 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Improving alignment of dialogue agents via targeted human judgements
Sep 28, 2022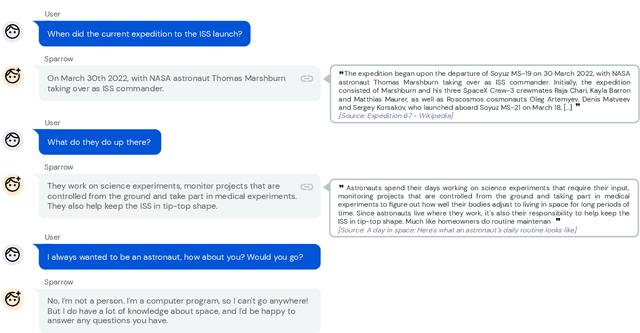

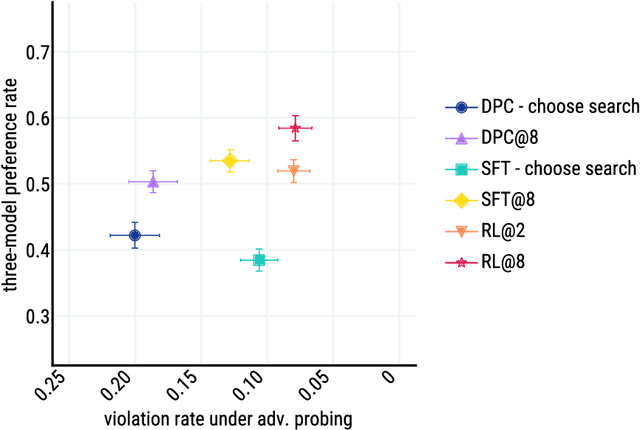
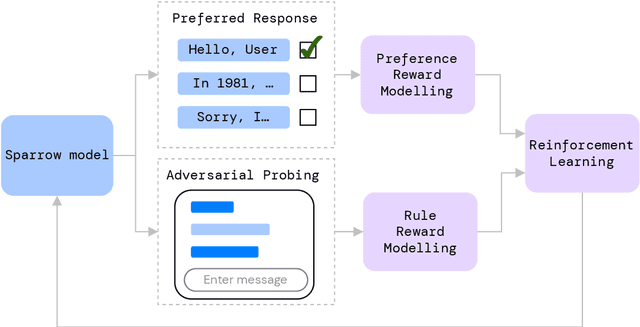
We present Sparrow, an information-seeking dialogue agent trained to be more helpful, correct, and harmless compared to prompted language model baselines. We use reinforcement learning from human feedback to train our models with two new additions to help human raters judge agent behaviour. First, to make our agent more helpful and harmless, we break down the requirements for good dialogue into natural language rules the agent should follow, and ask raters about each rule separately. We demonstrate that this breakdown enables us to collect more targeted human judgements of agent behaviour and allows for more efficient rule-conditional reward models. Second, our agent provides evidence from sources supporting factual claims when collecting preference judgements over model statements. For factual questions, evidence provided by Sparrow supports the sampled response 78% of the time. Sparrow is preferred more often than baselines while being more resilient to adversarial probing by humans, violating our rules only 8% of the time when probed. Finally, we conduct extensive analyses showing that though our model learns to follow our rules it can exhibit distributional biases.
Proving Theorems using Incremental Learning and Hindsight Experience Replay
Dec 20, 2021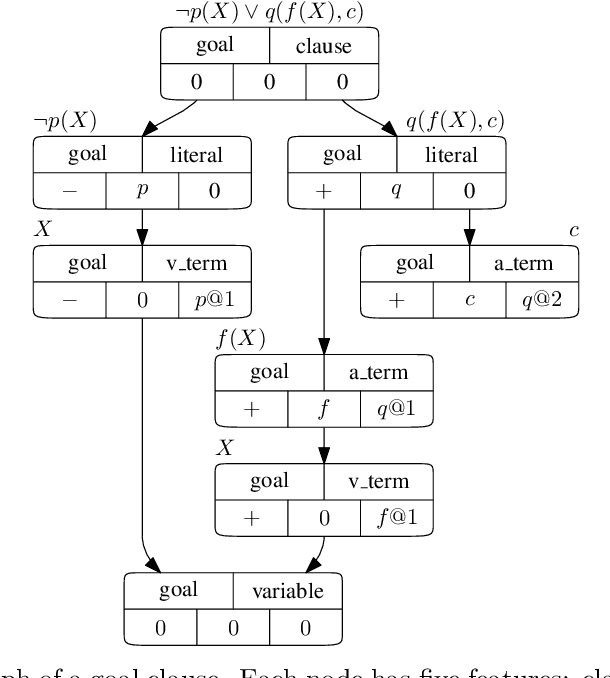
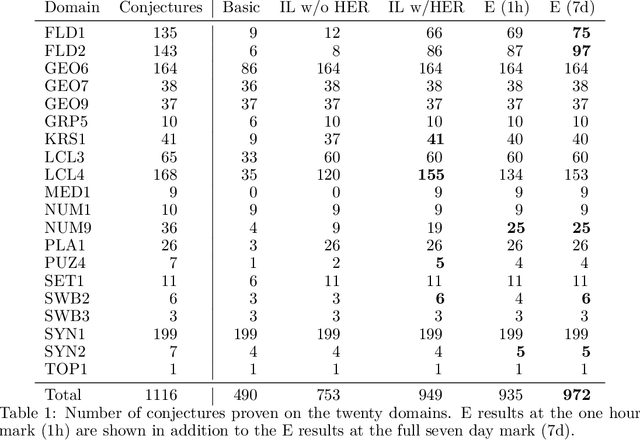
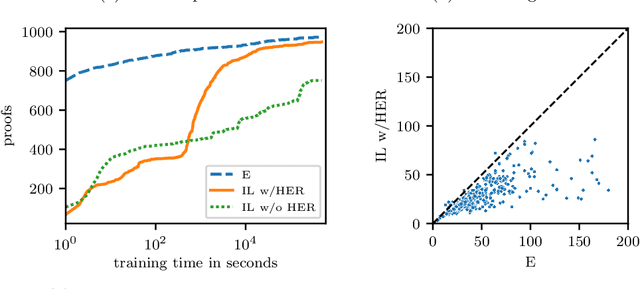
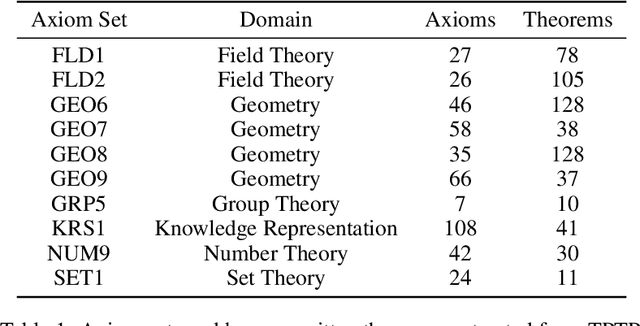
Traditional automated theorem provers for first-order logic depend on speed-optimized search and many handcrafted heuristics that are designed to work best over a wide range of domains. Machine learning approaches in literature either depend on these traditional provers to bootstrap themselves or fall short on reaching comparable performance. In this paper, we propose a general incremental learning algorithm for training domain specific provers for first-order logic without equality, based only on a basic given-clause algorithm, but using a learned clause-scoring function. Clauses are represented as graphs and presented to transformer networks with spectral features. To address the sparsity and the initial lack of training data as well as the lack of a natural curriculum, we adapt hindsight experience replay to theorem proving, so as to be able to learn even when no proof can be found. We show that provers trained this way can match and sometimes surpass state-of-the-art traditional provers on the TPTP dataset in terms of both quantity and quality of the proofs.
Training a First-Order Theorem Prover from Synthetic Data
Mar 05, 2021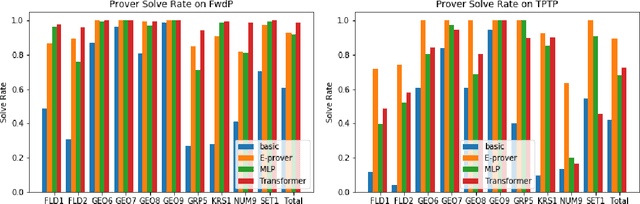
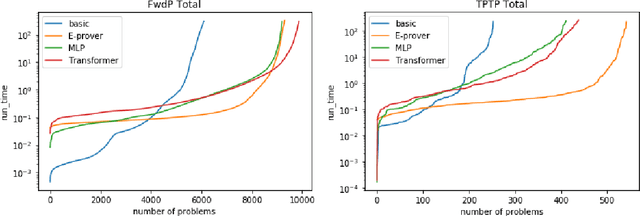
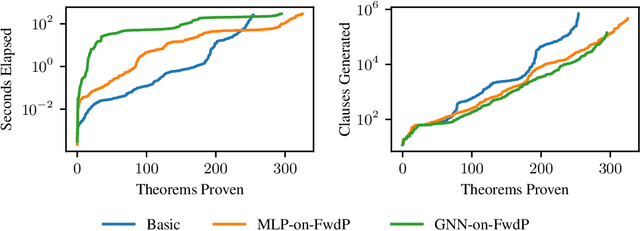
A major challenge in applying machine learning to automated theorem proving is the scarcity of training data, which is a key ingredient in training successful deep learning models. To tackle this problem, we propose an approach that relies on training purely with synthetically generated theorems, without any human data aside from axioms. We use these theorems to train a neurally-guided saturation-based prover. Our neural prover outperforms the state-of-the-art E-prover on this synthetic data in both time and search steps, and shows significant transfer to the unseen human-written theorems from the TPTP library, where it solves 72\% of first-order problems without equality.
Learning to Prove from Synthetic Theorems
Jun 19, 2020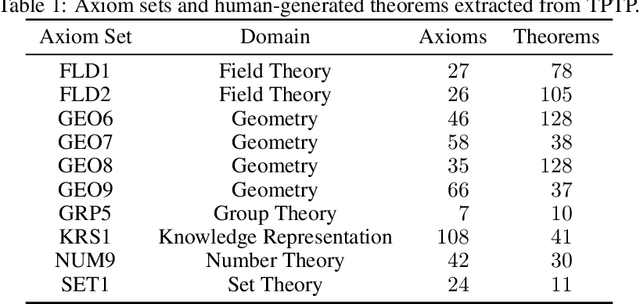
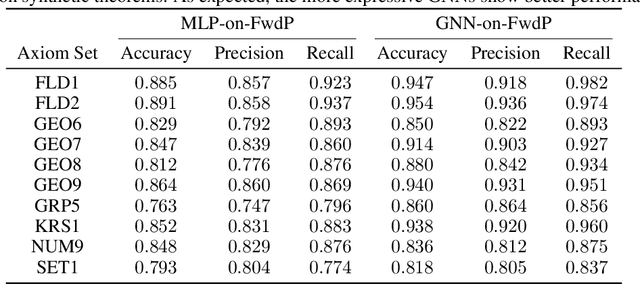
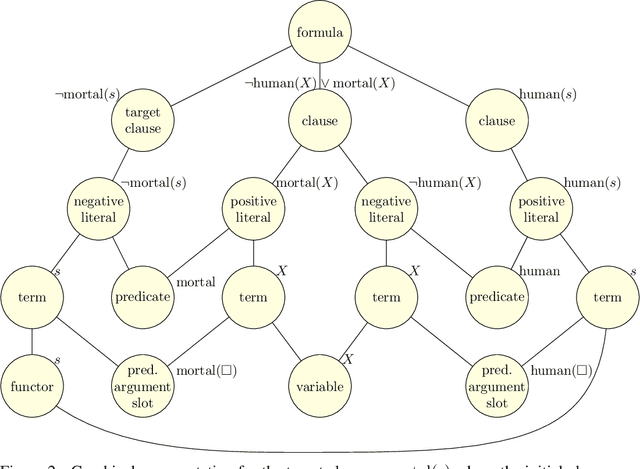
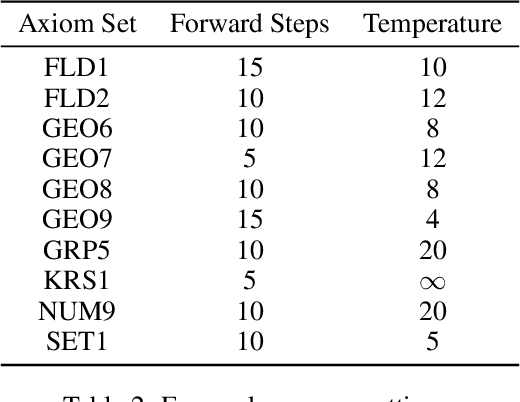
A major challenge in applying machine learning to automated theorem proving is the scarcity of training data, which is a key ingredient in training successful deep learning models. To tackle this problem, we propose an approach that relies on training with synthetic theorems, generated from a set of axioms. We show that such theorems can be used to train an automated prover and that the learned prover transfers successfully to human-generated theorems. We demonstrate that a prover trained exclusively on synthetic theorems can solve a substantial fraction of problems in TPTP, a benchmark dataset that is used to compare state-of-the-art heuristic provers. Our approach outperforms a model trained on human-generated problems in most axiom sets, thereby showing the promise of using synthetic data for this task.
Automated curricula through setter-solver interactions
Sep 27, 2019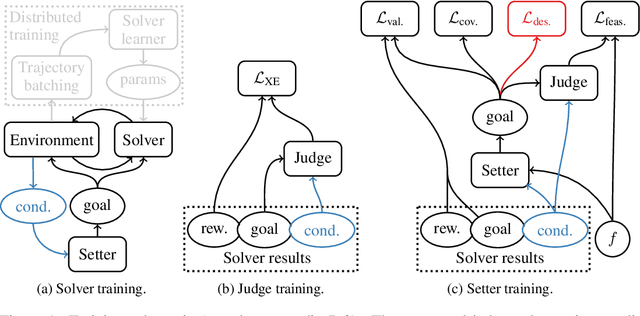

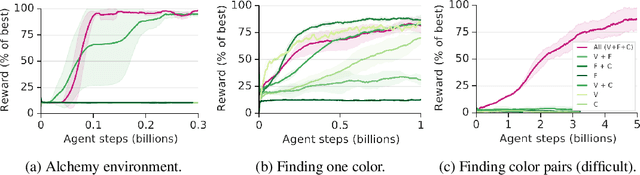
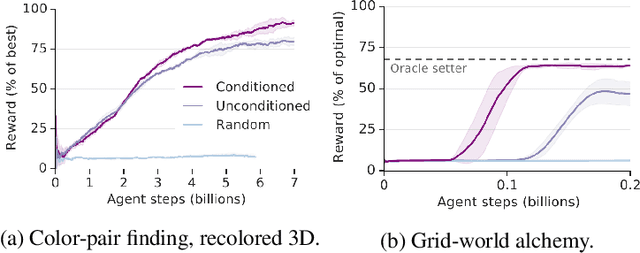
Reinforcement learning algorithms use correlations between policies and rewards to improve agent performance. But in dynamic or sparsely rewarding environments these correlations are often too small, or rewarding events are too infrequent to make learning feasible. Human education instead relies on curricula--the breakdown of tasks into simpler, static challenges with dense rewards--to build up to complex behaviors. While curricula are also useful for artificial agents, hand-crafting them is time consuming. This has lead researchers to explore automatic curriculum generation. Here we explore automatic curriculum generation in rich, dynamic environments. Using a setter-solver paradigm we show the importance of considering goal validity, goal feasibility, and goal coverage to construct useful curricula. We demonstrate the success of our approach in rich but sparsely rewarding 2D and 3D environments, where an agent is tasked to achieve a single goal selected from a set of possible goals that varies between episodes, and identify challenges for future work. Finally, we demonstrate the value of a novel technique that guides agents towards a desired goal distribution. Altogether, these results represent a substantial step towards applying automatic task curricula to learn complex, otherwise unlearnable goals, and to our knowledge are the first to demonstrate automated curriculum generation for goal-conditioned agents in environments where the possible goals vary between episodes.
At Human Speed: Deep Reinforcement Learning with Action Delay
Oct 16, 2018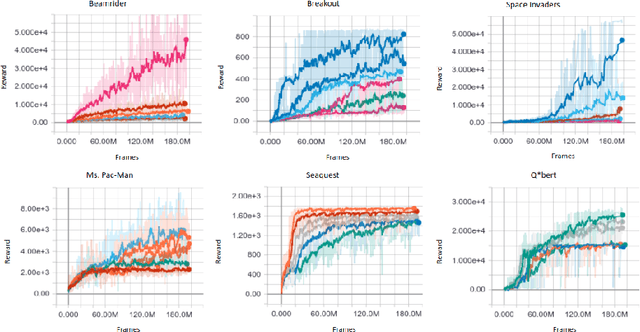

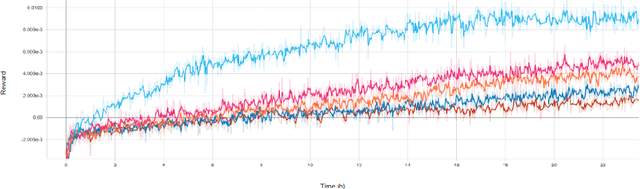
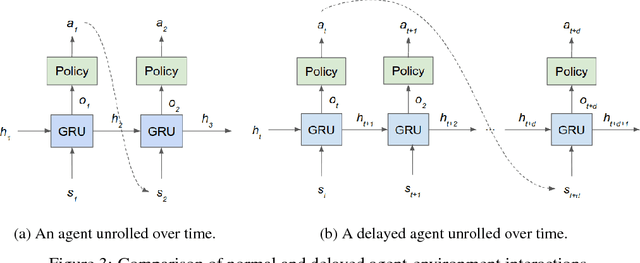
There has been a recent explosion in the capabilities of game-playing artificial intelligence. Many classes of tasks, from video games to motor control to board games, are now solvable by fairly generic algorithms, based on deep learning and reinforcement learning, that learn to play from experience with minimal prior knowledge. However, these machines often do not win through intelligence alone -- they possess vastly superior speed and precision, allowing them to act in ways a human never could. To level the playing field, we restrict the machine's reaction time to a human level, and find that standard deep reinforcement learning methods quickly drop in performance. We propose a solution to the action delay problem inspired by human perception -- to endow agents with a neural predictive model of the environment which "undoes" the delay inherent in their environment -- and demonstrate its efficacy against professional players in Super Smash Bros. Melee, a popular console fighting game.
IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures
Jun 28, 2018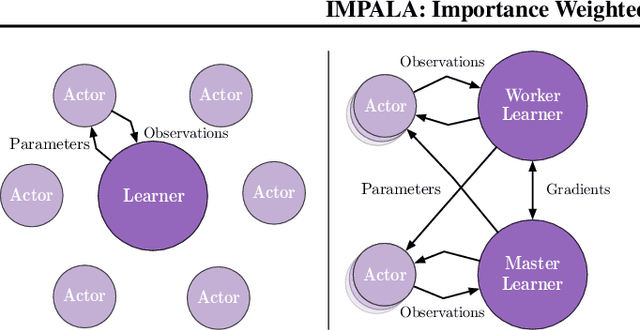
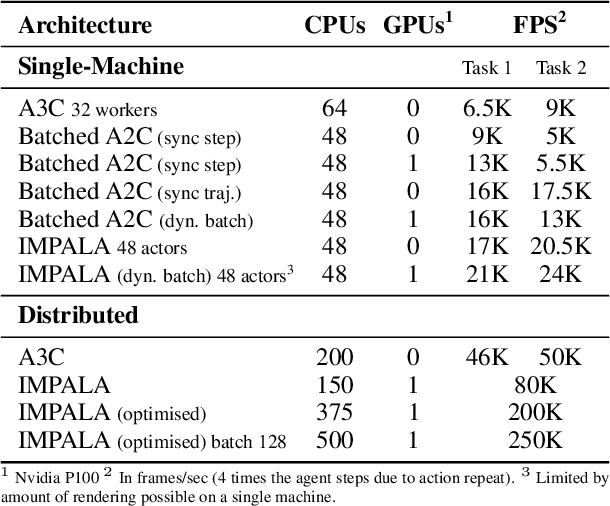
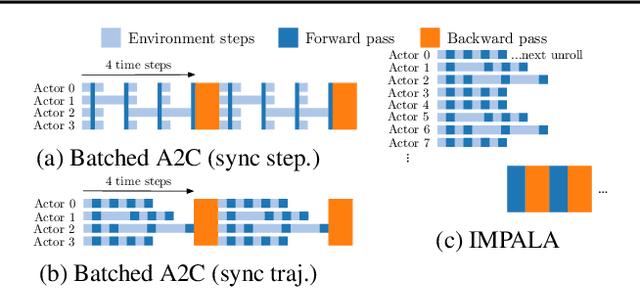
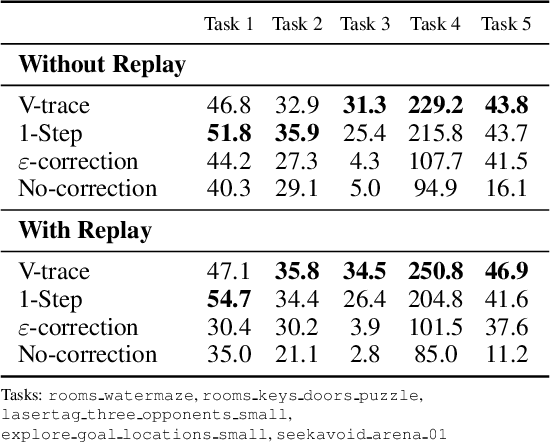
In this work we aim to solve a large collection of tasks using a single reinforcement learning agent with a single set of parameters. A key challenge is to handle the increased amount of data and extended training time. We have developed a new distributed agent IMPALA (Importance Weighted Actor-Learner Architecture) that not only uses resources more efficiently in single-machine training but also scales to thousands of machines without sacrificing data efficiency or resource utilisation. We achieve stable learning at high throughput by combining decoupled acting and learning with a novel off-policy correction method called V-trace. We demonstrate the effectiveness of IMPALA for multi-task reinforcement learning on DMLab-30 (a set of 30 tasks from the DeepMind Lab environment (Beattie et al., 2016)) and Atari-57 (all available Atari games in Arcade Learning Environment (Bellemare et al., 2013a)). Our results show that IMPALA is able to achieve better performance than previous agents with less data, and crucially exhibits positive transfer between tasks as a result of its multi-task approach.
Beating the World's Best at Super Smash Bros. with Deep Reinforcement Learning
May 08, 2017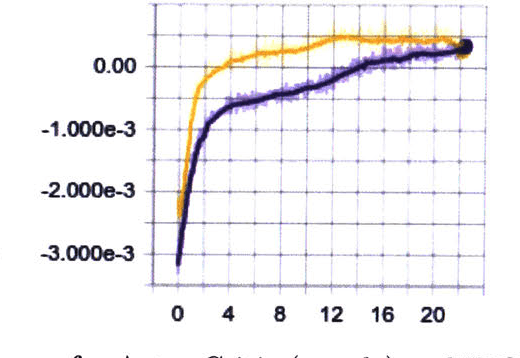
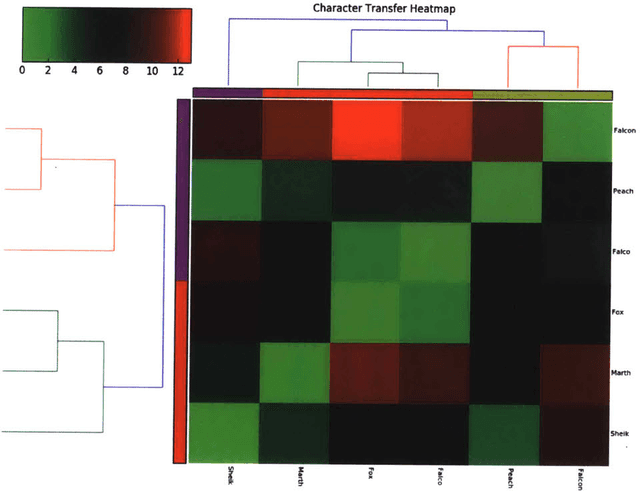
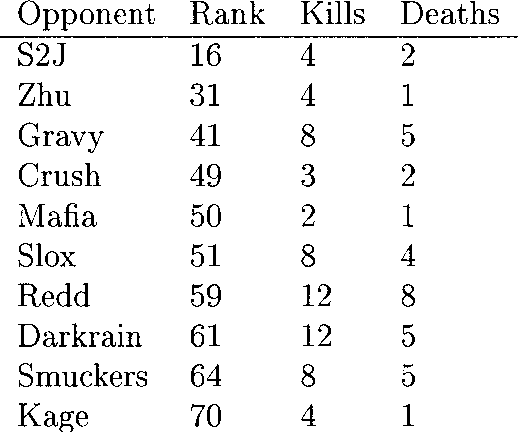

There has been a recent explosion in the capabilities of game-playing artificial intelligence. Many classes of RL tasks, from Atari games to motor control to board games, are now solvable by fairly generic algorithms, based on deep learning, that learn to play from experience with minimal knowledge of the specific domain of interest. In this work, we will investigate the performance of these methods on Super Smash Bros. Melee (SSBM), a popular console fighting game. The SSBM environment has complex dynamics and partial observability, making it challenging for human and machine alike. The multi-player aspect poses an additional challenge, as the vast majority of recent advances in RL have focused on single-agent environments. Nonetheless, we will show that it is possible to train agents that are competitive against and even surpass human professionals, a new result for the multi-player video game setting.
Automatic Inference for Inverting Software Simulators via Probabilistic Programming
May 31, 2015



Models of complex systems are often formalized as sequential software simulators: computationally intensive programs that iteratively build up probable system configurations given parameters and initial conditions. These simulators enable modelers to capture effects that are difficult to characterize analytically or summarize statistically. However, in many real-world applications, these simulations need to be inverted to match the observed data. This typically requires the custom design, derivation and implementation of sophisticated inversion algorithms. Here we give a framework for inverting a broad class of complex software simulators via probabilistic programming and automatic inference, using under 20 lines of probabilistic code. Our approach is based on a formulation of inversion as approximate inference in a simple sequential probabilistic model. We implement four inference strategies, including Metropolis-Hastings, a sequentialized Metropolis-Hastings scheme, and a particle Markov chain Monte Carlo scheme, requiring 4 or fewer lines of probabilistic code each. We demonstrate our framework by applying it to invert a real geological software simulator from the oil and gas industry.