 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Unity to Help Solve Intelligence
Nov 18, 2020
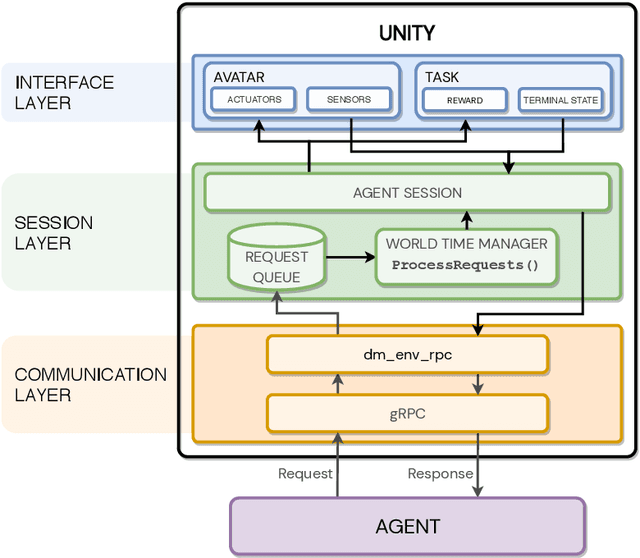

In the pursuit of artificial general intelligence, our most significant measurement of progress is an agent's ability to achieve goals in a wide range of environments. Existing platforms for constructing such environments are typically constrained by the technologies they are founded on, and are therefore only able to provide a subset of scenarios necessary to evaluate progress. To overcome these shortcomings, we present our use of Unity, a widely recognized and comprehensive game engine, to create more diverse, complex, virtual simulations. We describe the concepts and components developed to simplify the authoring of these environments, intended for use predominantly in the field of reinforcement learning. We also introduce a practical approach to packaging and re-distributing environments in a way that attempts to improve the robustness and reproducibility of experiment results. To illustrate the versatility of our use of Unity compared to other solutions, we highlight environments already created using our approach from published papers. We hope that others can draw inspiration from how we adapted Unity to our needs, and anticipate increasingly varied and complex environments to emerge from our approach as familiarity grows.
IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures
Jun 28, 2018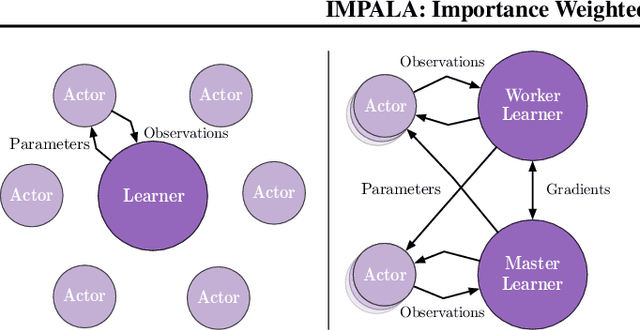
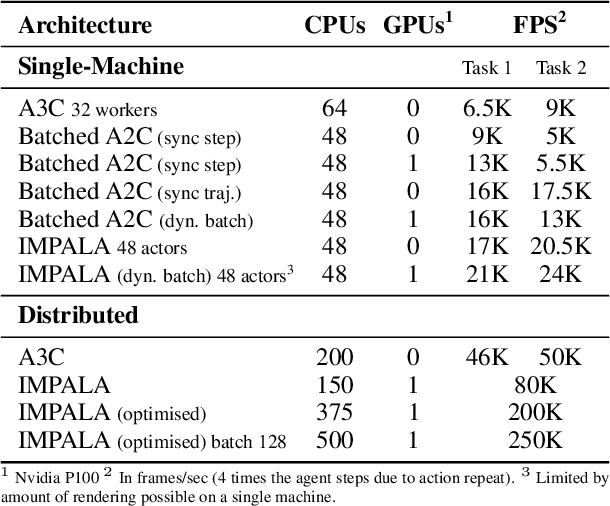
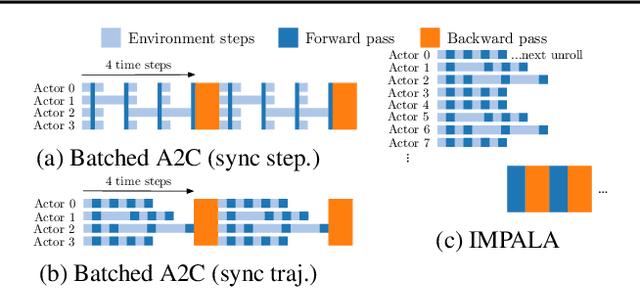
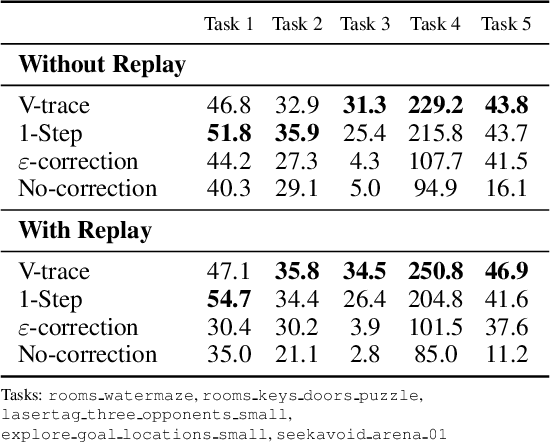
In this work we aim to solve a large collection of tasks using a single reinforcement learning agent with a single set of parameters. A key challenge is to handle the increased amount of data and extended training time. We have developed a new distributed agent IMPALA (Importance Weighted Actor-Learner Architecture) that not only uses resources more efficiently in single-machine training but also scales to thousands of machines without sacrificing data efficiency or resource utilisation. We achieve stable learning at high throughput by combining decoupled acting and learning with a novel off-policy correction method called V-trace. We demonstrate the effectiveness of IMPALA for multi-task reinforcement learning on DMLab-30 (a set of 30 tasks from the DeepMind Lab environment (Beattie et al., 2016)) and Atari-57 (all available Atari games in Arcade Learning Environment (Bellemare et al., 2013a)). Our results show that IMPALA is able to achieve better performance than previous agents with less data, and crucially exhibits positive transfer between tasks as a result of its multi-task approach.
DeepMind Lab
Dec 13, 2016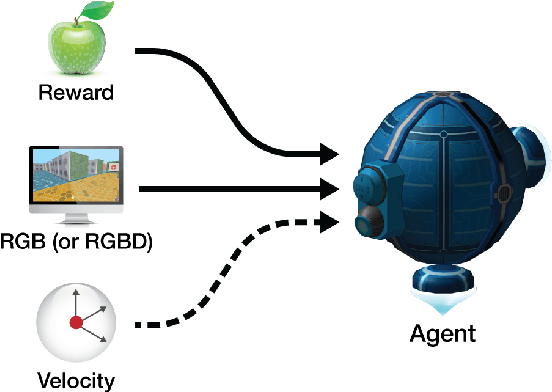
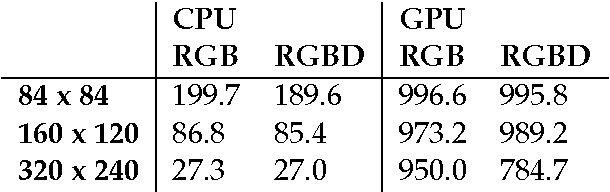
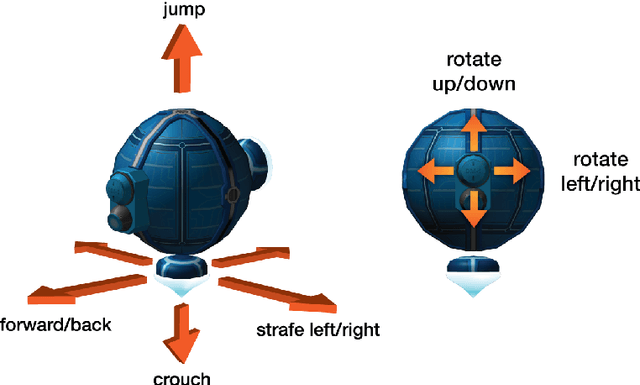

DeepMind Lab is a first-person 3D game platform designed for research and development of general artificial intelligence and machine learning systems. DeepMind Lab can be used to study how autonomous artificial agents may learn complex tasks in large, partially observed, and visually diverse worlds. DeepMind Lab has a simple and flexible API enabling creative task-designs and novel AI-designs to be explored and quickly iterated upon. It is powered by a fast and widely recognised game engine, and tailored for effective use by the research community.