 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenCast: Diffusion-based ensemble forecasting for medium-range weather
Dec 25, 2023



Probabilistic weather forecasting is critical for decision-making in high-impact domains such as flood forecasting, energy system planning or transportation routing, where quantifying the uncertainty of a forecast -- including probabilities of extreme events -- is essential to guide important cost-benefit trade-offs and mitigation measures. Traditional probabilistic approaches rely on producing ensembles from physics-based models, which sample from a joint distribution over spatio-temporally coherent weather trajectories, but are expensive to run. An efficient alternative is to use a machine learning (ML) forecast model to generate the ensemble, however state-of-the-art ML forecast models for medium-range weather are largely trained to produce deterministic forecasts which minimise mean-squared-error. Despite improving skills scores, they lack physical consistency, a limitation that grows at longer lead times and impacts their ability to characterize the joint distribution. We introduce GenCast, a ML-based generative model for ensemble weather forecasting, trained from reanalysis data. It forecasts ensembles of trajectories for 84 weather variables, for up to 15 days at 1 degree resolution globally, taking around a minute per ensemble member on a single Cloud TPU v4 device. We show that GenCast is more skillful than ENS, a top operational ensemble forecast, for more than 96\% of all 1320 verification targets on CRPS and Ensemble-Mean RMSE, while maintaining good reliability and physically consistent power spectra. Together our results demonstrate that ML-based probabilistic weather forecasting can now outperform traditional ensemble systems at 1 degree, opening new doors to skillful, fast weather forecasts that are useful in key applications.
AlphaStar Unplugged: Large-Scale Offline Reinforcement Learning
Aug 07, 2023



StarCraft II is one of the most challenging simulated reinforcement learning environments; it is partially observable, stochastic, multi-agent, and mastering StarCraft II requires strategic planning over long time horizons with real-time low-level execution. It also has an active professional competitive scene. StarCraft II is uniquely suited for advancing offline RL algorithms, both because of its challenging nature and because Blizzard has released a massive dataset of millions of StarCraft II games played by human players. This paper leverages that and establishes a benchmark, called AlphaStar Unplugged, introducing unprecedented challenges for offline reinforcement learning. We define a dataset (a subset of Blizzard's release), tools standardizing an API for machine learning methods, and an evaluation protocol. We also present baseline agents, including behavior cloning, offline variants of actor-critic and MuZero. We improve the state of the art of agents using only offline data, and we achieve 90% win rate against previously published AlphaStar behavior cloning agent.
Towards practical reinforcement learning for tokamak magnetic control
Jul 21, 2023



Reinforcement learning (RL) has shown promising results for real-time control systems, including the domain of plasma magnetic control. However, there are still significant drawbacks compared to traditional feedback control approaches for magnetic confinement. In this work, we address key drawbacks of the RL method; achieving higher control accuracy for desired plasma properties, reducing the steady-state error, and decreasing the required time to learn new tasks. We build on top of \cite{degrave2022magnetic}, and present algorithmic improvements to the agent architecture and training procedure. We present simulation results that show up to 65\% improvement in shape accuracy, achieve substantial reduction in the long-term bias of the plasma current, and additionally reduce the training time required to learn new tasks by a factor of 3 or more. We present new experiments using the upgraded RL-based controllers on the TCV tokamak, which validate the simulation results achieved, and point the way towards routinely achieving accurate discharges using the RL approach.
GraphCast: Learning skillful medium-range global weather forecasting
Dec 24, 2022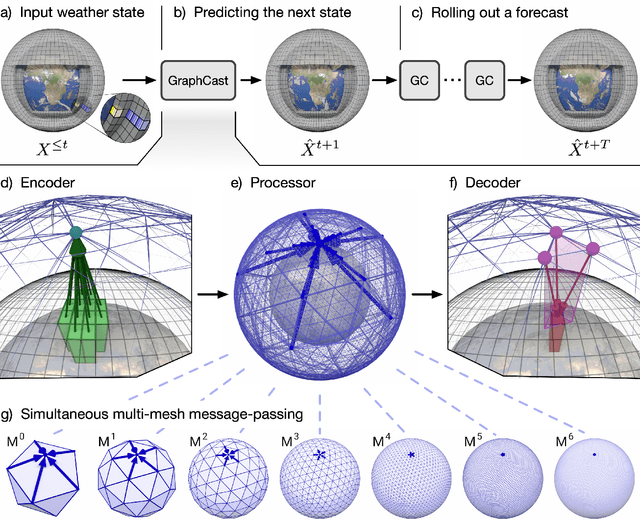
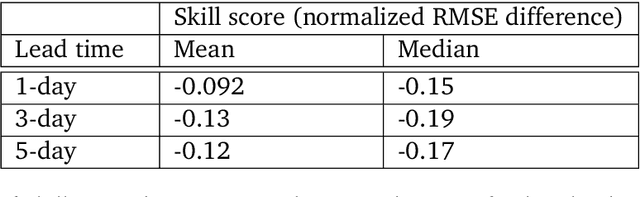
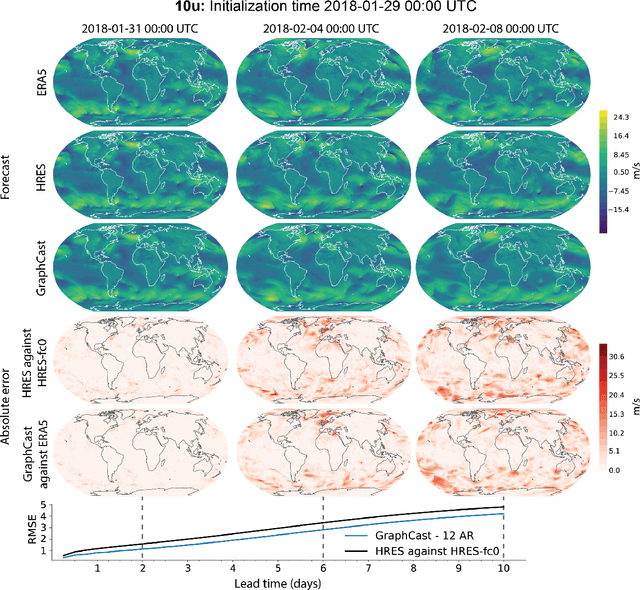
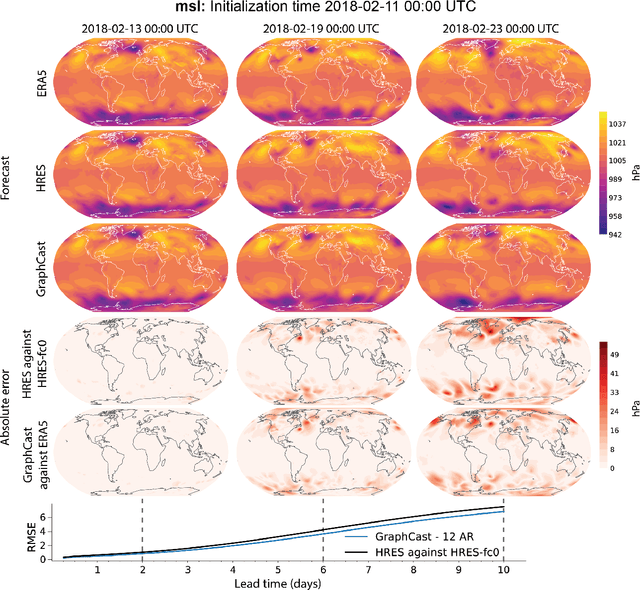
We introduce a machine-learning (ML)-based weather simulator--called "GraphCast"--which outperforms the most accurate deterministic operational medium-range weather forecasting system in the world, as well as all previous ML baselines. GraphCast is an autoregressive model, based on graph neural networks and a novel high-resolution multi-scale mesh representation, which we trained on historical weather data from the European Centre for Medium-Range Weather Forecasts (ECMWF)'s ERA5 reanalysis archive. It can make 10-day forecasts, at 6-hour time intervals, of five surface variables and six atmospheric variables, each at 37 vertical pressure levels, on a 0.25-degree latitude-longitude grid, which corresponds to roughly 25 x 25 kilometer resolution at the equator. Our results show GraphCast is more accurate than ECMWF's deterministic operational forecasting system, HRES, on 90.0% of the 2760 variable and lead time combinations we evaluated. GraphCast also outperforms the most accurate previous ML-based weather forecasting model on 99.2% of the 252 targets it reported. GraphCast can generate a 10-day forecast (35 gigabytes of data) in under 60 seconds on Cloud TPU v4 hardware. Unlike traditional forecasting methods, ML-based forecasting scales well with data: by training on bigger, higher quality, and more recent data, the skill of the forecasts can improve. Together these results represent a key step forward in complementing and improving weather modeling with ML, open new opportunities for fast, accurate forecasting, and help realize the promise of ML-based simulation in the physical sciences.
Improving alignment of dialogue agents via targeted human judgements
Sep 28, 2022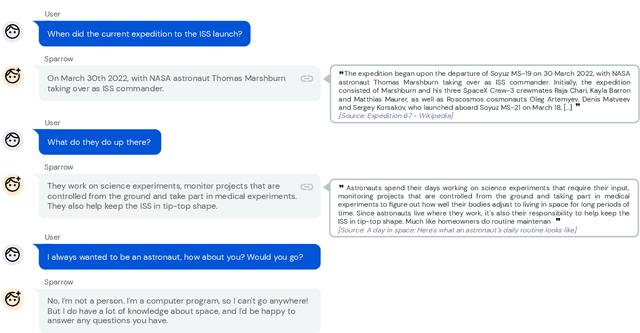

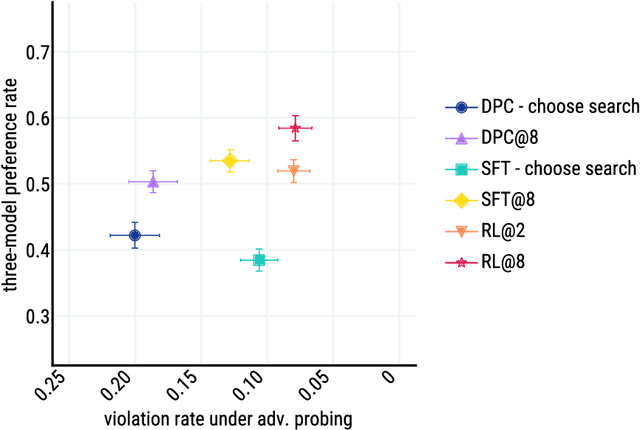
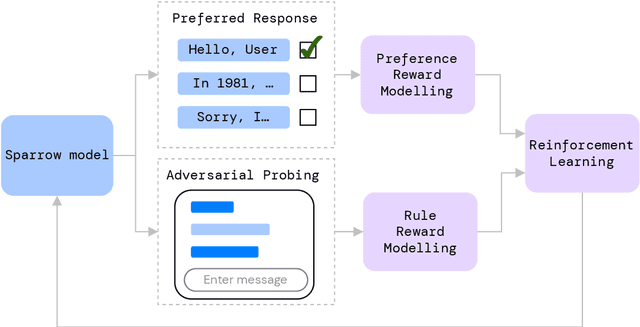
We present Sparrow, an information-seeking dialogue agent trained to be more helpful, correct, and harmless compared to prompted language model baselines. We use reinforcement learning from human feedback to train our models with two new additions to help human raters judge agent behaviour. First, to make our agent more helpful and harmless, we break down the requirements for good dialogue into natural language rules the agent should follow, and ask raters about each rule separately. We demonstrate that this breakdown enables us to collect more targeted human judgements of agent behaviour and allows for more efficient rule-conditional reward models. Second, our agent provides evidence from sources supporting factual claims when collecting preference judgements over model statements. For factual questions, evidence provided by Sparrow supports the sampled response 78% of the time. Sparrow is preferred more often than baselines while being more resilient to adversarial probing by humans, violating our rules only 8% of the time when probed. Finally, we conduct extensive analyses showing that though our model learns to follow our rules it can exhibit distributional biases.
OpenSpiel: A Framework for Reinforcement Learning in Games
Oct 10, 2019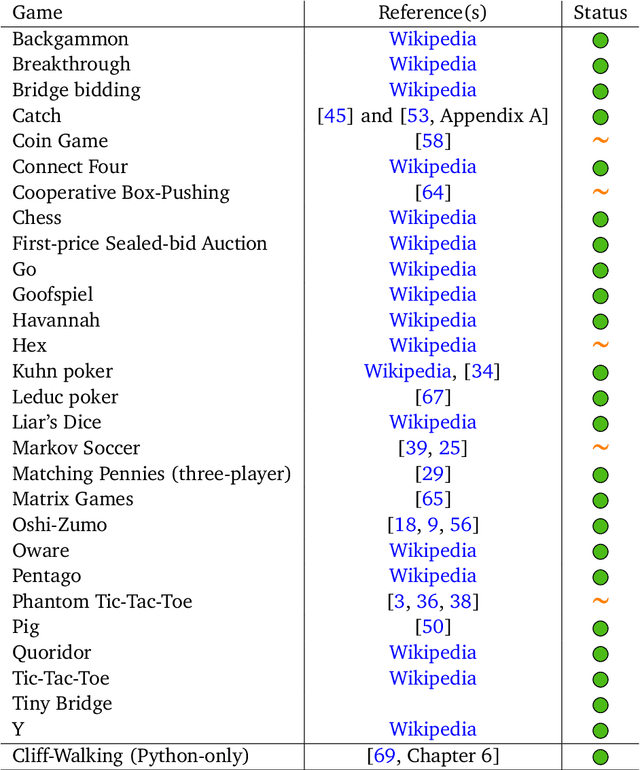
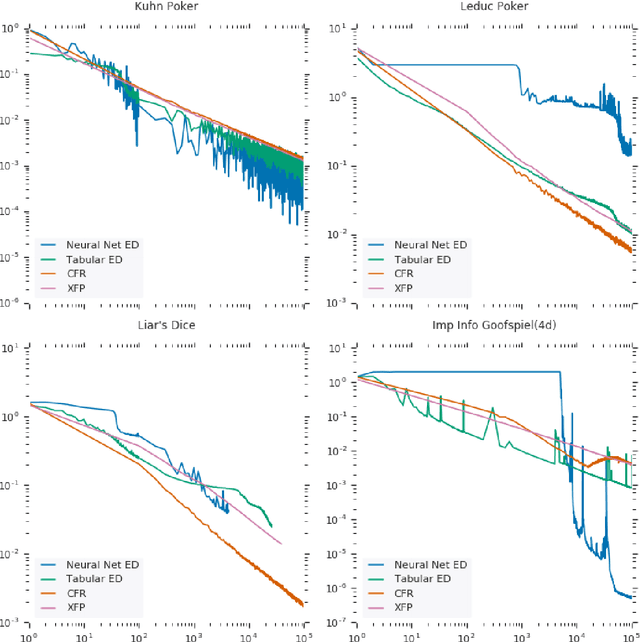
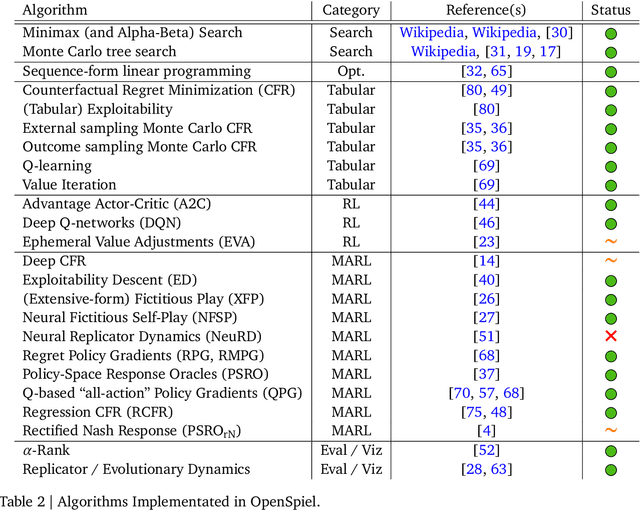
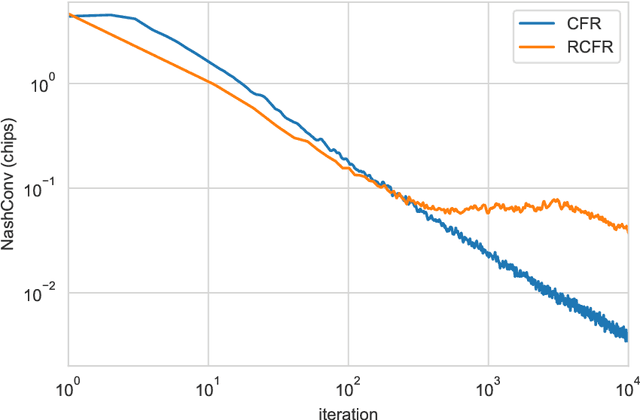
OpenSpiel is a collection of environments and algorithms for research in general reinforcement learning and search/planning in games. OpenSpiel supports n-player (single- and multi- agent) zero-sum, cooperative and general-sum, one-shot and sequential, strictly turn-taking and simultaneous-move, perfect and imperfect information games, as well as traditional multiagent environments such as (partially- and fully- observable) grid worlds and social dilemmas. OpenSpiel also includes tools to analyze learning dynamics and other common evaluation metrics. This document serves both as an overview of the code base and an introduction to the terminology, core concepts, and algorithms across the fields of reinforcement learning, computational game theory, and search.
StarCraft II: A New Challenge for Reinforcement Learning
Aug 16, 2017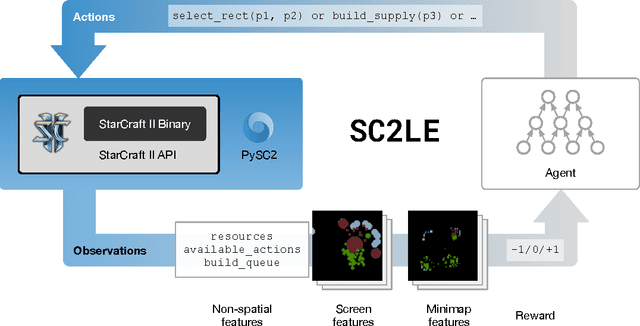
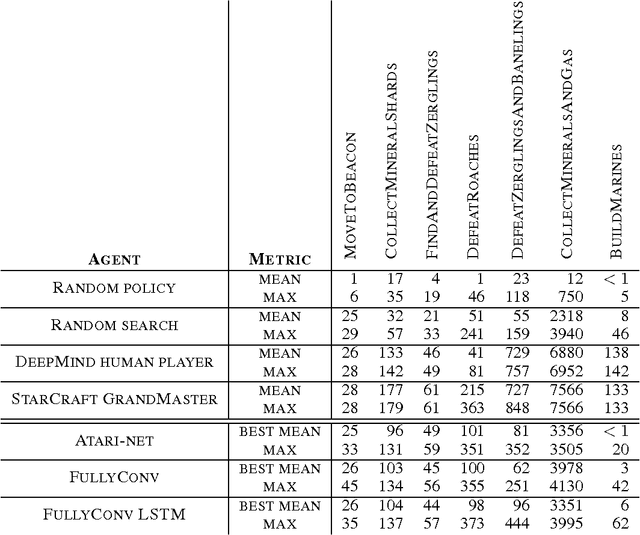

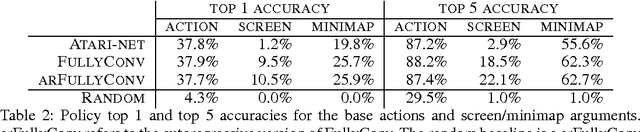
This paper introduces SC2LE (StarCraft II Learning Environment), a reinforcement learning environment based on the StarCraft II game. This domain poses a new grand challenge for reinforcement learning, representing a more difficult class of problems than considered in most prior work. It is a multi-agent problem with multiple players interacting; there is imperfect information due to a partially observed map; it has a large action space involving the selection and control of hundreds of units; it has a large state space that must be observed solely from raw input feature planes; and it has delayed credit assignment requiring long-term strategies over thousands of steps. We describe the observation, action, and reward specification for the StarCraft II domain and provide an open source Python-based interface for communicating with the game engine. In addition to the main game maps, we provide a suite of mini-games focusing on different elements of StarCraft II gameplay. For the main game maps, we also provide an accompanying dataset of game replay data from human expert players. We give initial baseline results for neural networks trained from this data to predict game outcomes and player actions. Finally, we present initial baseline results for canonical deep reinforcement learning agents applied to the StarCraft II domain. On the mini-games, these agents learn to achieve a level of play that is comparable to a novice player. However, when trained on the main game, these agents are unable to make significant progress. Thus, SC2LE offers a new and challenging environment for exploring deep reinforcement learning algorithms and architectures.