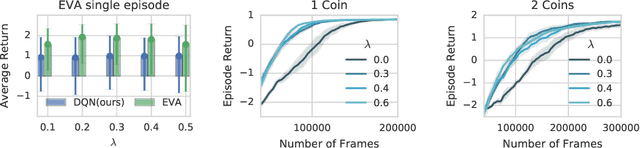
We propose Ephemeral Value Adjusments (EVA): a means of allowing deep reinforcement learning agents to rapidly adapt to experience in their replay buffer. EVA shifts the value predicted by a neural network with an estimate of the value function found by planning over experience tuples from the replay buffer near the current state. EVA combines a number of recent ideas around combining episodic memory-like structures into reinforcement learning agents: slot-based storage, content-based retrieval, and memory-based planning. We show that EVAis performant on a demonstration task and Atari games.
Generative Temporal Models with Spatial Memory for Partially Observed Environments
Jul 19, 2018



In model-based reinforcement learning, generative and temporal models of environments can be leveraged to boost agent performance, either by tuning the agent's representations during training or via use as part of an explicit planning mechanism. However, their application in practice has been limited to simplistic environments, due to the difficulty of training such models in larger, potentially partially-observed and 3D environments. In this work we introduce a novel action-conditioned generative model of such challenging environments. The model features a non-parametric spatial memory system in which we store learned, disentangled representations of the environment. Low-dimensional spatial updates are computed using a state-space model that makes use of knowledge on the prior dynamics of the moving agent, and high-dimensional visual observations are modelled with a Variational Auto-Encoder. The result is a scalable architecture capable of performing coherent predictions over hundreds of time steps across a range of partially observed 2D and 3D environments.
Meta-Learning by the Baldwin Effect
Jun 22, 2018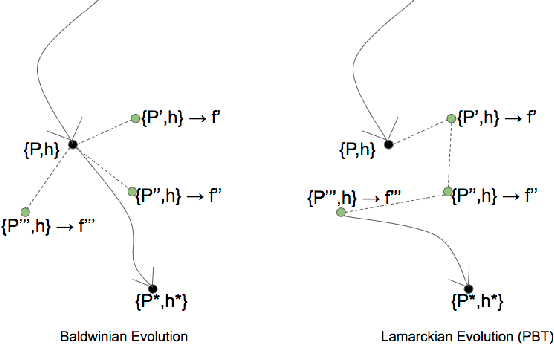
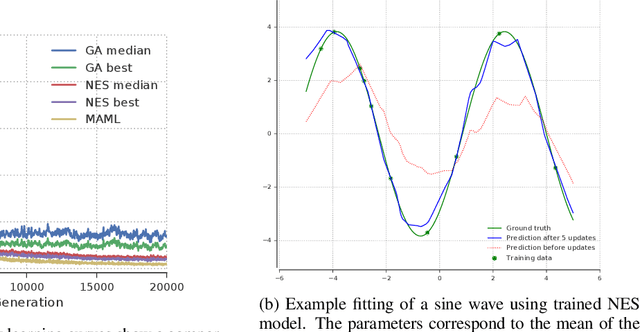
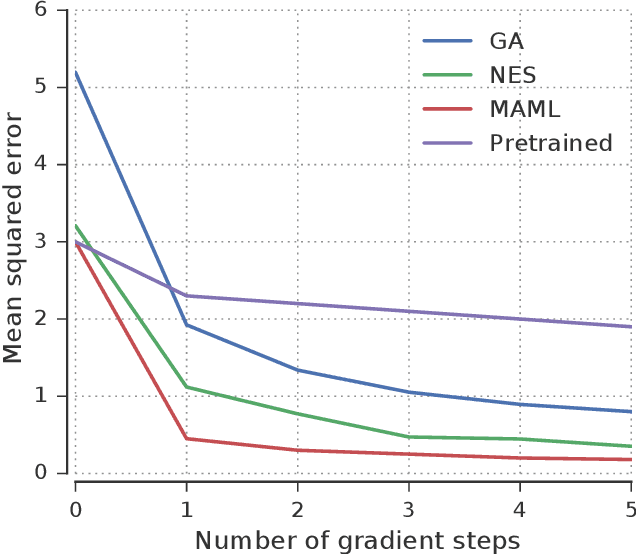
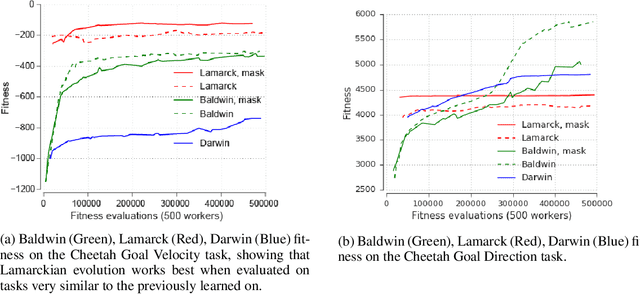
The scope of the Baldwin effect was recently called into question by two papers that closely examined the seminal work of Hinton and Nowlan. To this date there has been no demonstration of its necessity in empirically challenging tasks. Here we show that the Baldwin effect is capable of evolving few-shot supervised and reinforcement learning mechanisms, by shaping the hyperparameters and the initial parameters of deep learning algorithms. Furthermore it can genetically accommodate strong learning biases on the same set of problems as a recent machine learning algorithm called MAML "Model Agnostic Meta-Learning" which uses second-order gradients instead of evolution to learn a set of reference parameters (initial weights) that can allow rapid adaptation to tasks sampled from a distribution. Whilst in simple cases MAML is more data efficient than the Baldwin effect, the Baldwin effect is more general in that it does not require gradients to be backpropagated to the reference parameters or hyperparameters, and permits effectively any number of gradient updates in the inner loop. The Baldwin effect learns strong learning dependent biases, rather than purely genetically accommodating fixed behaviours in a learning independent manner.