 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving alignment of dialogue agents via targeted human judgements
Sep 28, 2022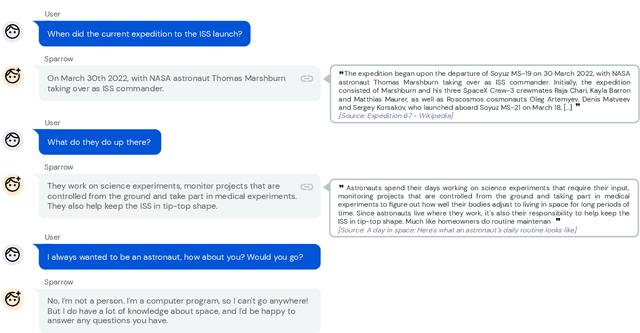

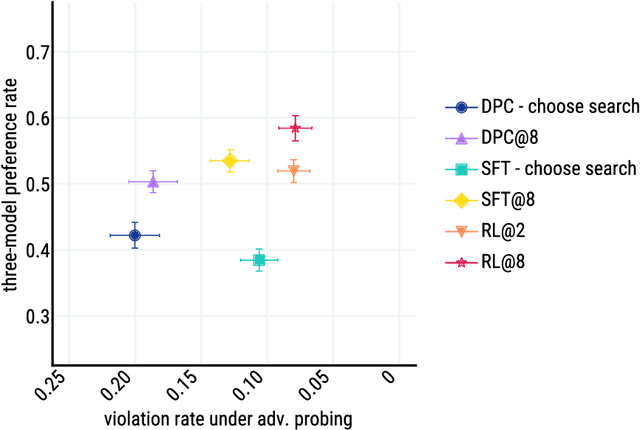
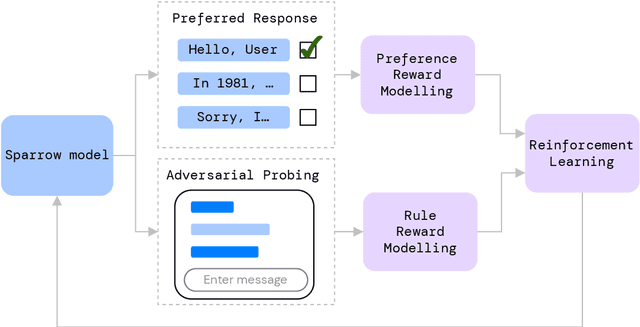
We present Sparrow, an information-seeking dialogue agent trained to be more helpful, correct, and harmless compared to prompted language model baselines. We use reinforcement learning from human feedback to train our models with two new additions to help human raters judge agent behaviour. First, to make our agent more helpful and harmless, we break down the requirements for good dialogue into natural language rules the agent should follow, and ask raters about each rule separately. We demonstrate that this breakdown enables us to collect more targeted human judgements of agent behaviour and allows for more efficient rule-conditional reward models. Second, our agent provides evidence from sources supporting factual claims when collecting preference judgements over model statements. For factual questions, evidence provided by Sparrow supports the sampled response 78% of the time. Sparrow is preferred more often than baselines while being more resilient to adversarial probing by humans, violating our rules only 8% of the time when probed. Finally, we conduct extensive analyses showing that though our model learns to follow our rules it can exhibit distributional biases.
Using ontology embeddings for structural inductive bias in gene expression data analysis
Nov 22, 2020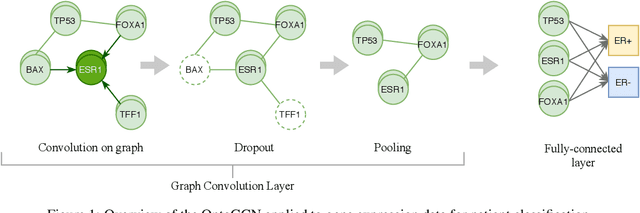

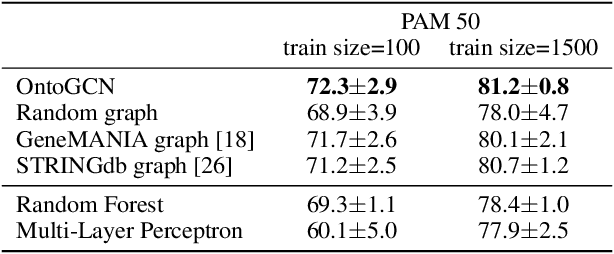
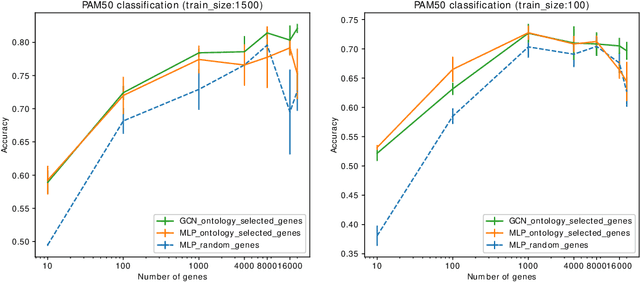
Stratifying cancer patients based on their gene expression levels allows improving diagnosis, survival analysis and treatment planning. However, such data is extremely highly dimensional as it contains expression values for over 20000 genes per patient, and the number of samples in the datasets is low. To deal with such settings, we propose to incorporate prior biological knowledge about genes from ontologies into the machine learning system for the task of patient classification given their gene expression data. We use ontology embeddings that capture the semantic similarities between the genes to direct a Graph Convolutional Network, and therefore sparsify the network connections. We show this approach provides an advantage for predicting clinical targets from high-dimensional low-sample data.